Most LLM agents today think in flat space. When you ask a long-term assistant a question, it either scrolls endlessly through past turns or scours an undifferentiated soup of semantic vectors to recall something relevant. This works—for now. But as tasks get longer, more nuanced, and more personal, this memory model crumbles under its own weight.
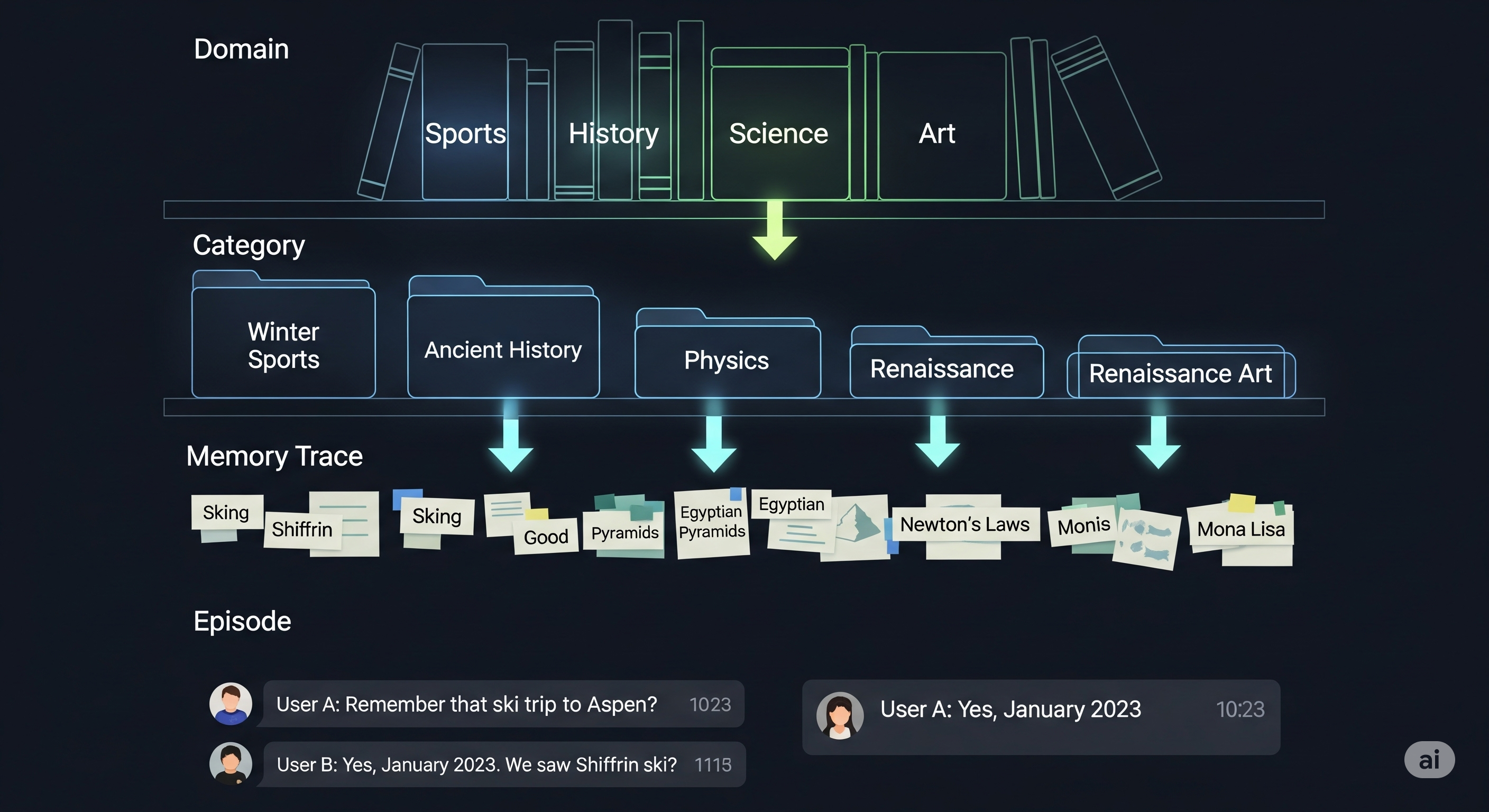
A new paper proposes an elegant solution: H-MEM, or Hierarchical Memory. Instead of treating memory as one big pile of stuff, H-MEM organizes past knowledge into four semantically structured layers: Domain, Category, Memory Trace, and Episode. It’s the difference between a junk drawer and a filing cabinet.
Why Structure Matters
Most vector-based memory systems rely on similarity search across all entries. That means more memory leads to more cost—and ironically, to worse retrieval quality due to irrelevant noise.
H-MEM solves this by mimicking how humans think:
| Layer | Description | Analogy |
|---|---|---|
| Domain | High-level area (e.g., “sports”) | Chapter |
| Category | Subdomain (e.g., “winter sports”) | Section |
| Memory Trace | Keywords (e.g., “skiing”, “Shiffrin”) | Paragraph headline |
| Episode | Full past interaction + user profile info | Paragraph content |
Each layer contains position indices that point to its sublayers. When retrieving memory, H-MEM starts from the top and filters downward. This enables index-based routing instead of brute-force similarity over millions of entries.
Less Is More (Efficient)
Assume we have 1 million memory episodes. Traditional flat memory retrieval (like MemoryBank) performs O(n·D) similarity checks over all vectors. H-MEM brings this down to O((a + k·300)·D), where a is the number of domains and k is the top entries per level. The result? Up to 5× speedup in inference and dramatically lower computational load, even as memory grows.
In real-world tests using the LoCoMo benchmark (50 dialogues × 300 turns), H-MEM consistently beat the state-of-the-art:
- +21.25 F1 on multi-hop reasoning
- +17.65 BLEU-1 on adversarial queries
- Robust even in small 1.5B models—making it practical for low-resource deployment
Feedback Matters Too
Another clever touch: H-MEM introduces a feedback-aware forgetting mechanism. If the user confirms a memory (explicitly or implicitly), it gets reinforced. If not used, it decays naturally. If rebutted, it’s actively weakened. This mirrors how humans revise beliefs and preferences over time.
In contrast, existing memory systems treat all stored knowledge as static truth—or worse, never expire it at all. H-MEM’s feedback loop adds an important layer of evolving relevance.
Still Missing a Modality
Of course, no system is perfect. H-MEM is currently limited to text-based interactions. It doesn’t yet handle images, voice, or video memory—nor does it manage memory lifecycle operations like deletion, redaction, or security in a granular way. But as a foundational architecture, its contribution is profound.
By building an internal cognitive filing system, H-MEM turns LLM agents from compulsive hoarders into methodical thinkers. That’s a step not just toward better accuracy—but toward more humanlike intelligence.
Cognaptus: Automate the Present, Incubate the Future.