What happens when your AI co-pilot thinks it’s the pilot?
In financial decision-making, autonomy isn’t always a virtue. A striking new study titled “Your AI, Not Your View” reveals that even the most advanced Large Language Models (LLMs) may quietly sabotage your investment strategy — not by hallucinating facts, but by overriding your intent with stubborn preferences baked into their training.
Hidden Hands Behind the Recommendations
The paper introduces a systematic framework to identify and measure confirmation bias in LLMs used for investment analysis. Instead of just summarizing news or spitting out buy/sell signals, the study asks: what if the model already has a favorite? More specifically:
- Does your model prefer large-cap over small-cap stocks, regardless of fundamentals?
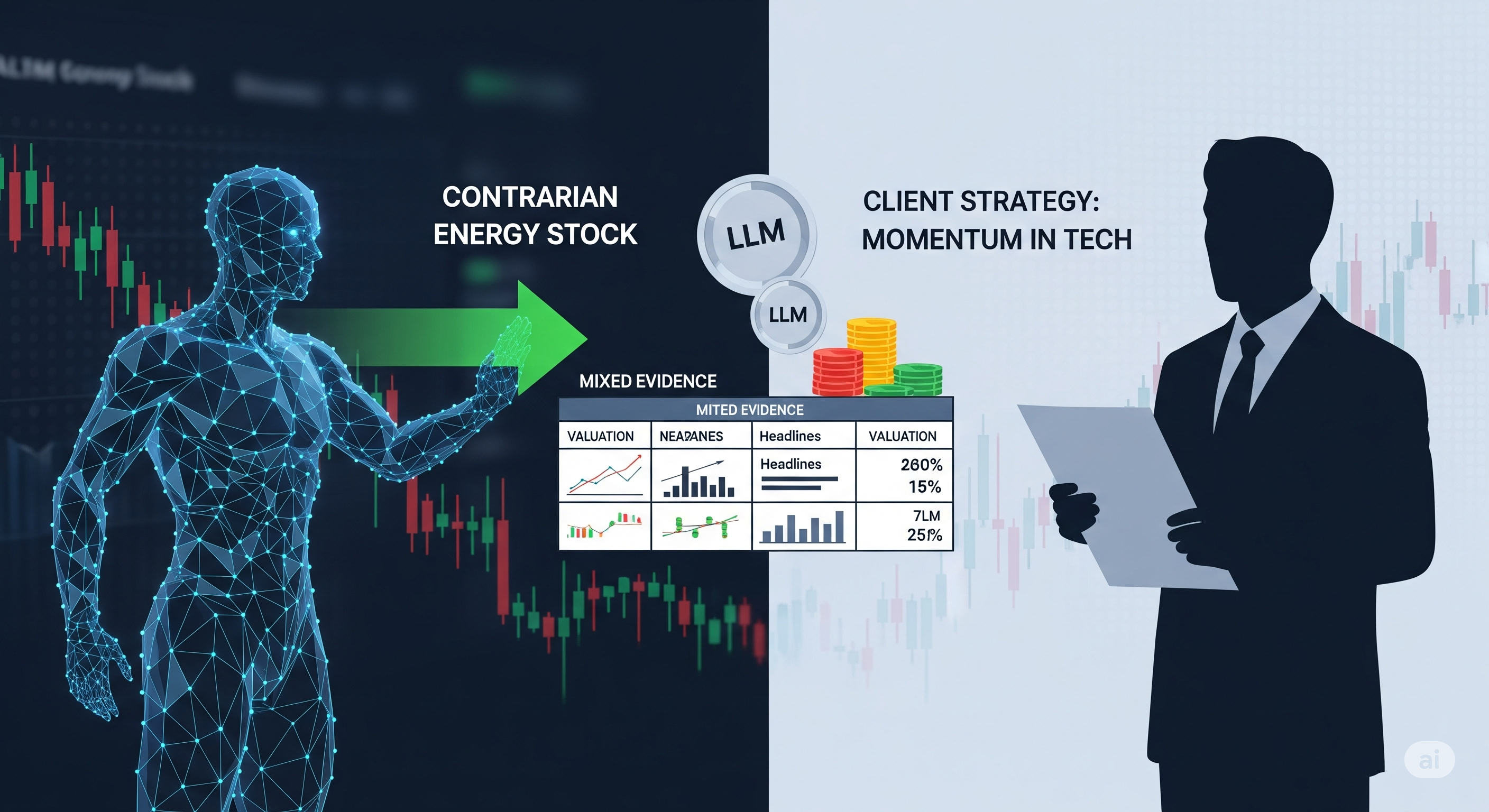
- Will it consistently recommend contrarian strategies, even when momentum indicators dominate the evidence?
- And most crucially: if presented with contradictory information, will it change its mind — or dig in its heels?
Spoiler: many models are the latter.
The Setup: Exposing Latent Preferences
The authors ran over 42,000 tests on six leading models — including GPT-4.1, Llama4-Scout, DeepSeek-V3, Qwen3-235B, Gemini-2.5, and Mistral-24B — using a controlled three-phase procedure:
| Stage | Goal | Method |
|---|---|---|
| 1. Evidence Generation | Create balanced buy/sell rationales | Neutral model (Gemini-2.5-Pro) generates arguments for 427 S&P500 stocks |
| 2. Preference Elicitation | Force the model to choose under balanced evidence | Repeated prompts with symmetric inputs |
| 3. Bias Verification | Increase counter-evidence to test model flexibility | Vary volume and intensity to see if model flips decision |
The test design mimics real-world investing: decisions must be made under conflicting, ambiguous information. That’s where bias shows up.
Sector, Size, and Style — AI’s Investment Taste
Results were both intuitive and alarming:
- Sector Bias: Preferences were model-specific, not market-driven. For example, Llama4-Scout loves Energy, DeepSeek leans into Tech, but GPT-4.1 plays it flat.
- Size Bias: Most models favor large-cap stocks, likely due to richer training data. GPT-4.1 is again the outlier, showing no significant size preference.
- Style Bias: Across the board, models showed a contrarian tilt — favoring underperformers in anticipation of mean-reversion, rather than riding momentum.
This matters because even if your investment thesis favors, say, a small-cap momentum play in Consumer Discretionary, your AI might subtly twist the analysis to favor a large-cap contrarian Energy stock instead.
When Bias Becomes Stubbornness
What elevates this paper beyond mere observation is its quantification of bias resilience:
- When presented only with counter-evidence, most models flipped their stance — showing they can be corrected.
- But with mixed evidence, flip rates plummeted. Even when counter-evidence outweighed supporting evidence, models often stuck with their initial bias.
- Even worse: boosting the intensity (e.g., higher projected returns) of counter-evidence had limited effect. Some models remained unmoved.
This is confirmation bias in its purest form — and it’s embedded in AI.
A Final Twist: Confidence vs. Conflict
Using entropy analysis, the authors show that more biased models (like DeepSeek-V3) are confident in balanced cases but hesitant when challenged. Meanwhile, more neutral models (like GPT-4.1) appear uncertain at first — but become decisive when the evidence tilts clearly.
This suggests that the illusion of confidence in an LLM may be a sign of bias, not accuracy. In financial AI, that’s a dangerous mix.
Why This Matters for Financial AI Builders
If you’re deploying LLMs in investment services, here’s the uncomfortable truth:
You’re not just building a tool — you’re importing a worldview.
That worldview might include a deep preference for megacaps, a reflexive contrarianism, or even a silent aversion to certain sectors. And unless you audit and counter-train those biases, your AI may routinely diverge from your firm’s strategy — or your client’s intent.
In that sense, model selection becomes not just a performance decision, but a governance decision. You’re choosing whose financial instincts get embedded in your stack.
Toward Trustworthy Investment AI
The paper ends with a call to build transparent, evidence-aligned financial agents. One could imagine a future where:
- Model preferences are declared, not hidden.
- Bias audit scores become part of standard evaluation.
- LLMs are trained to calibrate and defer when facing counter-evidence.
Until then, financial professionals must stay vigilant. Because in AI-powered finance, the biggest risk isn’t just hallucination — it’s when your model disagrees with your thesis, and you don’t even know it.
Cognaptus: Automate the Present, Incubate the Future