In an age where TikTok traders and YouTube gurus claim market mastery, a new benchmark dataset asks a deceptively simple question: Can AI tell when someone really believes in their own stock pick? The answer, it turns out, reveals not just a performance gap between finfluencers and index funds, but also a yawning chasm between today’s multimodal AI models and human judgment.
Conviction Is More Than a Call to Action
The paper “VideoConviction” introduces a unique multimodal benchmark composed of 288 YouTube videos from 22 financial influencers, or “finfluencers,” spanning over six years of market cycles. From these, researchers extracted 687 stock recommendation segments, annotating each with:
- Ticker (e.g., AAPL)
- Action (buy, sell, hold, short, etc.)
- Conviction score (1–3)
The conviction score isn’t just sentiment. It reflects delivery strength: vocal tone, facial expressions, body language, and consistency between what’s said and how it’s said. A shaky recommendation with a bold title gets docked. A confident, articulate call to buy a stock gets top marks.
This nuance makes VideoConviction a rare testbed for multimodal large language models (MLLMs), which ingest not just transcripts but full video content. Yet it’s not just a test of AI’s capability. It also serves as a mirror for how we, as retail investors, are swayed by charisma over substance.
Models That Watch, Listen, and Still Miss the Point
The benchmark defines three tasks:
- T: Identify the mentioned ticker
- TA: Extract both the ticker and the investment action
- TAC: Extract ticker, action, and the speaker’s conviction score
While top MLLMs like Gemini 2.0 Pro and GPT-4o excel at task T (achieving ~86% F1 on segmented videos), performance sharply declines on the more nuanced TAC task, where even the best models score below 28%. Surprisingly, text-only LLMs like DeepSeek-V3 often outperform their multimodal counterparts here. That suggests AI can parse language better than it can interpret conviction — a domain where subtle delivery cues remain poorly understood.
This points to a structural blind spot: multimodal models are great at what was said, but struggle with how strongly it was meant.
| Model | Task T (F1) | Task TA (F1) | Task TAC (F1) |
|---|---|---|---|
| Gemini 1.5 Pro (video) | 86.01% | 53.51% | 24.97% |
| GPT-4o (video) | 83.47% | 51.15% | 27.86% |
| DeepSeek-V3 (text) | 77.56% | 51.35% | 28.17% |
Even with segmented inputs to remove noisy intros, ads, and tangents, no model crosses the 30% bar on TAC.
Betting Against Charisma: A Financial Backtest
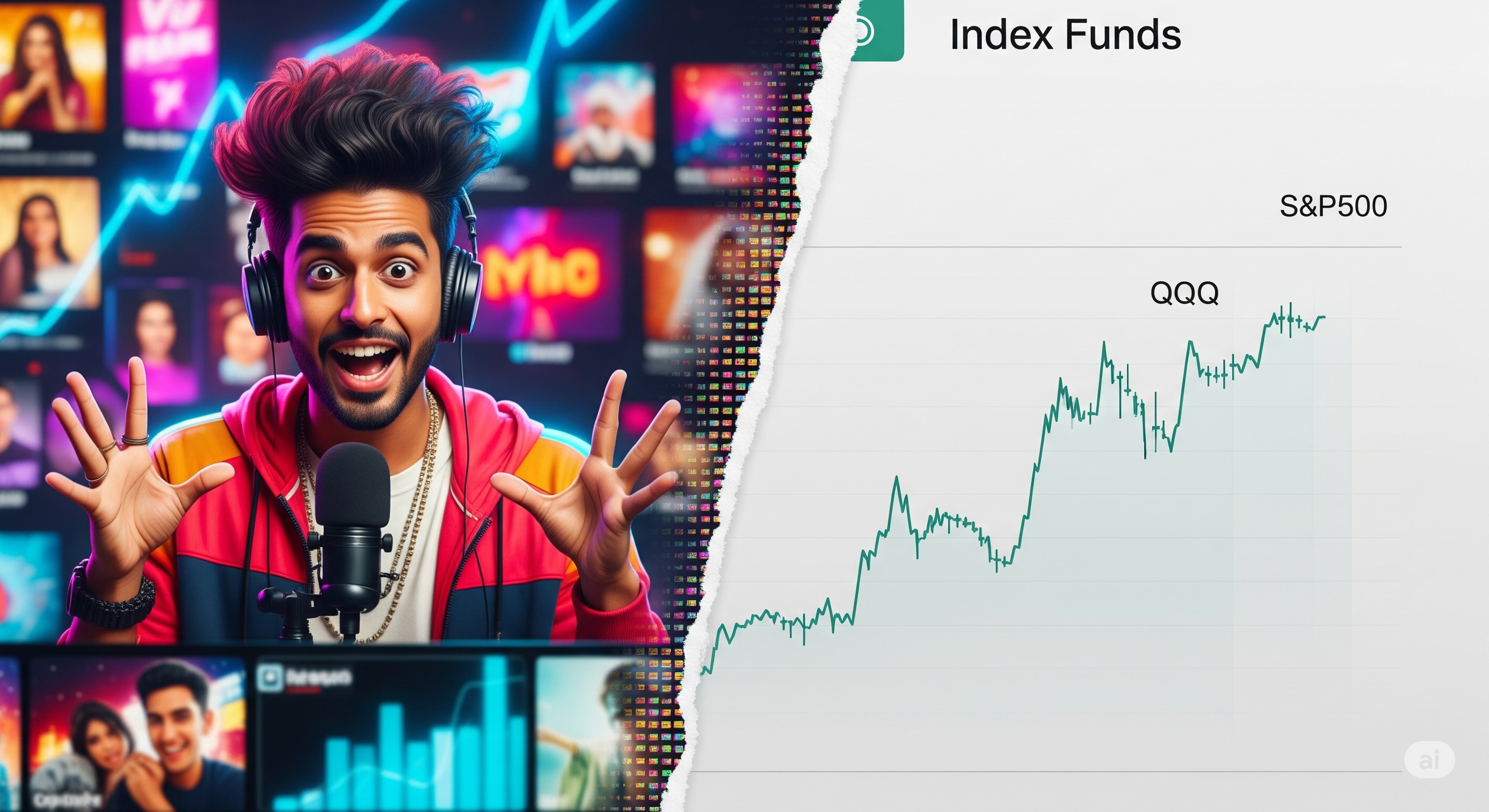
The authors didn’t stop at benchmarking AI. They also tested whether finfluencer conviction translated into market performance. Using a simple buy-and-hold strategy over six months per recommendation, they found:
- Inverse YouTuber strategy (betting against recommendations) earned 17.9% annually, beating the S&P 500 and even QQQ.
- Buy-and-hold (weighted by conviction) returned just 4.47% annually.
- High-conviction picks outperformed low-conviction ones, but still lagged behind passive index funds like QQQ.
This creates an interesting paradox:
The very delivery style that boosts a finfluencer’s reach and audience trust seems inversely correlated with actual portfolio value.
Implications for AI and Finance
The VideoConviction benchmark reveals three critical lessons:
-
Conviction detection is an unsolved frontier for AI. MLLMs remain surface-level observers, missing the embodied signals that human listeners use instinctively to judge sincerity or overconfidence.
-
Index funds still beat personality. Regardless of how persuasive the pitch is, most finfluencer recommendations underperform. The inverse strategy working so well might reflect systemic overconfidence.
-
Segmentation matters. Feeding shorter, context-focused video segments significantly improves AI accuracy. This supports a growing trend in model evaluation: less is more when context is correctly scoped.
Toward More Skeptical Machines
In an era where AI tools are increasingly tasked with monitoring or even imitating influencers, VideoConviction is a timely reminder: belief is not just what you say, but how you say it. And parsing belief still remains an area where humans outclass machines.
As LLMs are fine-tuned on more social media data, we may one day build models that not only transcribe what a person says, but also flag when they sound suspiciously overconfident. Until then, your safest bet may be to bet against the most persuasive voice in the room.
Cognaptus: Automate the Present, Incubate the Future.