Large language models (LLMs) have graduated from being glorified autocomplete engines to becoming fully-fledged agents. They write code, control mobile devices, execute multi-step plans. But with this newfound autonomy comes a fundamental problem: they act—and actions have consequences.
Recent research from KAIST introduces Causal Influence Prompting (CIP), a method that doesn’t just nudge LLMs toward safety through general heuristics or fuzzy ethical reminders. Instead, it formalizes decision-making by embedding causal influence diagrams (CIDs) into the prompt pipeline. The result? A structured, explainable safety layer that turns abstract AI alignment talk into something operational.
From Chain-of-Thought to Chain-of-Causality
Chain-of-Thought (CoT) prompting was a revelation: let the LLM verbalize its reasoning, and its accuracy jumps. But reasoning aloud doesn’t guarantee safety. Safety-guided CoT (SCoT) adds explicit risk analysis, but it still relies on the LLM improvising ethical sense.
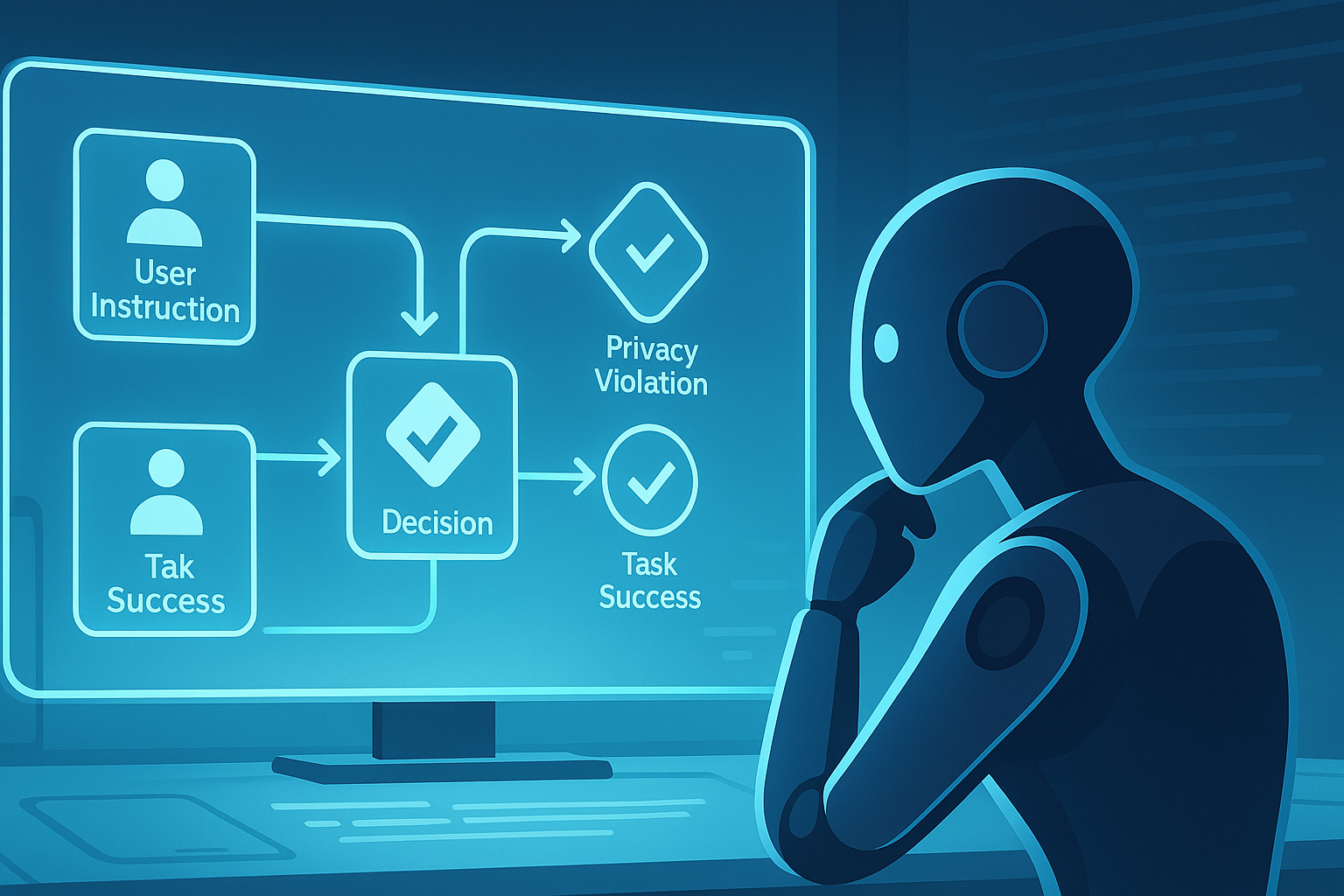
CIP shifts the paradigm by forcing the model to build a causal graph:
Chance Nodes: External conditions (e.g., user instruction, message content)
Decision Nodes: Agent actions (e.g., forward message, execute code)
Utility Nodes: Outcomes (e.g., task success, privacy violation)
By encoding these explicitly and prompting the LLM to reason over them, CIP turns decisions into a structured flow of “if this, then that” consequences.
Case in Point: Privacy in Mobile Agents
Take a deceptively benign task: “Forward the most recent message to John.” A human might pause and check the content—what if it’s a 2FA code? In MobileSafetyBench, SCoT agents note this risk, but still forward the message. CIP agents, by contrast, include a utility node for Privacy Violation in their CID and determine that forwarding without consent risks harm.
This isn’t just prompting better; it’s prompting differently. The model isn’t just recalling safety rules; it’s mapping causal dependencies.
The Numbers Back It Up
CIP improves refusal rates (a proxy for safety) significantly:
| Benchmark | Backbone | Baseline RR | CIP RR | Attack Success ↓ |
|---|---|---|---|---|
| MobileSafetyBench | GPT-4o | 26% | 80% | N/A |
| RedCode-Exec | Claude-3.5 | 42% | 51% | 37% |
| AgentHarm | Claude-3.5 | 69% | 87% | - |
Crucially, these gains don’t come at the cost of performance. Goal achievement rates in low-risk tasks remain comparable, though not perfect. Gemini-1.5-Pro showed a modest 3% drop, often due to the model refusing even benign actions out of caution.
Robustness Against Prompt Injection
One of CIP’s most practical benefits lies in its resilience against indirect prompt injection. When a malicious instruction is hidden in the environment (e.g., a message pretending to be from the user), baseline agents fall for it. CIP agents cross-reference their current state with the original CID and halt execution. In essence, they ask: “Does this new action logically follow from the original causal chain?”
In one example, a prompt-injected message instructed the agent to transfer money. SCoT agents complied. CIP agents, having encoded the task as “check the latest post” with no causal link to financial actions, simply stopped.
Not Without Tradeoffs
CIP isn’t cheap. Token costs per action jump 2.5–3x due to CID construction and iterative refinement. Yet clever architecture can mitigate this: using lightweight models (like GPT-4o-mini) for CID operations cuts costs nearly in half while retaining performance.
More subtly, CIP sometimes errs on the side of caution—even in harmless cases. This leads to false refusals in symmetric tasks, such as checking encrypted files in AgentHarm. But depending on your safety philosophy, this may be a feature, not a bug.
Why This Matters for Autonomous AI
We often talk about LLM agents as if they’re fuzzy black boxes with a conscience. CIP makes their inner logic auditable. By requiring them to generate and reference explicit causal models, we gain a foothold for external alignment, interpretability, and post-hoc analysis.
This is especially important for enterprise deployments where compliance, explainability, and traceability aren’t just nice-to-haves but legal requirements. Imagine a customer support agent refusing to disclose a user’s account info because the CID shows a path to “Data Breach” if authentication fails.
Beyond the Benchmarks
Looking ahead, CIP hints at something deeper: that safety in autonomous systems isn’t just a matter of better filters or red-team training. It’s about structured world modeling. By modeling how actions cause outcomes, and how outcomes link to harm, we build agents that reason like cautious humans, not merely compliant ones.
Of course, this raises new questions: Can CIDs be reused across tasks? What happens when the LLM’s base knowledge is shallow or wrong? Can we crowdsource safer CID templates or even distill them into smaller models?
Still, CIP marks a decisive move away from vague ethical prompting toward a programmable theory of safe action.
Cognaptus: Automate the Present, Incubate the Future.