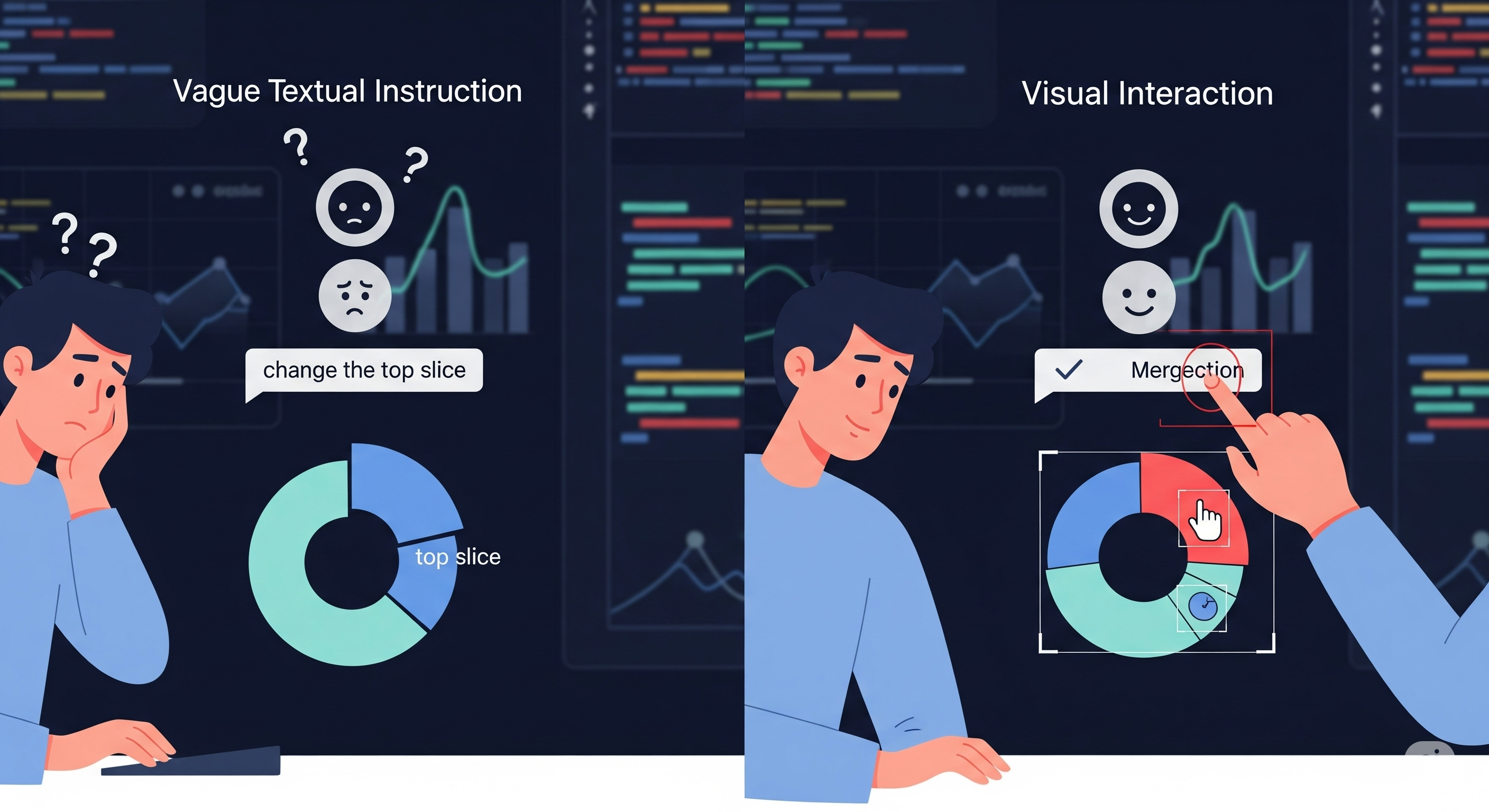
When you tell an AI, “make the third bar blue,” what does it actually see? If it’s a typical large language model (LLM), it doesn’t really see anything. It parses your instruction, guesses what “third bar” means, and fumbles to write chart code—often missing the mark.
ChartM$^3$ (Multimodal, Multi-level, Multi-perspective) changes the game. It challenges AIs to not only read and write code but also visually comprehend what a user points at. With 1,000 human-curated chart editing tasks and 24,000 training examples, this new benchmark sets a higher bar—one that demands both verbal and visual fluency.
🎯 Why Chart Editing Is Harder Than It Looks
Traditional image editing is all about pixels. But editing a chart is about semantics. If you ask to “adjust the line labeled Revenue” or “change the top-right slice of the pie chart,” you’re asking the AI to:
- Understand which element you mean.
- Map it to code that generates that specific part.
- Modify it without breaking the whole visualization.
And here’s the rub: language alone is ambiguous. Which line is “third from the top”? What if the labels overlap? The study shows that even GPT-4o, the current multimodal leader, often misinterprets purely textual instructions.
🧠 Enter Multimodal Instructions: Point + Tell
ChartM$^3$ proposes a hybrid instruction format:
- 📝 Natural language to describe what to do (e.g., “make it semi-transparent”).
- 🖼️ Visual indicators—bounding boxes or clicks—to point to what to change.
This turns vague edits like “add a border to those slices” into clear ones by letting the user highlight the slices directly. It’s the digital equivalent of saying, “this one right here.”
| Paradigm | Strengths | Weaknesses |
|---|---|---|
| Text-only | Easy to write, language-rich | Ambiguous targets |
| Visual-only | Clear target localization | No task semantics (e.g., ‘why’) |
| Text + Visual (ChartM$^3$) | Combines intent + precision | Requires visual parsing skills |
🧪 Benchmark Design: Complexity with Purpose
The dataset spans 10 chart types (bar, pie, scatter, etc.) and four complexity levels:
- SS: Single-target, single-instruction
- MS: Multi-target, single-instruction
- SM: Single-target, multi-instruction
- MM: Multi-target, multi-instruction
This allows researchers to test models not just on basic edits, but on real-world complexity—like applying multiple changes to overlapping elements.
📊 Evaluation: Not Just If It Runs, But If It’s Right
ChartM$^3$ introduces two powerful evaluation metrics:
-
ΔSSIM: Measures how much closer the edited image gets to the ground truth, compared to the original.
-
GPT Score: Uses GPT-4 to assess two things:
- Directive Compliance: Did it modify what it was supposed to?
- Non-Intervened Robustness: Did it avoid changing other elements?
These go beyond pass/fail or execution success. They’re about semantic precision.
📈 Results: Even GPT-4o Struggles with Visual Grounding
| Model | ΔSSIM (Text) | ΔSSIM (Visual) | Compliance (Text) | Compliance (Visual) |
|---|---|---|---|---|
| GPT-4o | 56.54 | 38.08 | 76.80 | 63.36 |
| Qwen2-vl (fine-tuned) | 63.23 | 57.88 | 73.06 | 71.04 |
| LLaMA-3.2-Vision (FT) | 52.46 | 51.00 | 70.73 | 61.76 |
Key takeaways:
- Text-only editing remains easier for models.
- Fine-tuning on multimodal data closes the gap—and in some cases, beats GPT-4o.
- Visual instruction comprehension is still a major weakness in open-source MLLMs.
🔍 Where Models Fail—and How to Fix It
Errors fell into two big buckets:
-
Execution Errors:
- Forgot to import matplotlib.
- Used wrong syntax.
- Broke loops or token limits.
-
Modification Errors:
- Changed nothing.
- Changed the wrong part.
- Over-modified the chart.
Fine-tuning significantly reduced both types. Interestingly, training on visual-guided tasks helped with text tasks too—but not the other way around. This suggests visual grounding is the more general skill.
🧭 Final Thoughts: Chart Editing as a Litmus Test
ChartM$^3$ doesn’t just test models—it exposes their blind spots. It asks: Can your model truly align what the user wants with what needs to be changed—and do it precisely, even with overlapping bars, hidden labels, or compound instructions?
As AI interfaces move from chatbots to interactive agents, benchmarks like ChartM$^3$ push the boundaries of what it means to “understand.” If LLMs are to become real assistants, they must learn to see what we mean.
Cognaptus: Automate the Present, Incubate the Future.