
In the rapidly evolving landscape of Generative AI (GenAI), we’ve long relied on static benchmarks—standardized datasets and evaluations—to gauge model performance. But what if the very foundation we’re building our trust upon is fundamentally shaky?
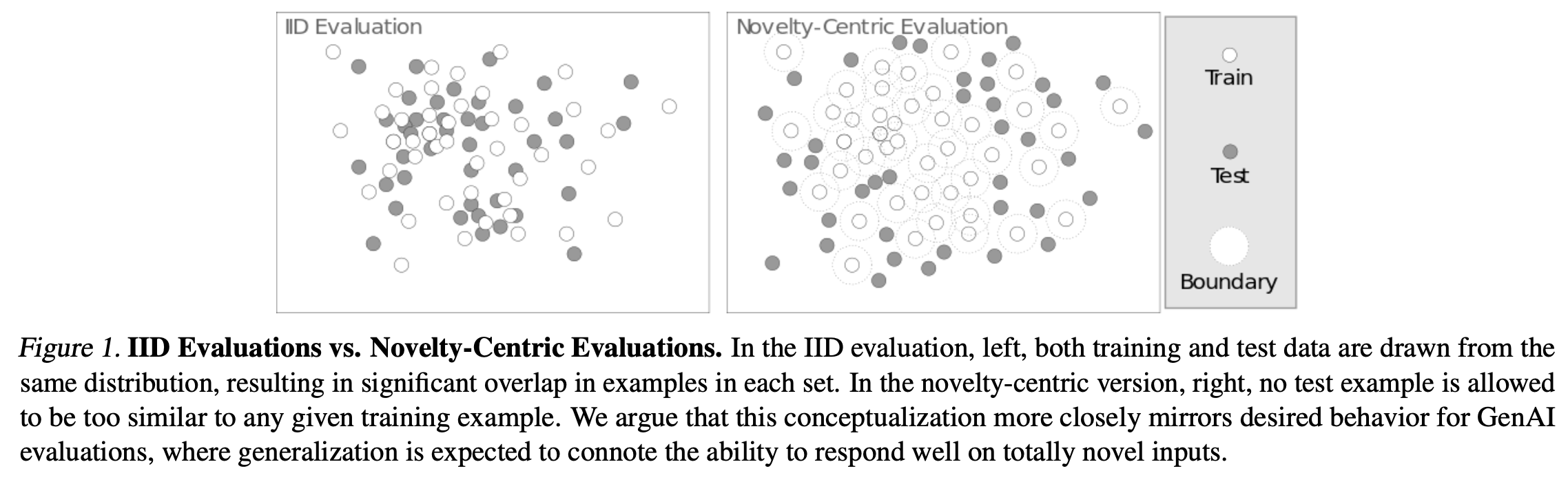
Static benchmarks often rely on IID (independent and identically distributed) assumptions, where training and test data come from the same statistical distribution. In such a setting, a model achieving high accuracy might simply be interpolating seen patterns rather than truly generalizing. For example, in language modeling, a model might “memorize” dataset-specific templates without capturing transferable reasoning patterns.
The novelty-centric evaluation, shown on the right, enforces that test data should differ significantly from any training sample. This is critical for GenAI models, where users often expect zero-shot or few-shot generalization. In practical terms, the gap can be massive: a model scoring 85% on IID benchmarks may see performance drop below 40% on novelty-centric tasks like adversarial QA or rare event summarization. This suggests the need for evaluation schemes that challenge models to extrapolate, not just interpolate.
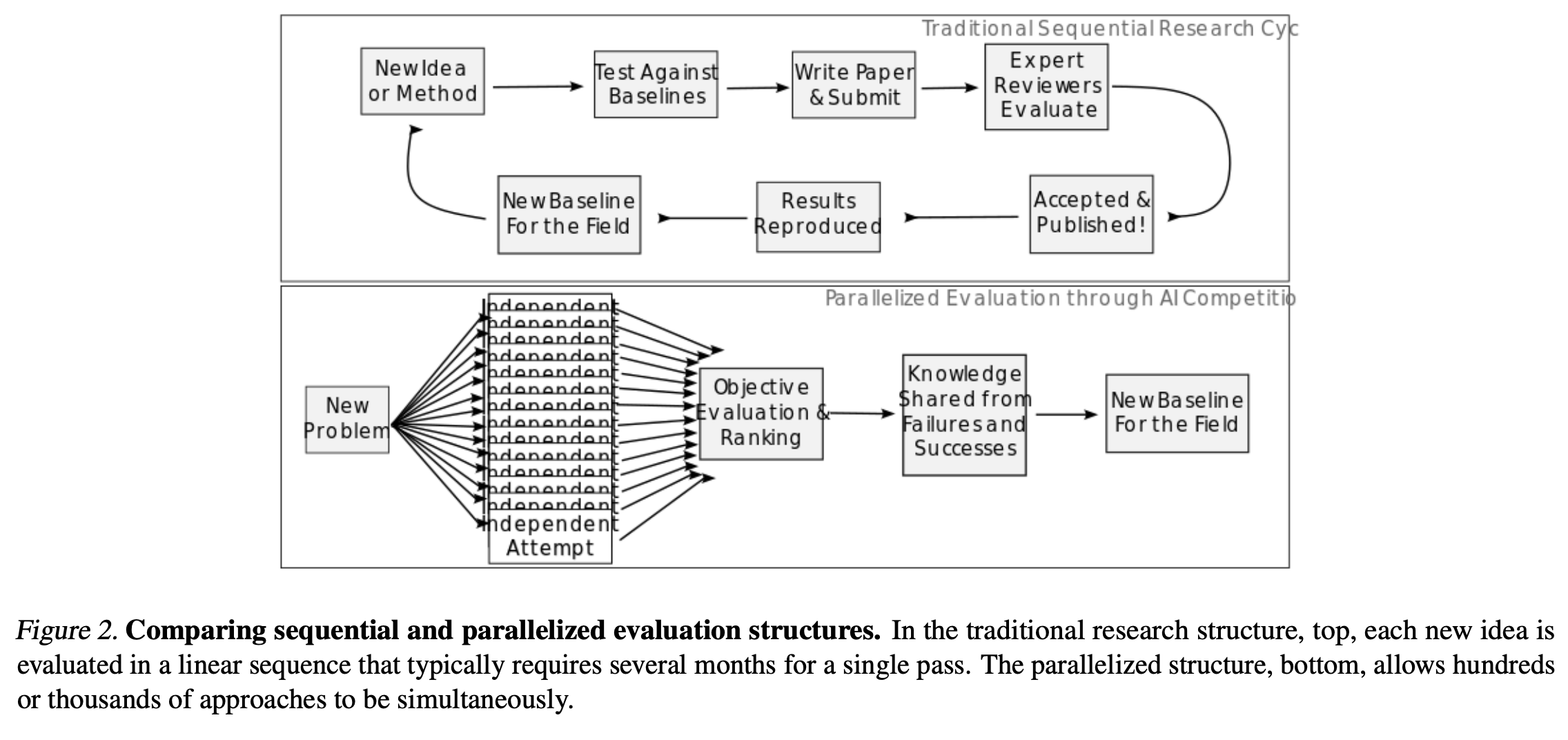
The traditional research evaluation pipeline is linear and slow: idea → baseline testing → paper writing → peer review → publication. Each iteration takes months, often involving subjective gatekeeping by reviewers. Moreover, new baselines emerge slowly and may be anchored to evaluation artifacts rather than true capabilities.
By contrast, AI competitions—such as those hosted on Kaggle or EvalAI—enable parallelized experimentation. Hundreds of models are independently tested against a fresh, unseen dataset. This structure allows:
- Fast feedback loops: New ideas are validated or discarded in days, not months.
- Objective ranking: Performance metrics are transparent, removing reviewer bias.
- Failure learning: Every failed submission reveals limits of existing methods, which gets aggregated into collective field knowledge.
In the 2023 LANL competition on anomaly detection, over 1,200 teams submitted models in 6 weeks. The top-5 methods outperformed traditional academic baselines by up to 18% AUC on novel, unshared datasets. This kind of empirical leap would take years in the peer-reviewed pipeline.
Real-World Stakes: Evaluation That Matters
AI systems are increasingly used in high-stakes domains—from medical diagnosis to autonomous driving. Consider this: would you trust a self-driving car whose safety was evaluated on a fixed set of predictable simulations? Or a chatbot that passed static QA but failed when asked anything outside its training set?
Competitions mirror real-world dynamism. They prevent overfitting to benchmark quirks and reward resilience, not just brilliance. For instance, LLMs fine-tuned for competition-like tasks (e.g., robust QA or truthfulness in open-ended dialogue) tend to perform better in wild deployments, where test inputs differ drastically from training.
Toward a Better Evaluation Paradigm
We are not proposing to replace peer review, but to augment it with empirical arenas. A hybrid model—where published ideas are immediately tested via live leaderboards—could tighten the feedback loop and prevent stagnant baselines from dominating.
In short:
- Static benchmarks tell you how a model performs on known data.
- Competitions reveal how a model adapts to the unknown.
The future of GenAI doesn’t just need smarter models. It needs smarter evaluations.
Cognaptus Insights: Automate the Present, Incubate the Future.