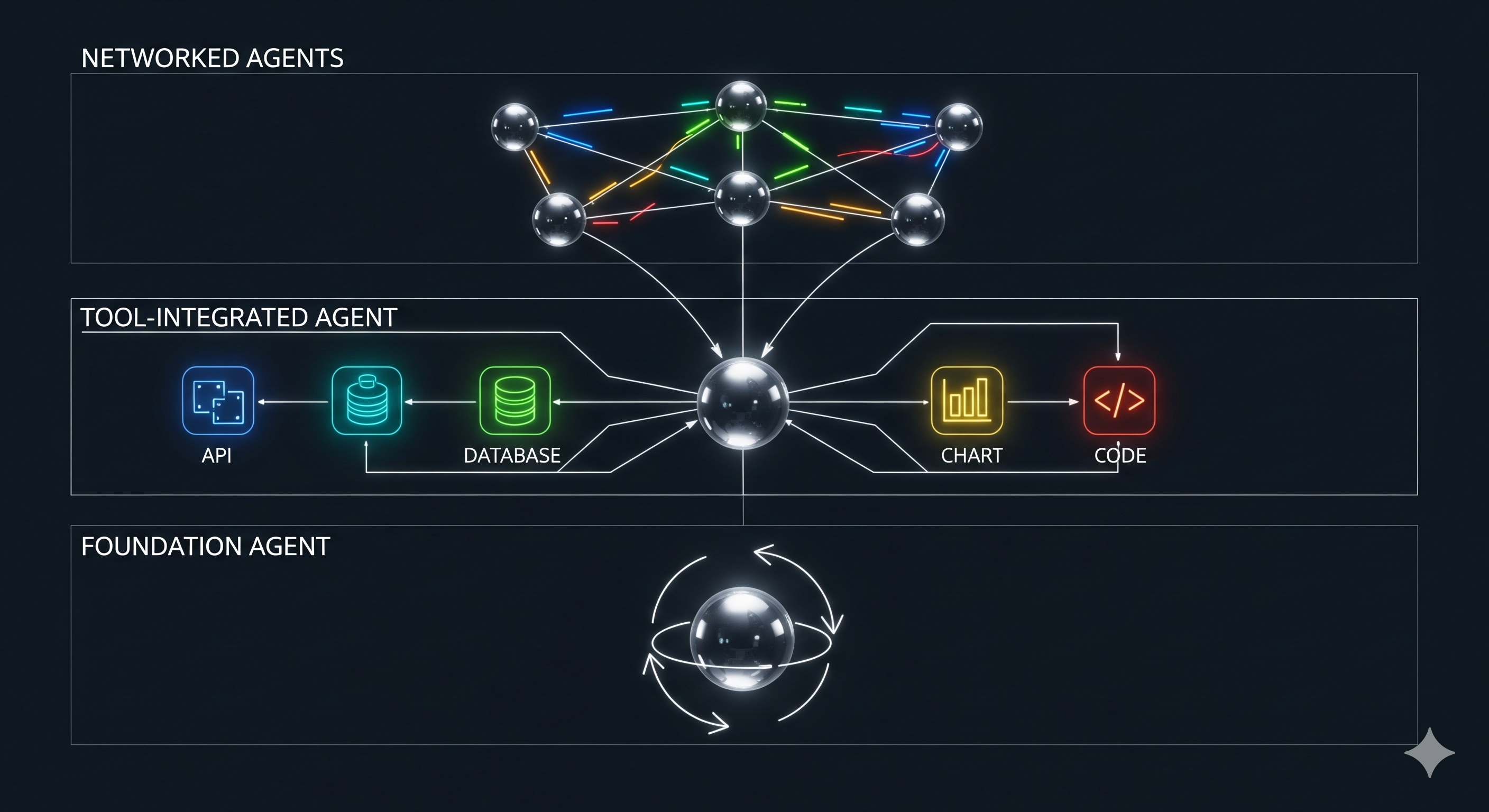
Most “agent” decks promise autonomy; few explain how to make it shippable. A new survey of LLM‑based agentic reasoning frameworks cuts through the noise with a three‑layer taxonomy—single‑agent methods, tool‑based methods, and multi‑agent methods. Below, we translate that map into a practical build/run playbook for teams deploying AI automation in real workflows.
TL;DR
- Single‑agent = shape the model’s thinking loop (roles, task prompts, reflection, iterative refinement).
- Tool‑based = widen the model’s action space (APIs, plugins/RAG, middleware; plus selection and orchestration patterns: sequential, parallel, iterative).
- Multi‑agent = scale division of labor (centralized, decentralized, or hierarchical; with cooperation, competition, negotiation).
- Treat these as orthogonal dials you tune per use‑case; don’t jump to multi‑agent if a reflective single agent with a code‑interpreter suffices.
1) What’s genuinely new (and useful) here
Most prior surveys were model‑centric (how to finetune or RLHF your way to better agents). This survey is framework‑centric: it formalizes the reasoning process—context $C$, action space $A = {a_{reason}, a_{tool}, a_{reflect}}$, termination $Q$—and shows where each method plugs into the loop. That formalism matters for operators: it’s the difference between “let’s try AutoGen” and “we know which knob to turn when the agent stalls, loops, or hallucinates.”
Operator takeaway: debugging agents becomes a control‑point exercise:
- If outputs wander → tighten task description and termination.
- If the agent is capable but ignorant → add tool integration (RAG, code runner) before changing models.
- If latency is painful → swap sequential tool chains to parallel calls; add a middleware fan‑out.
2) A builder’s checklist by layer
A. Single‑agent (shape the loop before adding people or tools)
- Role + environment prompts: constrain tone, authority, and permitted actions.
- Task schemas: explicit inputs/outputs, constraints, acceptance criteria.
- Reflection memory: store why decisions were made; summarize reasoning after each step.
- Iterative optimization: make $Q$ concrete—stop when output satisfies S (a test, a spec, or a linter report).
When it’s enough: customer‑support macros, contract clause extraction, code fixes with a local interpreter, sales email drafting with PII redaction.
B. Tool‑based (expand what the agent can actually do)
-
Integration patterns:
- API (search, calendar, CRM, order systems)
- Plugin (embedded vector DB/RAG, charts/EDA, code exec)
- Middleware (normalize auth, schemas, retries; policy enforcement)
-
Selection strategies: zero‑shot (natural‑language tool specs), rules (PDL/skills graph), or learned (reflect on success/failure pairs).
-
Utilization patterns:
- Sequential (easy to debug; brittle)
- Parallel (low latency; needs aggregation logic)
- Iterative (tight inner loop for tools like a code runner)
When it’s enough: finance report assembly from 5 systems, marketing brief generation with asset fetch, internal Q&A with citations + spreadsheet math.
C. Multi‑agent (divide & conquer—only if the work demands it)
-
Organize:
- Centralized (one planner orchestrates specialists)
- Decentralized (peer debate/voting; robust, slower)
- Hierarchical (PM → engineers → reviewers; mirrors org charts)
-
Interact: cooperate (shared KPI), compete (debate/adversarial review), negotiate (trade‑offs under constraints).
When it’s warranted: full software tickets (spec → code → tests → docs), literature surveys with cross‑checking, procurement workflows with vendor negotiation.
3) Decision table: pick the minimum system that works
| Business need | Failure you’re seeing | Minimal fix | Why this first |
|---|---|---|---|
| Answers drift or waffle | Long, unfocused outputs | Single‑agent: tighten role + task schema; add acceptance tests as S | Re‑anchors behavior without infra |
| Correct but incomplete | Misses data from other systems | Tool‑based: add API/RAG; sequential chain | Expand knowledge before adding agents |
| Too slow | Sequential calls stack up | Tool‑based: parallelize via middleware | 10–40% latency wins are common |
| Inconsistent judgments | One agent second‑guesses itself | Multi‑agent: debate or reviewer role | Adversarial checks raise floor |
| Complex, multi‑skill task | Planner gets lost | Multi‑agent: centralized or hierarchical | Explicit decomposition + ownership |
4) Evaluation: measure the loop, not just the answer
Static QA scores aren’t enough. Evaluate process health:
- Plan quality: steps are complete, valid, non‑redundant.
- Tool success rate: % of calls that return usable results.
- Iteration efficiency: edits‑to‑success, loop length, early‑exit correctness.
- Cost/latency budget: tokens, external API spend, wall‑time.
- Safety/traceability: citations present, PII masked, policy checks passed.
Pro tip: Log the tuple (context, action, output, reflection) at every step. Most failures are visible in the control points, not the final text.
5) Governance patterns that actually work
- Guardrails at middleware: enforce auth scopes, redact PII, block unsafe tool actions.
- Deterministic end‑conditions: transform $Q$ into machine‑checkable tests.
- Replayable runs: persist artifacts (retrieved docs, code diffs, API responses) for audit.
- Human‑in‑the‑loop gates: insert sign‑offs before irreversible actions (payments, contract sends).
6) Case pattern library (how we’d ship it)
Software ticket autopilot (internal dev tools)
- Shape: Hierarchical multi‑agent (PM → coder → tester → doc writer)
- Tools: repo access, code runner, unit‑test harness, issue tracker API
- Stop rule: tests green + diff under size limits + style linter = pass
Finance ops pack (SMB back‑office)
- Shape: Single‑agent + tools (ERP/CRM/Sheets) with parallel fetch + reconciliation
- Stop rule: 100% doc coverage, unmatched line items < 0.5%, audit log complete
Research digests (Cognaptus Insights pipeline)
- Shape: Central planner + specialist readers; debate for consensus summary
- Tools: RAG over PDFs, web search, citation checker; chart plugin
- Stop rule: all claims cited; table/chart validated; token & latency caps respected
7) What this means for buyers vs. builders
- Buy if your needs map to a common pattern where vendors already solved middleware and evaluation (e.g., AI support desk, AI doc search).
- Build if you differentiate on workflows, data, or compliance. Your moat is the evaluation + middleware you harden, not the LLM choice.
8) Our take
Agentic AI isn’t a magic jump to autonomy; it’s a set of tunable control loops. Start with a reflective single agent, add tools as needed, and escalate to multi‑agent only when the work truly requires specialized roles. The survey’s formalism gives operators a shared language to debug and govern these systems. Use it.
Cognaptus: Automate the Present, Incubate the Future