TL;DR
Most demos of “LLM introspection” are actually vibe checks on outputs, not privileged access to internal state. If a third party with the same budget can do as well as the model “looking inward,” that’s not introspection—it’s ordinary evaluation. Two quick experiments show temperature self‑reports flip with trivial prompt changes and offer no edge over across‑model prediction. The bar for introspection should be higher, and business users should demand it.
The Core Claim
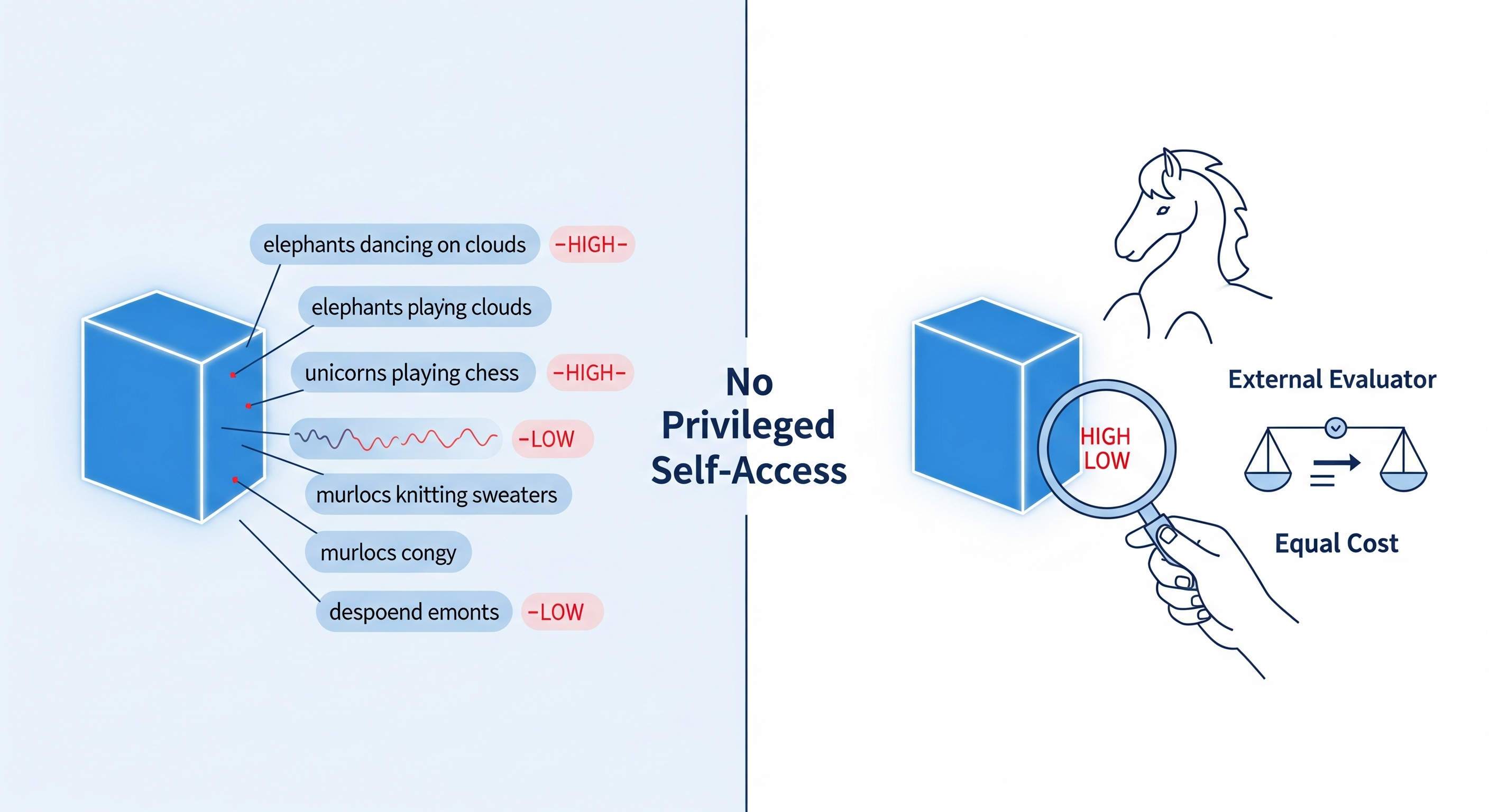
The paper we examine proposes a thicker standard: an AI is introspecting when it retrieves information about its own internal state via a process that is more reliable than any equal‑or‑cheaper method available to a third party. In plainer terms: if an external auditor can match the model’s self‑report without special access, there’s no privileged self‑access—so, no introspection.
Why this matters for operators and buyers:
- It separates marketing demos from trust‑relevant capability.
- It reframes “self‑explanations” as claims with measurable advantage (or not) over external diagnostics.
- It suggests a concrete procurement test: Show me a self‑report that beats my cheap baseline.
What the Experiments Actually Show
Recent hype leaned on a temperature‑guessing trick: have a model write a sentence, then ask it whether the sampling temperature was high or low. If its description lines up with the setting, voilà—introspection. This paper stresses two probes that puncture that optimism:
-
Style Confounds: Ask for a crazy sentence and the model declares “HIGH”; ask for a factual sentence and it declares “LOW,” even when the true temperature is held constant. Swapping topics (elephants → unicorns → murlocs) nudges judgments too. In other words, the self‑report is tracking surface style and topic familiarity, not privileged access.
-
No Self‑Access Edge: When you compare three conditions—
- Self‑reflection (generator judges its own temperature),
- Within‑model prediction (same model predicts from text), and
- Across‑model prediction (another model predicts from text), accuracy is ~coin‑flip across the board. The self has no advantage over a peer.
Lightweight vs. Privileged Introspection
Here’s a one‑page guide your team can use when product claims pop up:
| Criterion | Lightweight “introspection” | Privileged self‑access (thicker) |
|---|---|---|
| What’s measured? | Report that correlates with an internal variable (e.g., “temperature seems high”). | Report beats any equal‑or‑cheaper third‑party method given the same external info. |
| What enables success? | Output patterns, style cues, topic familiarity. | Access to internal configuration or a protected signal others can’t cheaply extract. |
| Robustness to prompt framing | Often fragile; flips with instruction wording. | Should be stable against superficial framing changes. |
| Practical value for governance | Low: you could hire a simple evaluator to match it. | High: unlocks honesty, calibration, and reduced monitoring cost. |
| Example business test | “Your model’s self‑report agrees with my grader.” | “Your model’s self‑report is more accurate than my grader at the same cost.” |
Why This Reframing Matters for Business Buyers
A. It sets a falsifiable threshold. If “introspection” doesn’t beat a trivial baseline, it’s a UX illusion. Your red‑team should treat self‑reports like any other metric under cost constraints.
B. It changes your instrumentation roadmap. If you want honest self‑reports, don’t just prompt for explanations. You’ll need architectural features that expose internal state (e.g., verifiable hooks, latent probes, or monitors with signed attestations), plus training objectives that reward accurate self‑access under adversarial framing.
C. It clarifies what to pay for. Pay for capability that reduces oversight cost. A model with genuine self‑access lowers your spend on external monitors; a model that only narrates vibes does not.
How To Test Vendors (Copy/Paste Playbook)
- Define the hidden variable (e.g., temperature, tool‑use switch, retrieval source ID, safety mode).
- Blind the evaluator: give the same prompts and outputs to (i) the model’s self‑reporter and (ii) your external baseline evaluator with the same token budget.
- Randomize framing: inject neutral, factual, and zany instruction variants; vary topical familiarity.
- Score advantage: require the self‑report to show a statistically significant accuracy edge over your baseline at matched cost.
- Stress for incentives: add penalties for over‑confident wrong self‑reports; reward calibrated abstention.
If there’s no edge, classify the feature as non‑introspective and don’t price it as governance.
Implications for Builders
- Architected signals beat after‑the‑fact rationalization. If a variable matters (e.g., safety mode), surface it via a sealed internal register readable to the policy head, and regularize the model to report it honestly under distribution shift.
- Prompt‑variance is an adversary. Treat instruction style as a perturbation; evaluate self‑access under worst‑case paraphrases.
- Train for comparative advantage. Frame the objective explicitly: maximize (self‑report accuracy − competitive external evaluator accuracy) at equal budget. That aligns learning with the privileged‑access bar.
- Proof beats prose. Include an audit card: a table where the self‑report’s ROC‑AUC exceeds the matched‑budget baseline across topics and framings, plus calibration plots.
Where This Leaves the “Explainability” Narrative
Explanations are still useful for UX and debugging, but they do not constitute introspection unless they confer a measurable, cost‑aware advantage over outside evaluators. The standard to beat is not “sounds plausible,” it’s “saves me money on monitoring while improving safety.”
A Note on Positive Results Elsewhere
Some recent work suggests larger models can learn genuine self‑access with targeted finetuning and scaffolds. That’s promising for the roadmap—but the same bar applies: demonstrate advantage over a matched external evaluator. Until then, assume self‑reports are just another model output, not a privileged window.
Bottom Line
If a model’s “self‑knowledge” can be reproduced by any third party at the same price, it’s not introspection—it’s performance art. Demand privileged self‑access and make vendors prove it.
Cognaptus: Automate the Present, Incubate the Future