
Logos, Metron, and Kratos: Forging the Future of Conversational Agents
Conversational agents are evolving beyond their traditional roles as scripted dialogue handlers. They are poised to become dynamic participants in human workflows, capable not only of responding but of reasoning, monitoring, and exercising control. This transformation demands a profound rethinking of the design principles behind AI agents.
In this Cognaptus Insights article, we explore a new conceptual architecture for next-generation Conversational Agents inspired by ancient Greek notions of rationality, measurement, and governance. Building on recent academic advances, we propose that agents must master three fundamental dimensions: Logos (Reasoning), Metron (Monitoring), and Kratos (Control). These pillars, grounded in both cognitive science and agent-based modeling traditions, provide a robust foundation for agents capable of integrating deeply with human activities.
Redefining the Conversational Agent: From Interaction to Intelligent Action
The evolution of Conversational Agents is rooted in their ability to perform three interdependent functions:
- Reasoning (Logos): Logical and systematic thinking to derive insights and make sound decisions.
- Monitoring (Metron): Observing internal states, external contexts, and user interactions to maintain coherence and goal alignment.
- Control (Kratos): Executing tasks, validating outputs, invoking tools, and adapting dynamically to evolving circumstances.
Compared to other classification schemes, such as dialogue-state models, information-centric models, or emotion-driven designs, this tripartite structure captures not only cognitive processing but also dynamic adaptation and reliable action, offering a scalable path forward for truly autonomous agents.
| Alternative Framework | Pillars | Problems |
|---|---|---|
| Information-Centric | Retrieval, Interpretation, Response | Narrow: misses action execution, long-term adaptation. |
| Emotion-Centric | Empathy, Context Awareness, Personalization | Too soft for business process and task control settings. |
| Dialogue-State Only | Intent Detection, Slot Filling, Dialogue Management | Outdated: suitable for early dialogue systems, not agentic behavior. |
| Task-Centric | Execution, Decision Making, Reporting | Misses reflective and adaptive monitoring crucial for real autonomy. |
Figure 1: Overview of a Conversational Agent illustrating proposed desideratum
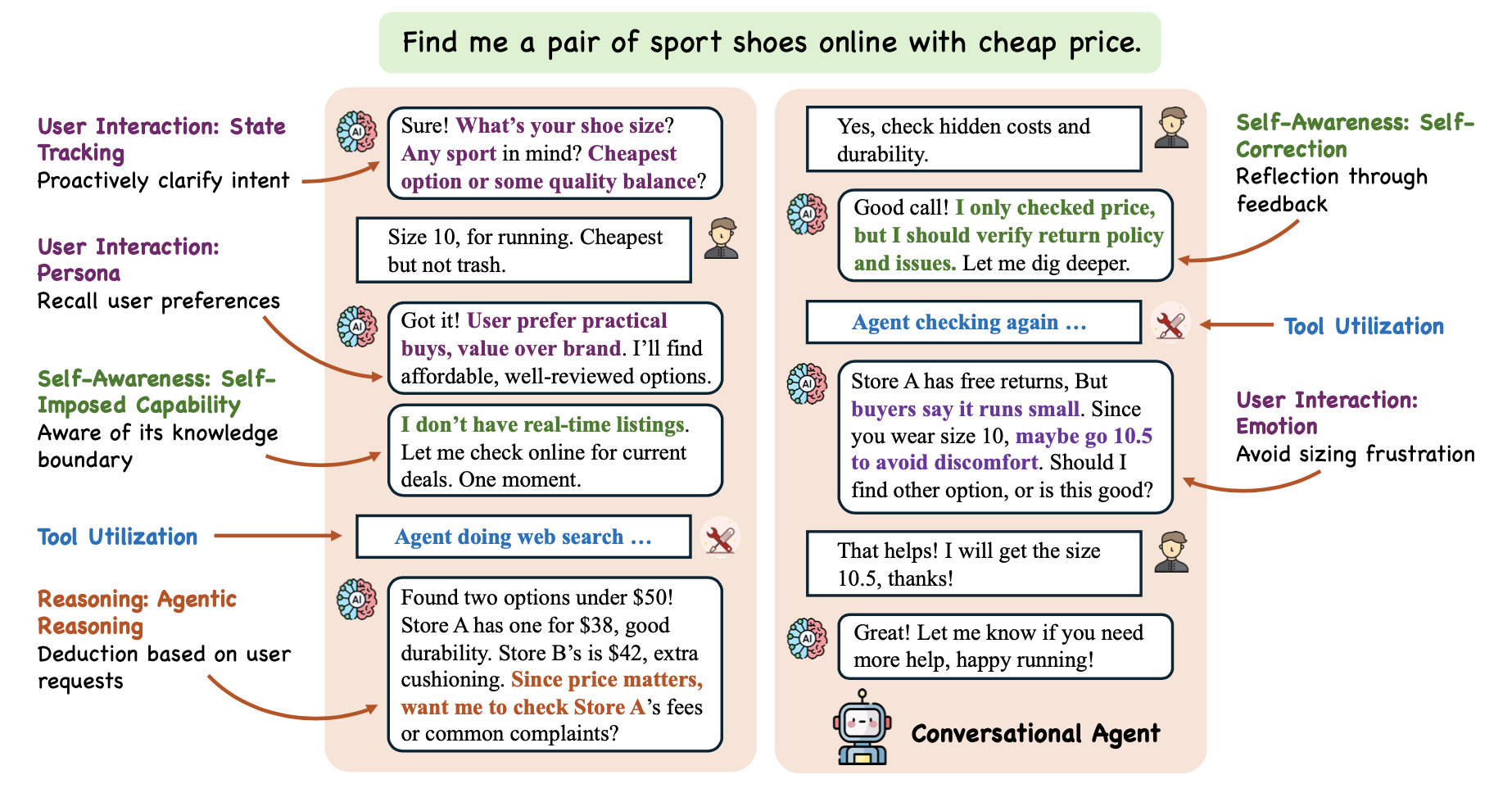
This tripartite model ensures agents are not only engaging conversationalists but intelligent actors capable of proactive, context-aware, and reliable task execution.
A Taxonomy for the Future
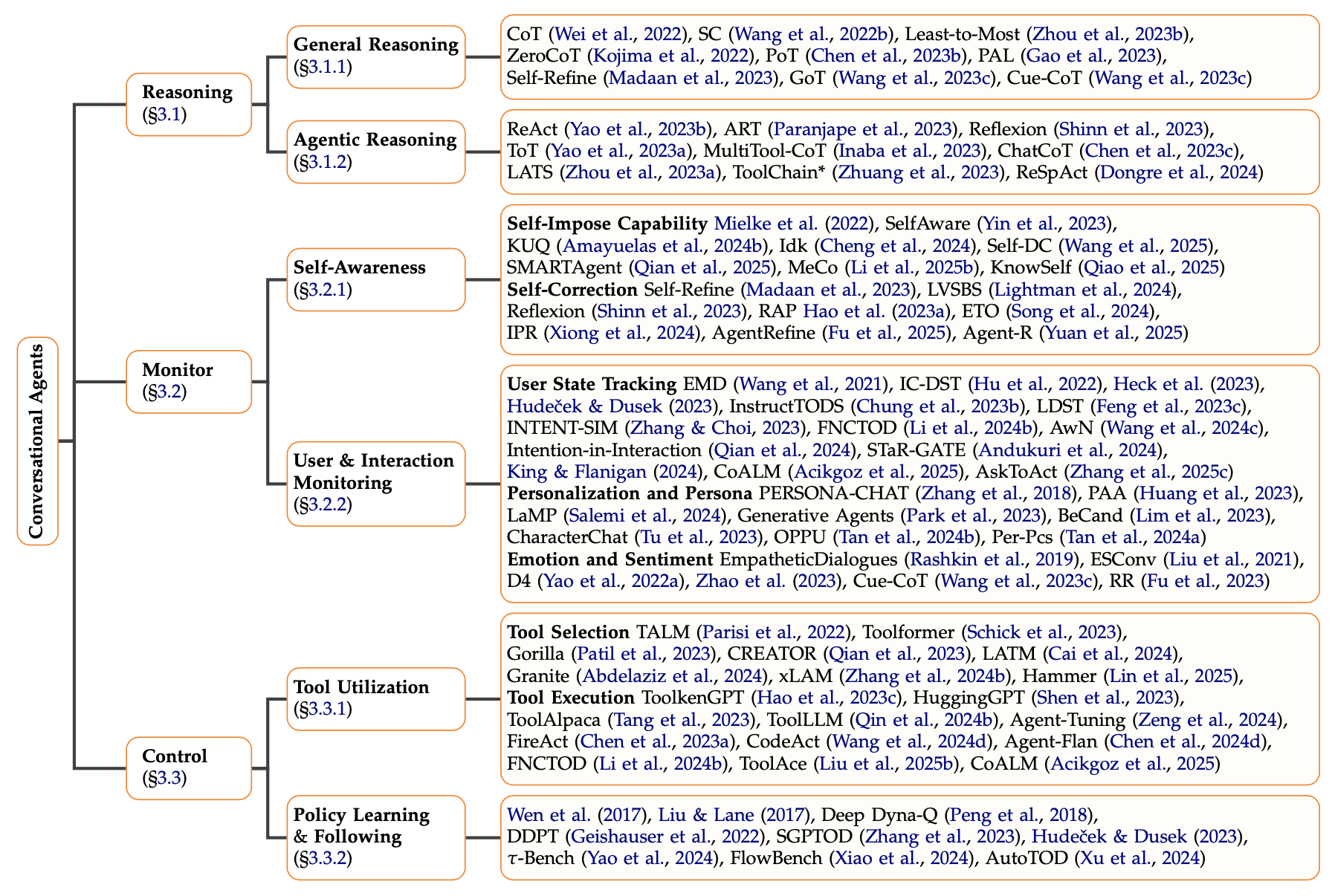
To operationalize these capabilities, a detailed taxonomy maps each pillar into finer-grained sub-skills, reflecting the best current research directions.
Reasoning subdivides into:
- General Reasoning: Cognitive chains of thought, logical decomposition, answer refinement (e.g., CoT, Self-Refine).
- Agentic Reasoning: Goal-driven planning and action decision-making (e.g., ReAct, ToT, Reflexion).
| Aspect | General Reasoning | Agentic Reasoning |
|---|---|---|
| Definition | Logical, chain-based deduction over knowledge or questions. | Goal-driven, decision-making reasoning for dynamic actions. |
| Example | Solving a math problem step-by-step (CoT, ZeroCoT). | Deciding which tool to call first, dynamically adapting plans (ReAct, ToT). |
| Focus | Cognitive processing. | Action selection and environment interaction. |
| Key Techniques | Chain of Thought (CoT), Self-Refine. | ReAct, Tree of Thoughts (ToT), Reflexion. |
Monitoring subdivides into:
- Self-Awareness: Agents maintaining internal consistency and adaptiveness.
- User and Interaction Monitoring: Tracking user states, intents, and dialogue dynamics.
Control subdivides into:
- Tool Utilization: Selecting and operating external tools robustly.
- Policy Learning and Following: Learning adaptive policies for dynamic task execution.
Figure 2: A taxonomy of our desiderata for Conversational Agents, with representative approaches listed for each component
| Selected Taxonomy | Meaning |
|---|---|
| CoT (Chain of Thought) | Breaks complex questions into intermediate reasoning steps. |
| ZeroCoT | Induces CoT-style reasoning without few-shot examples. |
| Self-Refine | Model self-improves by iteratively refining answers. |
| ReAct | Combines reasoning and acting (tool use) during generation. |
| ToT (Tree of Thoughts) | Searches multiple reasoning paths in parallel. |
| ToolChain | Structured workflows combining multiple LLM calls. |
| SelfAware | Agents develop explicit self-state representations during tasks. |
| Reflexion | Agents reflect after failures and retry improved plans. |
| SMARTAgent | Strategic multi-agent collaboration framework. |
| IPR | Iterative Planning and Reflection agents for dynamic problem solving. |
| EMD | Embedding-based User State Tracking. |
| IC-DST | Improved Contextual Dialogue State Tracking for maintaining session memory. |
| CoALM | Context-aware Language Modeling for better dialogue state prediction. |
| PERSONA-CHAT | Personalization dataset with predefined personas. |
| LaMP | Language Model Personas that adapt styles/roles. |
| Gorilla | Tool selection platform allowing LLMs to access APIs. |
| Toolformer | LLM self-learns how to use APIs by simulated interactions. |
| xLAM | Extended Language Action Modeling for tool usage. |
| τ-Bench | Benchmarking long-term policy learning in dynamic environments. |
| AutoTOD | Automated Task-Oriented Dialogue system combining planning and response. |
This taxonomy reveals key gaps: the need for more robust long-term memory, dynamic monitoring across task boundaries, and formal mechanisms for tool interaction and self-correction.
Building the Logos–Metron–Kratos Framework: Model Power and Workflow Structuring
While larger and more capable foundation models offer advantages, truly realizing the Logos–Metron–Kratos vision requires more than just scaling models. It demands a structured architectural layering combining model capabilities with systematic workflows and explicit behavioral modules.
| Pillar | What is needed | Example from Taxonomy |
|---|---|---|
| Logos (Reasoning) | - Foundation models fine-tuned for structured thinking. - Workflow modules for step decomposition and multi-path search. |
- CoT, ToT, Self-Refine. |
| Metron (Monitoring) | - Persistent state management across turns and tasks. - Self-tracking modules for awareness of goal progress and context updating. |
- SelfAware, IC-DST, CoALM. |
| Kratos (Control) | - Embedded action orchestration layers. - Built-in self-evaluation and auditing mechanisms. - Explicit tool selection and execution workflows. |
- ReAct, ToolChain, Toolformer, Gorilla, Meta-judge framework. |
Core Requirements Across All Pillars:
- Explicit memory systems beyond simple context windows.
- Reasoning-chain supervision during training, not just answer-based tuning.
- Dynamic planning interfaces that adapt goals and workflows based on monitoring feedback.
- Self-correction feedback loops built-in at action and outcome levels.
Why It’s Not Just About Bigger Models:
- Larger models can hallucinate more fluently, not more accurately.
- Without structured decomposition (Logos), state awareness (Metron), and control-feedback loops (Kratos), agent behavior remains shallow and fragile.
- A powerful but unstructured model risks becoming a “clever parrot” rather than a reliable agentic partner.
The Development Strategy:
- First, select or fine-tune models with strong reasoning primitives (e.g., CoT-enabled LLMs).
- Second, build persistent monitoring layers—dialogue and task states must survive longer than immediate contexts.
- Third, implement action-selection and self-evaluation mechanisms—embedding robustness into the control execution stack.
Control and Quality: Embedding Self-Evaluation into Agents
Achieving robust control (Kratos) requires agents to not only act but to audit and refine their outputs. A breakthrough innovation is the integration of multi-agent meta-judging frameworks.
Rather than relying on a single model’s unchecked judgment, multi-agent systems deploy several LLMs to independently assess decisions against detailed rubrics, aggregate scores, and determine output validity. This layered self-evaluation greatly enhances system reliability.
Figure 3: LLM-as-meta-judge framework. The rubric is predefined in the prompt design stage. We benchmark the judgment using N agents, each providing a score based on a rubric. These N scores are then aggregated through metric calculations to yield a comprehensive score reflecting the LLM judge’s performance.
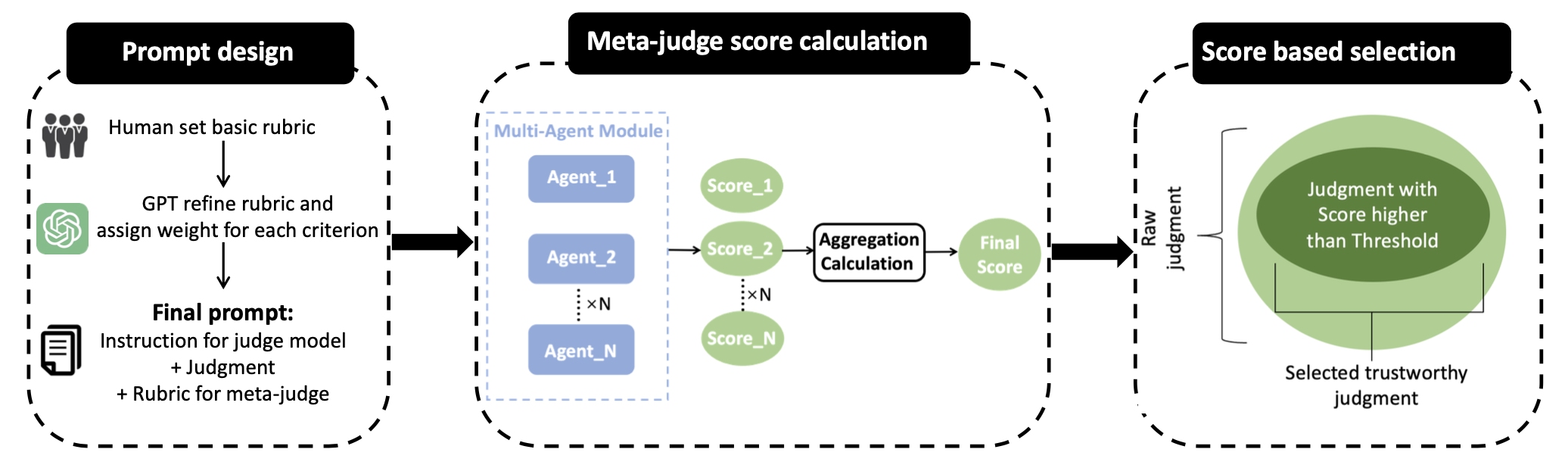
Meta-judging links directly to the “Control” pillar: agents not only initiate actions but also validate and refine their own behavior, closing the loop between action and responsibility.
Toward a New Generation of Digital Citizens
Conversational agents capable of integrating Logos, Metron, and Kratos are not merely technological advancements. They represent a necessary evolution for AI to operate reliably within human society.
This transformation will not happen by accident. It demands careful architectural thinking, continuous quality assurance, and systemic evaluation. Businesses and institutions that embrace this richer vision—building reasoning-driven, self-monitoring, quality-controlled agents—will define the next frontier of digital transformation.
Cognaptus Insights: Automate the Present, Incubate the Future