
Training AI agents to navigate complex environments has always faced a fundamental bottleneck: the overwhelming number of possible actions. Traditional reinforcement learning (RL) techniques often suffer from inefficient exploration, especially in sparse-reward or high-dimensional settings.
Recent research offers a promising breakthrough. By leveraging Vision-Language Models (VLMs) and structured generation pipelines, agents can now automatically discover affordances—context-specific action possibilities—without exhaustive trial-and-error. This new paradigm enables AI to focus only on relevant actions, dramatically improving sample efficiency and learning speed.
Cracking the Code of Action: A New Approach
The paper “Cracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning” introduces the CoGA framework1. CoGA empowers RL agents with a generative affordance discovery system that operates in three stages:
- Action Program Generation: A VLM observes a task description and environment state, then proposes Python-like code snippets representing possible actions.
- Affordance Critique: Another model reviews these candidate programs, scoring them for plausibility and relevance.
- Affordance Realization: The highest-quality programs are executed or simulated to verify feasibility before guiding agent behavior.
This multi-stage pipeline shifts the agent’s exploration strategy from naive trial-and-error toward intelligent, context-aware decision pruning.
Figure 1: Overview of CoGA
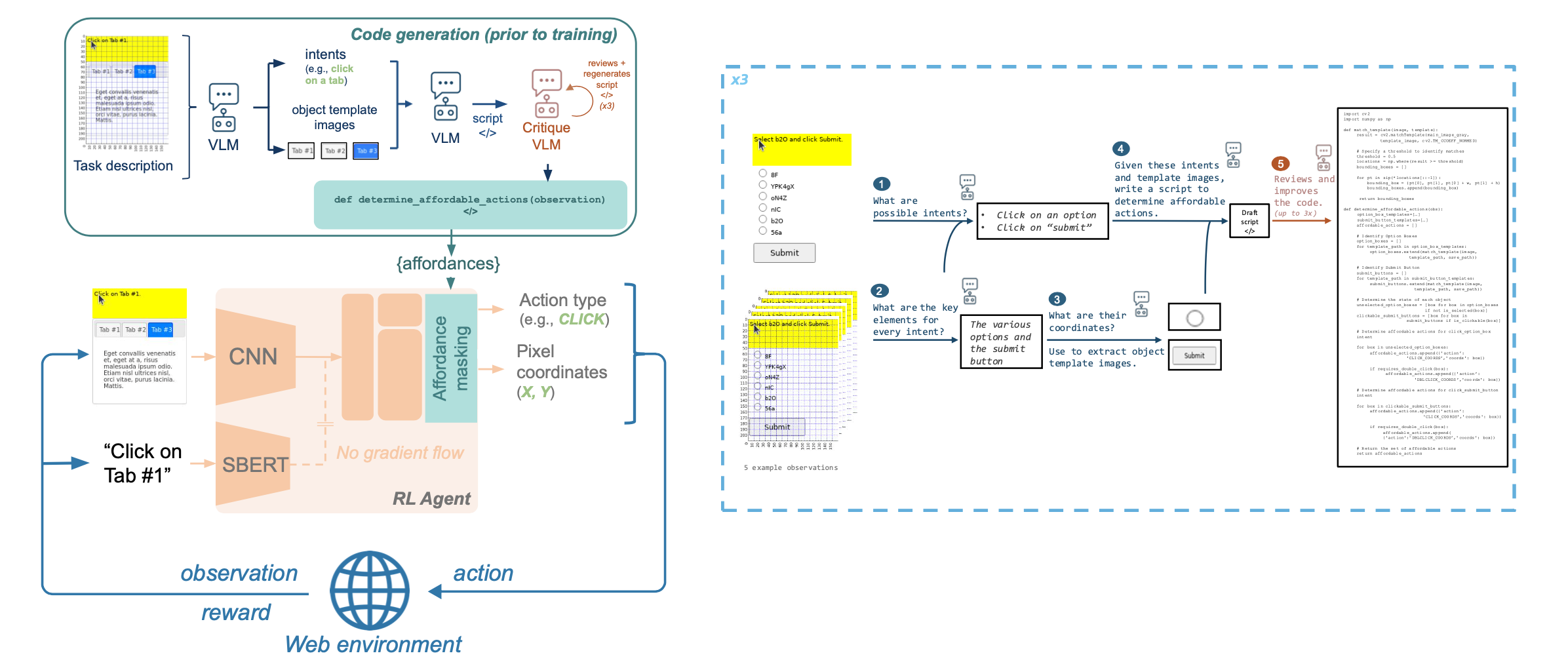
Why Use a Pre-trained Vision-Language Model (VLM)?
CoGA relies on a pre-trained VLM because agents must semantically understand both the visual environment and the textual task description. A VLM enables the agent to perceive multimodal input and generate structured action programs. Without a visual generative function, the agent would lack the ability to contextualize what actions make sense in unseen environments. Thus, the VLM’s generative capabilities are essential for affordance proposal grounded in real-world visual cues.
What Language are the Generated Codes Based On?
The generated action programs are based on Python-like pseudo-code, specifically structured around high-level web interaction primitives such as Click(element), Type(element, text), and Submit(form). These code snippets represent feasible and executable actions in graphical user interface environments like MiniWob++, bridging perception and operational execution.
Is Policy Generated First Before Code?
No, CoGA does not generate a full policy first. It first generates candidate action programs (affordances) based on the environment and task. These affordances constrain the action space, after which the RL agent learns the actual policy through standard reinforcement learning within the affordance-pruned space. Thus, CoGA acts as a pre-exploration action filter, not as a direct policy generator.
Why Affordance Discovery Matters
Without affordance awareness, RL agents must sample blindly across vast action spaces, often wasting time on irrelevant behaviors. Affordance discovery offers several major advantages:
- Efficiency: CoGA achieves up to 10× faster learning than traditional RL baselines on MiniWob++ web automation tasks.
- Generalization: Affordance models can transfer across tasks, enabling faster adaptation to new environments.
- Scalability: As action spaces grow larger, affordance discovery becomes even more critical to maintain learning feasibility.
By integrating generative reasoning early in the decision pipeline, agents effectively “see the forest for the trees,” focusing exploration on truly meaningful interactions.
Technical Highlights
- VLM Foundation: CoGA builds upon powerful VLMs capable of understanding multimodal inputs and proposing executable code.
- Self-Critique Loop: A built-in refinement stage filters out infeasible or irrelevant action programs, improving robustness.
- Contextual Adaptability: Generated affordances are highly sensitive to specific environmental contexts and goal descriptions.
- Sample Efficiency: Empirical results show significant performance gains even in extremely sparse reward settings.
Why CoGA Outperforms Traditional RL and Behavioral Cloning (BC)
In traditional RL, agents suffer from inefficient exploration due to the vastness of the action space and sparse rewards. Behavioral Cloning (BC) relies heavily on the availability of high-quality demonstrations and struggles in unseen environments. CoGA wins because it strategically reduces the action space by generating task-relevant affordances, critiques these proposals for quality, and only explores feasible pathways. This affordance-aware pruning leads to substantially higher sample efficiency and robustness compared to naive exploration (RL) or demonstration mimicry (BC).
CoGA’s Practical Impact for External UI Agents
CoGA is highly practical for AI agents interacting with external graphical user interfaces (UIs). By generating executable web interaction commands, agents can navigate, fill forms, click buttons, and perform complex UI-based workflows intelligently, without relying on brute-force or hardcoded scripts. This makes CoGA especially valuable for automating tasks in environments like RPA systems, enterprise software platforms, and web automation.
Broader Implications for Autonomous Agents
Generative affordance discovery represents a critical step toward truly autonomous, self-improving AI systems. Rather than relying purely on preprogrammed policies or brute-force exploration, future agents can dynamically hypothesize, critique, and adapt their own action sets based on situational understanding.
For businesses and industries seeking AI solutions that operate reliably in open-ended, complex environments, incorporating affordance discovery mechanisms offers a path to:
- Reduced training costs through faster convergence.
- Greater agent robustness against environmental variability.
- Enhanced operational autonomy with minimal human intervention.
Conclusion: Toward Smarter Exploration
In nature, survival often depends not on doing everything, but on doing the right things. Similarly, the next generation of AI agents must move beyond infinite exploration toward intelligent selection.
By teaching agents to recognize what matters—through structured, generative affordance discovery—we open the door to more efficient, adaptable, and truly autonomous AI systems.
At Cognaptus, we believe frameworks like CoGA illuminate the next frontier of intelligent agent design: agents that do not simply react, but reason about action itself.
Cognaptus Insights: Automate the Present, Incubate the Future
-
[Submitted on 24 Apr 2025] Cracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning, Lynn Cherif, Flemming Kondrup, David Venuto, Ankit Anand, Doina Precup, Khimya Khetarpal. arXiv:2504.17282 [cs.AI] ↩︎