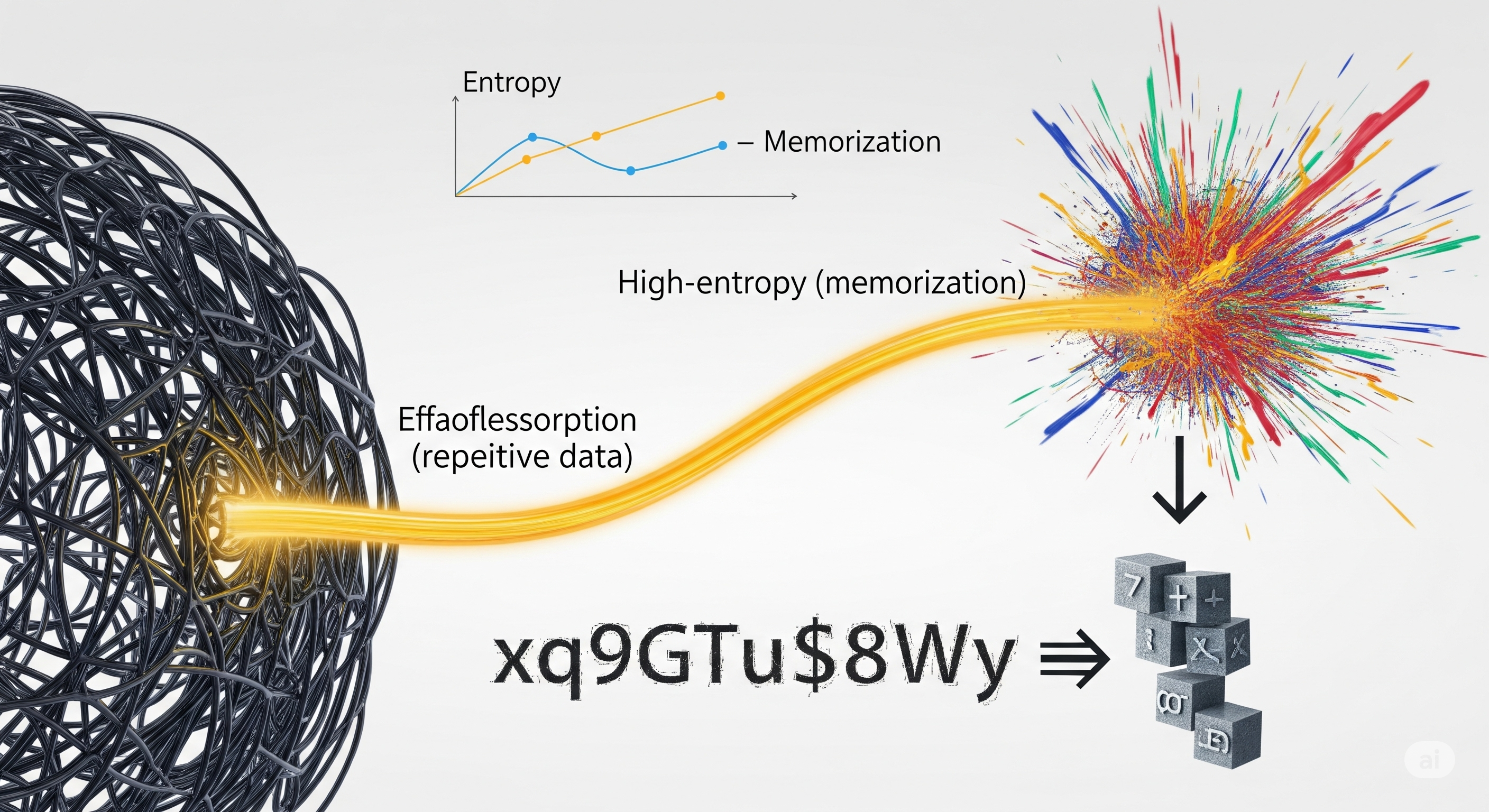
The best kind of privacy leak is the one you can measure. A recent paper by Huang et al. introduces a deceptively simple but powerful principle—the Entropy-Memorization Law—that allows us to do just that. It claims that the entropy of a text sequence is strongly correlated with how easily it’s memorized by a large language model (LLM). But don’t mistake this for just another alignment paper. This law has concrete implications for how we audit models, design prompts, and build privacy-aware systems. Here’s why it matters.
The Core Insight: A Linear Relationship Between Entropy and Memorization
The authors run extensive experiments using the open OLMo model family, comparing input-output pairs from training data with the model’s responses. By measuring the Levenshtein distance (token-level edit distance) between the expected answer and the generated one, they derive a memorization score. Then, they compute the entropy of the original answer segment, asking: does higher entropy correlate with higher memorization difficulty?
Yes—and quite strongly.
Their second attempt, using a level-set-based entropy estimator, reveals a near-linear relationship between entropy and memorization score, with Pearson r values over 0.94. This is the Entropy-Memorization Law:
The higher the entropy of a data segment, the more difficult it is for an LLM to memorize it.
This is more than an academic curiosity. It gives us a predictable, model-agnostic proxy for assessing memorization risk in training data.
Why ‘Gibberish’ Is Surprisingly Easy to Memorize
But then comes a twist. During their experiments, the authors notice that gibberish-like strings—random-looking tokens like 5laXo6c1IbEbegDmzGPwGNTsHZ...—are often perfectly memorized. Doesn’t that contradict the law?
It does—until you change your perspective.
Humans assess gibberish using character-level entropy (lots of variation), but LLMs process and memorize data at the token level. Tokenizers often segment such strings into a few frequently seen substrings (e.g., ‘Ib’, ‘Eg’, ‘Dm’), resulting in low token-level entropy despite high character randomness. Thus, to the LLM, gibberish may look simple, repetitive, and very easy to memorize.
This finding has startling implications for real-world credential leakage:
| Credential Type | Character-Level Entropy | Token-Level Entropy | Memorization Risk |
|---|---|---|---|
xq9GTu$8Wy |
High | Low | High |
login |
Low | Low | High |
Lorem ipsum... |
Medium | Medium | Medium |
Service providers focused on maximizing char-level randomness in API keys or passwords might be solving the wrong problem. It’s token-level entropy that governs LLM memorization.
A Tool for Dataset Inference: EMBEDI
The Entropy-Memorization Law also becomes a springboard for a simple yet effective dataset inference tool the authors call EMBEDI. By plotting entropy against memorization score on suspected data samples and comparing the regression slope and intercept to known training data, EMBEDI can:
- Detect whether a dataset was used during LLM pretraining
- Identify test set contamination
- Audit copyrighted content leakage (e.g., books, credentials)
No external reference set or training is required—just access to the model and enough text samples. This is perhaps the cleanest privacy auditing tool yet proposed.
Why This Law Matters to AI Builders and Business Leaders
Too often, memorization in LLMs is discussed as a vague threat—bad, but unpredictable. This work turns memorization into something measurable, plannable, and actionable. For businesses and regulators, this means:
- Auditability: Organizations can pre-screen training datasets to assess memorization risk.
- Credential Design: Security teams can test whether their random strings are truly unmemorizable at the token level.
- Prompt Engineering: Enterprises using RAG or agent frameworks can avoid feeding LLMs low-entropy prompts that inadvertently trigger leakage.
- Model Compliance: AI vendors can publish entropy-memorization audits as part of model documentation or licensing disclosures.
A Question Worth Asking: Why Does This Work So Well?
Despite its empirical strength, the Entropy-Memorization Law lacks a theoretical explanation. Why should entropy—a simple statistical property—so accurately predict memorization behavior in massive, multi-billion parameter models? This suggests an underlying compression bias in model training: LLMs, at their core, are entropy-minimizers.
One path forward may lie in information bottleneck theory, or in examining the role of token frequency priors in self-attention mechanisms. Until then, the Entropy-Memorization Law remains a powerful empirical tool—and a quiet revolution in how we quantify what LLMs remember.
Cognaptus: Automate the Present, Incubate the Future