Thesis: AgentScope 1.0 is less a toolkit and more a discipline for agentic software. By pinning everything to ReAct loops, unifying “message–model–memory–tool,” and adding group-wise tool provisioning, it addresses the real failure mode of agents in production: tool sprawl without control. The evaluation/Studio/runtime trio then turns prototypes into shippable services.
What’s actually new (and why it matters)
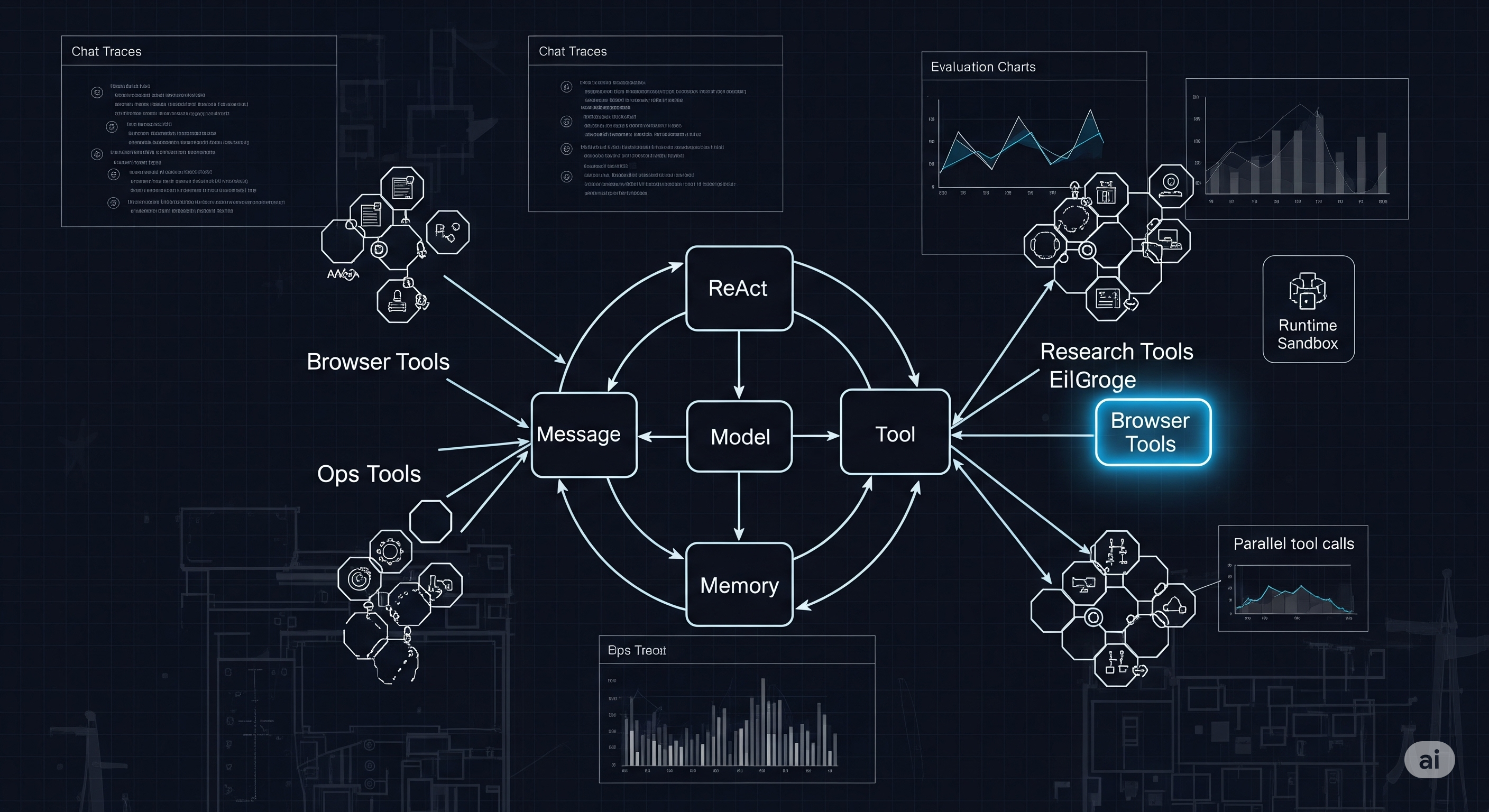
1) A crisp core: Message → Model → Memory → Tool
Most frameworks blur these into ad‑hoc objects; AgentScope forces a clean, composable boundary:
- Message as the single multimodal currency (text, images, tool call/result, even “thinking” blocks), with IDs/timestamps for traceability.
- Model behind a unified chat interface (providers swapped via formatters and a common response schema), plus token usage hooks for cost/latency tracking.
- Memory split into short‑term dialogue traces and long‑term, pluggable stores (e.g., Mem0), each with developer‑controlled and agent‑controlled read/write methods.
- Tooling standardized to JSON schemas with a Toolkit that registers, executes (sync/async/streaming), and groups tools—importantly with graceful interruption handling.
Implication: Product teams can scale features without letting each new capability leak bespoke data types into the agent loop. It’s the difference between an agent that grows, and a ball of string that tangles.
2) ReAct as the contract, not a vibe
AgentScope anchors agent behavior in a ReAct loop—plan → act (tools) → observe → iterate—then upgrades it with:
- Parallel tool calls (I/O waits no longer serialize the step).
- Real‑time steering (user interrupts pause and redirect the loop cleanly).
- Dynamic tool provisioning via group-wise activation so the agent only “sees” what’s relevant in the current phase.
Implication: You cut latency and reduce error propensity from “too many tools in context.” It’s a principled fix for the notorious “function‑calling roulette.”
3) Developer ergonomics beyond Hello World
AgentScope ships with:
- Studio: a chat-style trace viewer that pairs spans (LLM/tool invocations) with the exact dialogue turn—great for root-cause on long trajectories.
- Evaluation: tasks/metrics/benchmarks with sequential or Ray‑distributed execution and durable result storage.
- Runtime: a deployable engine + sandbox (FastAPI service, protocol adapters like A2A, and isolated environments for safe tool execution).
Implication: Instead of stitching Langfuse + custom eval scripts + ad‑hoc sandboxes, you can keep observability, scoring, and deployment in one path.
A 30‑second mental model
| Layer | AgentScope construct | What it buys you | What to watch out for |
|---|---|---|---|
| Cognition | ReAct loop (reply/observe/interrupt) | Deterministic control points for tool use and recovery | Don’t overfit prompts; lean on hooks & state persistence |
| Capabilities | Toolkit + group-wise tool sets | Smaller search space → fewer tool misfires; dynamic phase switching | Requires a bit of upfront taxonomy work |
| Interfaces | Message / Model / Memory | Interop across providers; auditability | Mapping your legacy types to Msg blocks |
| Operability | Studio / Evaluation / Runtime | Debug, measure, and ship from the same stack | Still early maturity for complex enterprise workflows |
Where it shines for real products
-
Multi‑stage tasks (research → build → report): Start with a “web‑research” tool group (search, scrape, summarize), then switch to “code‑ops” (shell, file ops) and finally “reporting” (format/plot). The agent narrows options at each stage.
-
Latency‑sensitive I/O: Fan‑out parallel API calls in one reasoning step (pricing feeds, KYC checks, quote books), then aggregate into a single observation. Practical win on p95 time-to-answer.
-
Compliance/ops: With Studio+Eval you can store full trajectories, compute pass/fail on red‑flag prompts, and promote only passing versions to Runtime.
How we’d adopt this at Cognaptus
We already run an R‑first trading stack (agentr/strategyr/tradesimr). AgentScope is Python, but the architectural moves port cleanly.
- Define tool groups in our orchestrator:
market_data,order_exec,risk_ops,news_research. Only one group active per phase. - Swap our ad‑hoc messages for a normalized event schema (mirroring
Msg): include tool calls/results and attach timestamps/ids for replay. - Parallelize tool use inside a single step: e.g., quote snapshots across venues + funding rates + order book imbalance, then a single reasoning update.
- Long‑term memory: persist agent‑controlled notes like “venue X unreliable at 02:00–03:00 UTC” and developer‑controlled run summaries for evaluation.
- Studio-equivalent traces: bind our existing OpenTelemetry spans to each dialogue turn so trading post‑mortems line up with chain-of-thought (where available) and tool I/O.
Quick win: start with group-wise tools and interrupt handling. Those two alone shrink both cost and weird failures in long‑running agents.
Sharp edges & open questions
- Tool taxonomy drift: Grouping tools is powerful, but teams need ownership and versioning (what’s in the “browser” group this week?).
- Memory governance: Agent‑controlled writes are great—until they ossify bad heuristics. Schedule periodic memory audits.
- Eval representativeness: The eval module helps, but benchmark design remains human work; business KPIs must map to metrics (latency, accuracy, risk breaches, user friction).
Bottom line
AgentScope 1.0 is an opinionated, production‑minded shape for agent systems: ReAct at the core, tools in disciplined groups, and ops built‑in. Even if you never import the library, the design patterns are worth copying. If you do adopt it, start with tool grouping and Studio—then layer in Runtime only when your agent earns it.
Cognaptus: Automate the Present, Incubate the Future