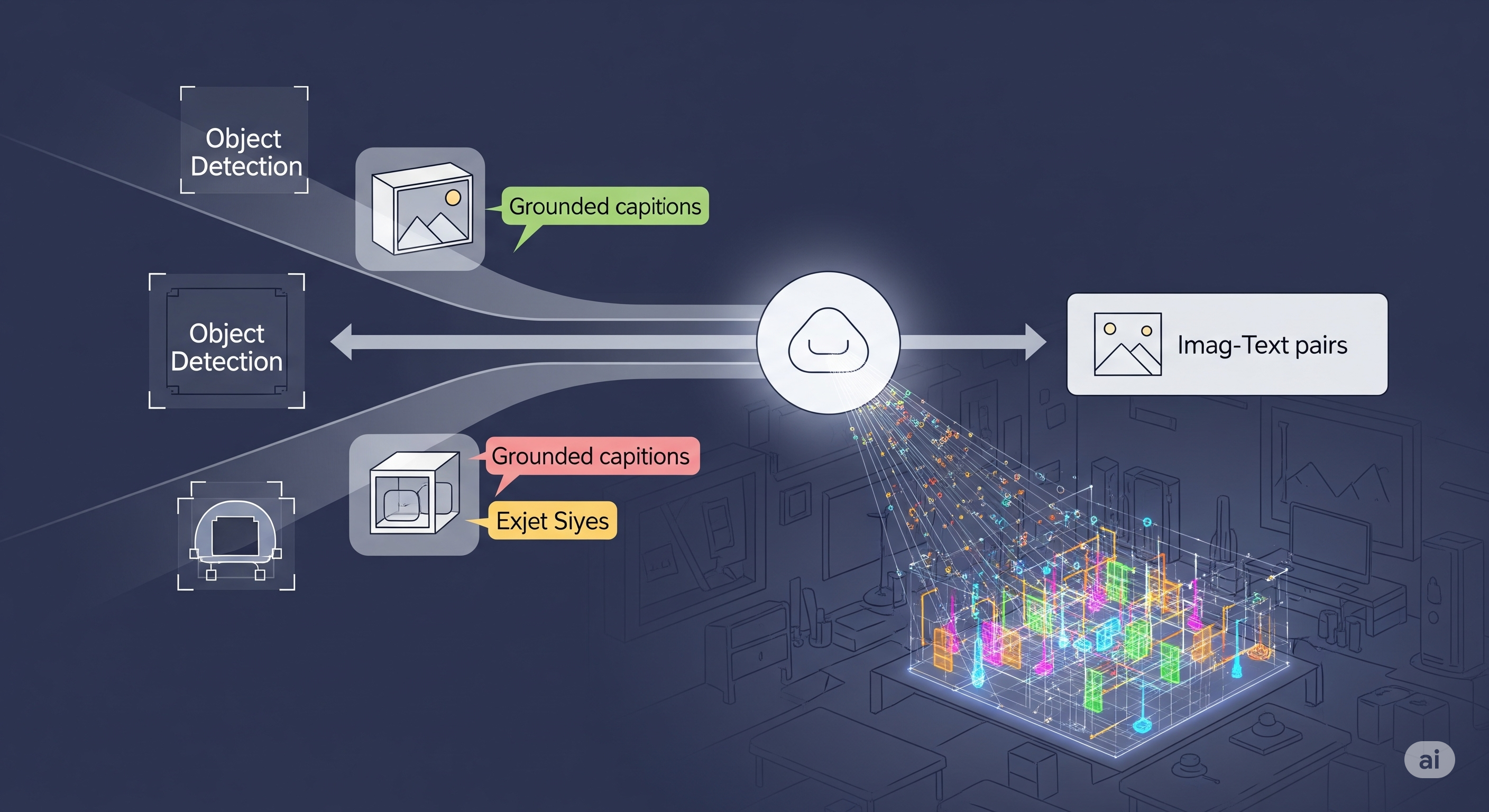
Open-vocabulary object detection — the holy grail of AI systems that can recognize anything in the wild — has been plagued by fragmented training strategies. Models like OWL-ViT and Grounding DINO stitch together multiple learning objectives across different stages. This Frankensteinian complexity not only slows progress, but also creates systems that are brittle, compute-hungry, and hard to scale.
Enter OmniTrain: a refreshingly elegant, end-to-end training recipe that unifies detection, grounding, and image-text alignment into a single pass. No pretraining-finetuning sandwich. No separate heads. Just a streamlined pipeline that can scale to hundreds of thousands of concepts — and outperform specialized systems while doing so.
The Problem with Patchwork Pipelines
Let’s start with the status quo. Open-vocabulary detectors typically involve:
- Stage 1: Pretrain a vision-language backbone (e.g., CLIP) on image-text pairs.
- Stage 2: Finetune on detection datasets (e.g., COCO, LVIS) using class names.
- Stage 3: Add grounding supervision from referring expressions or region captions.
This sequential stacking of tasks leads to alignment drift between components and requires manual curation of objectives. It’s also inflexible — want to add a new data source or objective? Good luck.
OmniTrain’s Unified Training: A Three-Stream Symphony
OmniTrain solves this with a fully joint training scheme using three data streams:
| Data Type | Source Examples | What It Provides |
|---|---|---|
| Det | COCO, LVIS | Class labels + boxes |
| Grd | RefCOCOg, Flickr30K | Text spans + boxes |
| Img | LAION, CC12M | Image-caption pairs only |
Rather than alternating or separating these, OmniTrain mixes them in a single batch and processes them with a shared backbone and prediction head.
Token-Only Grounding: The Secret Sauce
One of OmniTrain’s biggest innovations is its token-only grounding strategy:
- Instead of aligning whole sentences or contrastive embeddings, it uses token-level classification over a shared vocabulary.
- This turns grounding into a classification task — fully compatible with standard detection heads.
- It scales naturally to large vocabularies (e.g., “red toolbox handle”) and supports fine-grained disambiguation.
No contrastive loss, no late fusion, no extra modules — just clean, token-wise alignment across tasks.
Matching Made Modular
OmniTrain uses task-specific matching strategies within a unified loss computation:
- Detection data uses Hungarian matching for boxes and class logits.
- Grounding data uses token alignment via cross-entropy over token targets.
- Image-caption data uses image-text matching through softmax classification.
Despite different matching rules, everything flows through a single loop — enabling scalable, stable training.
How Well Does It Work?
Results are impressive. OmniTrain’s model, OmniDet, beats existing models without expanding model size or using fancy tricks:
| Dataset | Metric | OWL-ViT | Grounding DINO | OmniDet |
|---|---|---|---|---|
| RefCOCOg | AIGT | 67.2 | 63.4 | 72.3 |
| COCO | mAP | 39.8 | 39.1 | 43.5 |
| LVIS | mAP | 25.1 | 27.5 | 29.9 |
All this with a ViT-B/16 backbone and 86M parameters — no need for CLIP, CoCa, or GPT-based decoders.
Why It Matters
OmniTrain reflects a deeper shift: training is the new architecture. As large models converge to similar backbones (ViTs, ResNets), performance increasingly hinges on how they’re trained, not what they’re made of.
By embracing end-to-end, mixed-objective training, OmniTrain avoids the frankenmodel trap. It also opens doors to truly scalable object detection — imagine deploying this in robotics, AR systems, or industrial vision where retraining on new categories needs to be fast, reliable, and inexpensive.
For teams building multi-modal systems, the takeaway is clear: stop alternating, start unifying. The age of piecemeal pipelines is ending — and OmniTrain is leading the way.
Cognaptus: Automate the Present, Incubate the Future