
When large language models (LLMs) learned to think step-by-step, the world took notice. Chain-of-Thought (CoT) reasoning breathed new life into multi-step arithmetic, logic, and even moral decision-making. But as multimodal AI evolved, researchers tried to bring this paradigm into the visual world — by editing images step-by-step instead of all at once.
And it failed.
In the recent benchmark study Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark1, the authors show that CoT-style image editing — what they call sequential editing — not only fails to improve results, but often worsens them. Compared to applying a single, complex instruction all at once, breaking it into sub-instructions causes notable drops in instruction-following, identity preservation, and perceptual quality.
Why does CoT thrive in language, but falter in vision? Let’s explore.
Chain-of-Thought vs. Chain-of-Edit
Language is linear. Its structure lends itself well to token-by-token reasoning. Each word builds on a prior logic, and when language models predict the next token, they draw from a stable context window that remains semantically interpretable.
Images, however, are not linear. They’re spatial, continuous, and heavily interdependent in their pixel or latent representations. In step-by-step image editing, each operation not only adds new elements but alters the canvas that future steps must interpret. Unlike tokens in a sentence, which are processed with a consistent context, an image’s edited version becomes an unstable foundation for the next operation.
To understand how this editing process is built, consider the following structured pipeline used to generate the benchmark’s dataset:
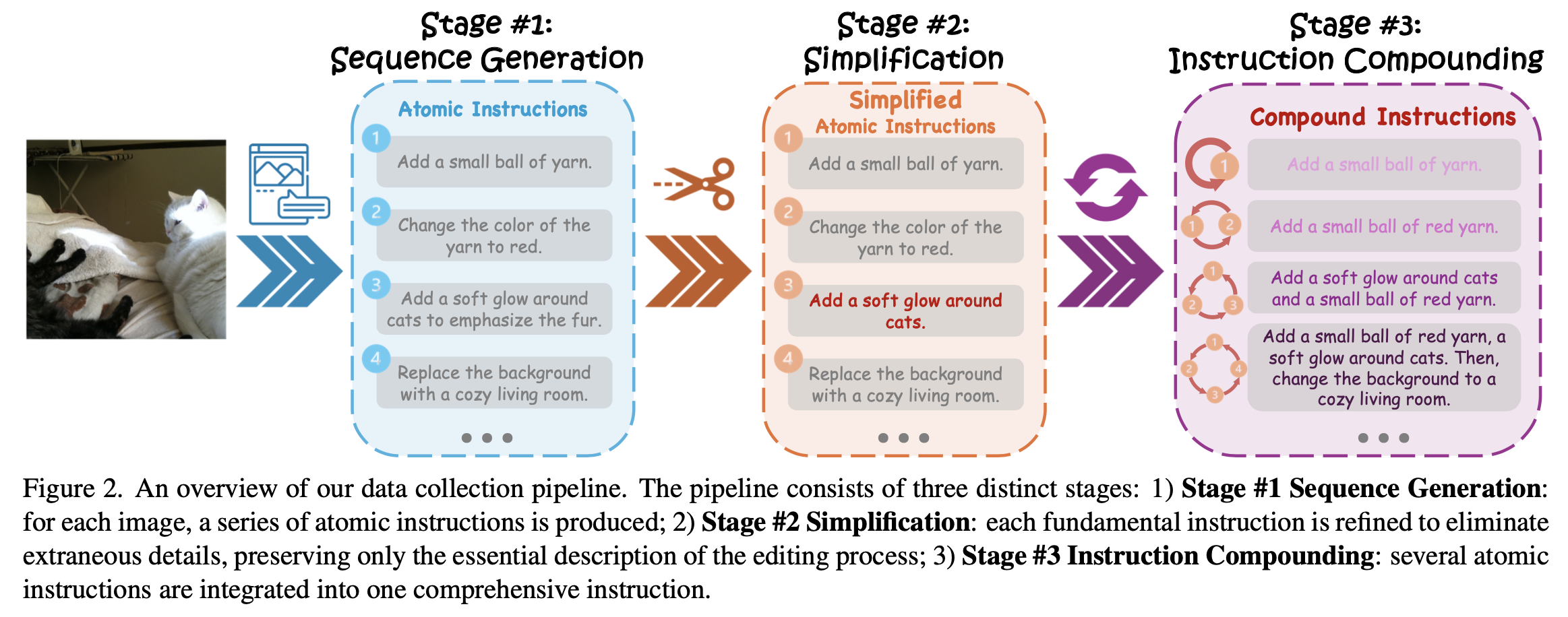
The pipeline illustrates three stages: generating atomic edits, simplifying them, and combining them into increasingly complex editing instructions. This chain-like buildup mirrors CoT in language — but in image space, its limitations quickly emerge.
We also need to understand the nature of atomic operations themselves. These aren’t just textual commands — they’re grounded in visual transformations across a broad spectrum.
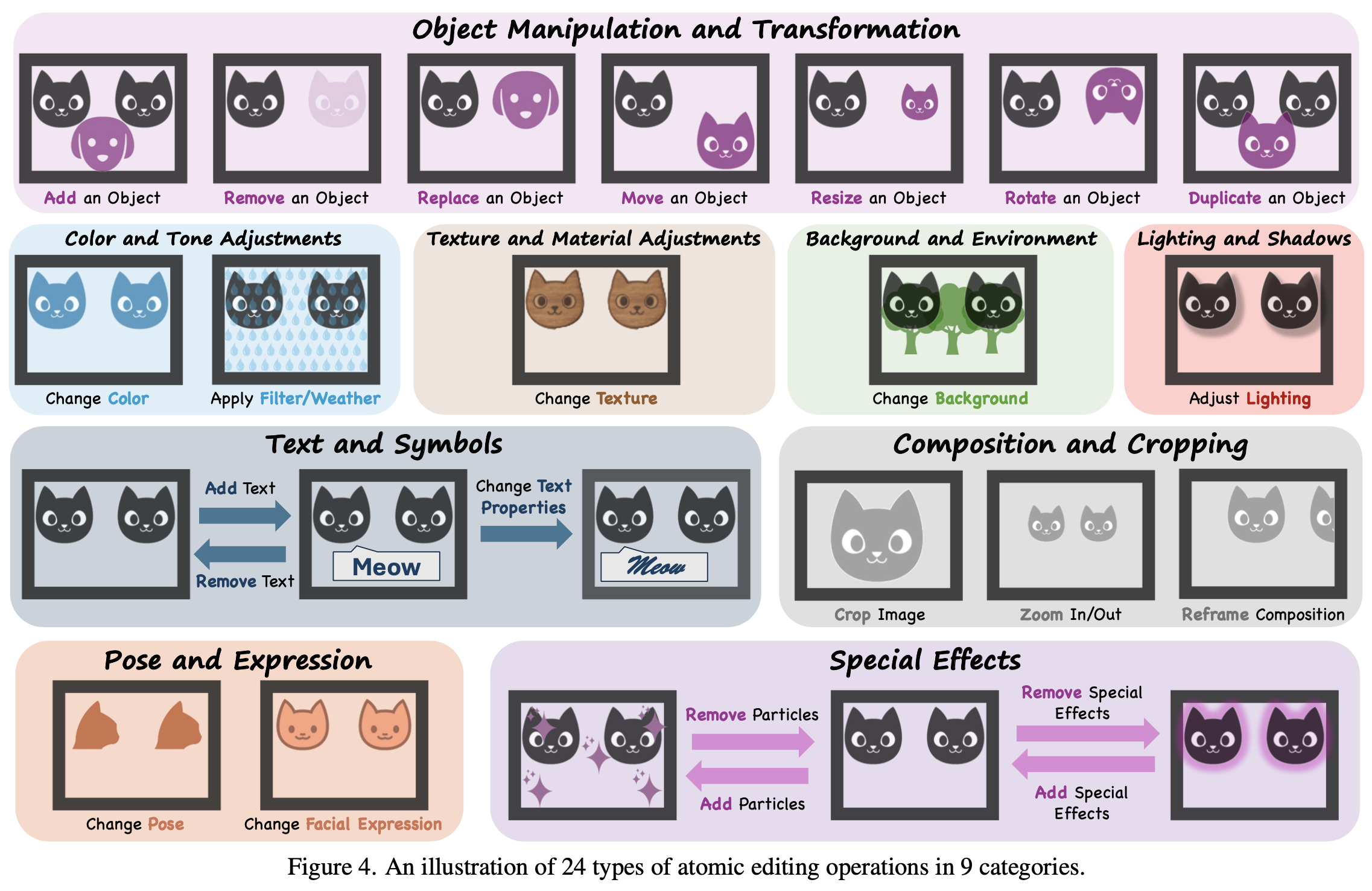
The richness of operations suggests potential, but also underscores complexity: spatial coherence, style matching, and semantic accuracy must all be preserved — even as steps stack up.
The Interdependency Problem
The failure of chain editing likely stems from a fundamental violation: image tokens are not independent after each edit. (Or more precisely, they’re interdependent in a way that resists modular reasoning.)
In language, editing one sentence doesn’t inherently scramble the grammar of the next. But in vision, editing “replace the cat with a dog” followed by “move the dog to the corner” often leads to degraded outputs. Why? Because “the dog” no longer has a clean, spatially-grounded token — it exists as a noisy artifact, sometimes not even distinguishable from its background.
Sequential operations amplify this: each step makes the image a bit less coherent, which cascades into identity loss and poor realism. The authors of Complex-Edit evaluated these effects using a rigorous VLM-based framework.

For perceptual realism — how “natural” or artifact-free the image looks — a different scoring angle is used:

Even in these visual metrics, degradation correlates strongly with step count. In other words, the longer the edit chain, the worse the model’s ability to preserve fidelity.
The Curse of Synthetic Data
But there’s another ghost haunting step-by-step editing: the curse of synthetic data.
When AI models are trained heavily on synthetic image-text pairs — which is common in diffusion-based editing pipelines — they tend to overfit to idealized aesthetics. In simple edits, this bias isn’t obvious. But with complex or chained edits, the model can’t preserve realism. Outputs begin to look painted, airbrushed, or outright surreal.
Our preliminary evaluation of GPT-4o, as detailed in the benchmark, reveals its vulnerability to this very issue.

Even GPT-4o begins to lose realism at complexity level 8 — the highest in the benchmark — producing images that resemble stylized artwork more than edited photography.
The performance dip isn’t exclusive to proprietary models. A broader comparison between complexity levels shows a consistent downward trend across the board:
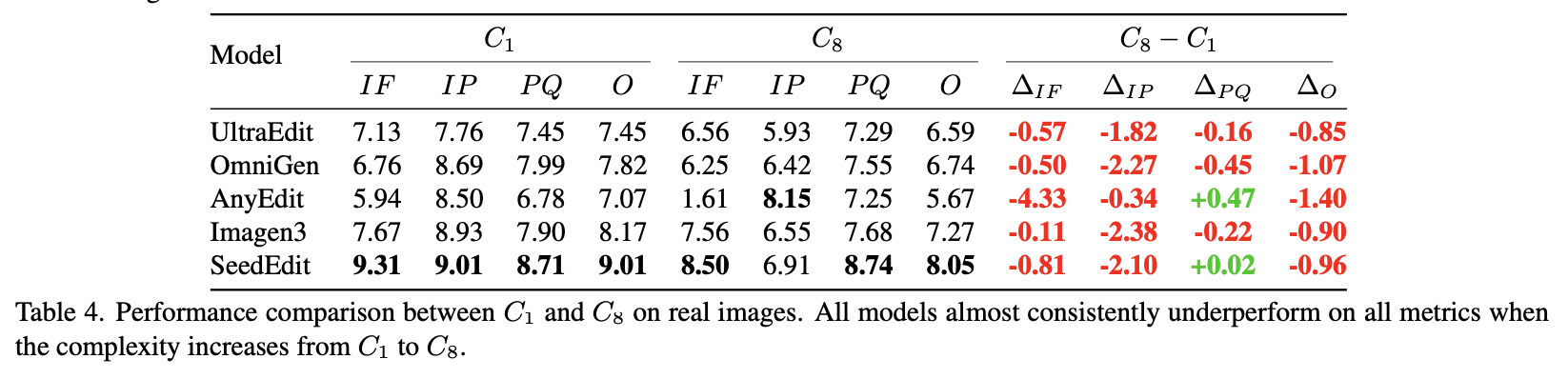
And when the same is tested on synthetic images instead of real photos, the drop in perceptual quality and identity preservation remains.
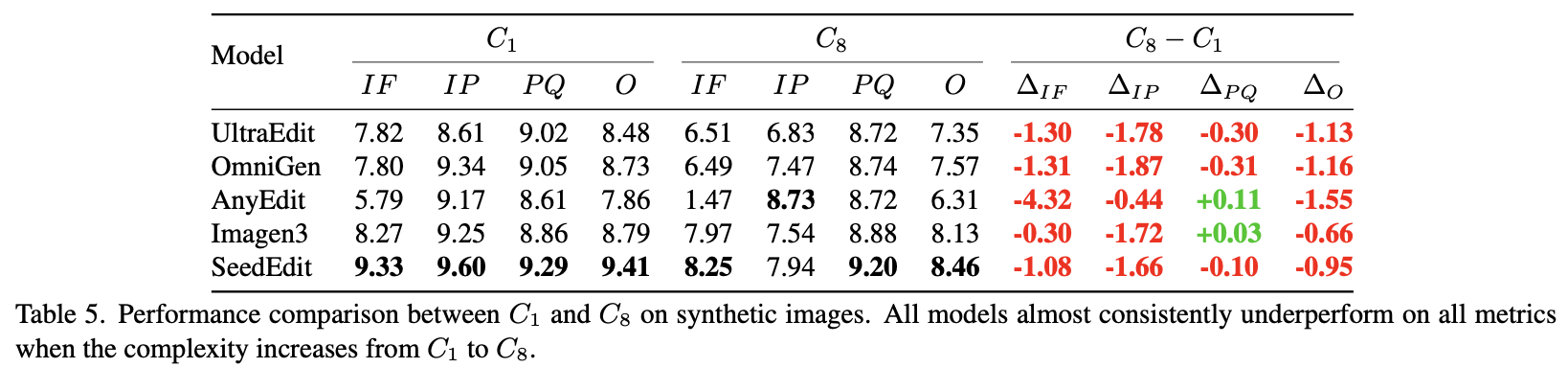
Are There Fixes?
Researchers in Complex-Edit experimented with test-time techniques like Best-of-N selection and more robust scoring rubrics. While these helped in some cases, they did not resolve the core limitations of chained editing.
More fundamental solutions may require:
- Real-world editing data, not just synthetic generations
- Editing-aware architectures with memory of past objects and scene layouts
- Style-preservation constraints during training and inference
Until then, the lesson is clear: instruct once, edit once.
Final Thoughts
Chain-of-Thought works because text is modular, symbolic, and context-resilient. Images are none of those things. When we try to “think like language” in a medium that is noisy, spatial, and entangled, our best generative models start to slip.
The vision of an intelligent visual editor that reasons like a writer is still distant — and it may need very different principles to get there.
This limitation is not just a theoretical concern. It has real implications for business process automation (BPA), especially in sectors where visual content is central. Marketing is the most obvious: campaign asset generation, A/B testing visuals, or seasonal product mockups all increasingly rely on text-to-image AI workflows. But other domains also stand to gain or suffer:
- E-commerce: automated product photography adaptation (color variants, layout changes, localization).
- Architecture & Real Estate: virtual staging, remodeling previews, or contextual changes based on buyer personas.
- Retail Planning: visual planogram testing, shelf layout edits, or store walkthrough simulations.
- Manufacturing & Design: prototyping through visual iteration, label redesigns, or safety signage personalization.
If these workflows rely on step-by-step instruction chaining, the degradation in visual quality, realism, and instruction fidelity can erode trust — or require expensive human touch-up.
So while text-based CoT will continue to power LLM-based planning, analysis, and strategy, visual BPA needs caution. Instruction-based image editing still has a long way to go before it can be reliably chained in a business pipeline.
Cognaptus: Automate the Present, Incubate the Future.
-
Siwei Yang, Mude Hui, Bingchen Zhao, Yuyin Zhou, Nataniel Ruiz, Cihang Xie. “Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark” (2025). https://arxiv.org/abs/2504.13143 ↩︎