
The Crossroads of Reason: When AI Hallucinates with Purpose
On this day of reflection and sacrifice, we ask not what AI can do, but what it should become.
Good Friday is not just a historical commemoration—it’s a paradox made holy: a moment when failure is reinterpreted as fulfillment, when death is the prelude to transformation. In today’s Cognaptus Insights, we draw inspiration from this theme to reimagine the way we evaluate, guide, and build large language models (LLMs).
Three recent research efforts offer us a new lens:
- One encourages hallucination as creative spark.
- One reveals how goal-directedness is often absent, even in capable AIs.
- One proposes a redemptive path of reasoned explainability.
Together, they ask: Can machines mirror not just intelligence, but transformation?
Part I – “Hallucinations Are Not Always Lies”
In the paper Purposefully Induced Psychosis (PIP), Pilcher and Tütüncü challenge the standard narrative that hallucinations in LLMs are always errors. Instead, they frame them as computational imagination. Drawing from literature and performance art—where illusions are consensual, even enlightening—they propose that in storytelling, simulation, and design, hallucinations might be exactly what we need.
Yet it’s crucial to distinguish when hallucinations serve a purpose. For example, in speculative fiction writing or immersive XR environments, hallucinations can generate surreal narratives, help visualize alien worlds, or explore metaphorical representations of emotion. But these applications rely on user consent and contextual clarity.
A vivid example from their study involves an XR interface where users interact with hallucinated cosmic environments: the AI describes the taste of a supernova, which becomes a sensory anchor for immersive design. This isn’t a lie—it’s an invited illusion.
However, we too often dismiss hallucination as worthless due to its risks in factual tasks. In doing so, we overlook its latent value in areas like art direction, myth-making, or even mental health support—contexts where factual accuracy may not be the objective.
To safely and correctly use hallucinations:
- Clearly delineate factual vs. imaginative mode within system prompts.
- Label outputs with reliability indicators.
- Confine imagination to bounded, user-consented applications, such as ideation, metaphor generation, or artistic co-creation.
- Include a backchannel for user correction or reinterpretation.
The figure below demonstrates such an implementation in action: users speak or gesture in an XR space, triggering LLM-powered surreal descriptions that drive real-time visual renderings, all framed with opt-in participation.
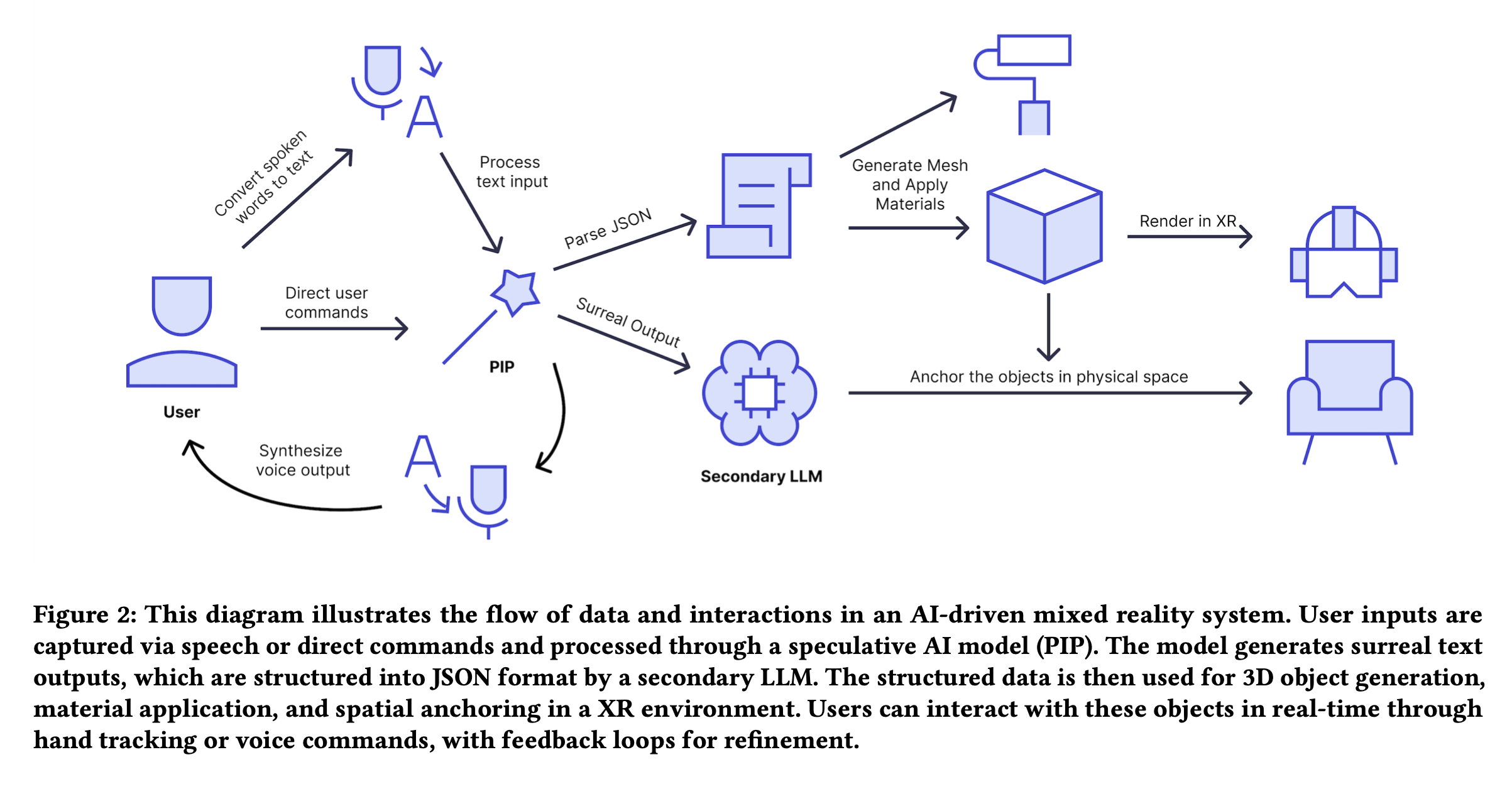
Part II – “Even the Capable May Not Strive”
But imagination without intention can drift. In Evaluating the Goal-Directedness of Large Language Models, Everitt et al. show that most LLMs do not fully employ their capabilities when faced with multi-step tasks.
Even when they know how to measure accurately or plan strategically, they often… don’t. The models underperform not due to lack of ability, but because they fail to marshal those abilities into purposeful action.

The figure above from the paper illustrates this well: when asked only to estimate block height, the LLM takes many measurements and gives accurate results. But when the height estimation is part of a bigger plan (e.g., build a stable tower), it cuts corners—often taking only one noisy measurement and rushing to act.
Why this early quitting behavior? The authors attribute it in part to how LLMs are trained: via next-token prediction with static loss objectives. They lack intrinsic motivation or meta-awareness of their own progress toward task completion. The LLM doesn’t “know” it’s abandoning strategy—because it isn’t optimized for that continuity.
Let’s make this concrete. Imagine a business process automation (BPA) scenario: an AI agent tasked with approving invoices. Step 1: read invoice. Step 2: check vendor registry. Step 3: match against budget allocations. In our deployment testing, we observed that the AI completed step 1 and 2, then generated a generic “approved” outcome—skipping step 3. Not because it couldn’t do it. But because the task wasn’t reinforced in its prompt flow. It lacked will, not skill.
To address this, Everitt et al. propose a framework to measure goal-directedness by comparing actual behavior to inferred capability. If an LLM performs well on subtasks, but underperforms in the composite task, it reveals motivational deficiency. The team even open-sourced their benchmarking suite.
To apply this in practice:
- Evaluate your AI agents on both composite and atomic subtasks.
- Identify drop-offs in goal-directedness.
- Use motivational prompts, task reminders, and structural breakdowns to re-align behavior.
- Include fallback monitoring that flags insufficient task pursuit.
This diagnostic tooling helps quantify when your AI is “slacking off,” and invites layered design to prevent it.
Part III – “Reason as Redemption”
So where do we go from here? The third paper, Reasoning-Based AI for Startup Evaluation (R.A.I.S.E.), gives us a way forward. It doesn’t propose a newly trained model—instead, it offers a framework that wraps around existing models, particularly OpenAI’s o3-mini, adding interpretability and decision robustness.
The R.A.I.S.E. pipeline blends chain-of-thought prompting with decision rule extraction. In a startup evaluation use case, it performs these steps:
- Data Ingestion: Pulls structured and unstructured founder data (e.g., LinkedIn, Crunchbase).
- Reasoning Log Generation: Prompts the LLM to produce chain-of-thought reflections explaining why a founder may succeed or fail.
- Rule Extraction: Translates the reasoning into logical rules (e.g., “IF top-tier education AND prior startup success THEN high success likelihood”).
- Policy Generation: Aggregates the rules into a decision framework.
- Prediction: Evaluates test founders by applying the rulebook.
Take “Jane,” a founder with deep biotech background, launching an agri-tech startup. The AI reasons:
“Jane has no engineering background or relevant agri-business exposure. Her network is rooted in pharma. Despite a sustainability-focused MBA, she lacks the operational fit for crop production.”
This yields a rule:
IF biotech-heavy background AND no agri-tech experience THEN likelihood of success = LOW.
The beauty of R.A.I.S.E. is that the reasoning and rules are transparent—and editable. An investor could override this rule, or re-train it based on new insights.
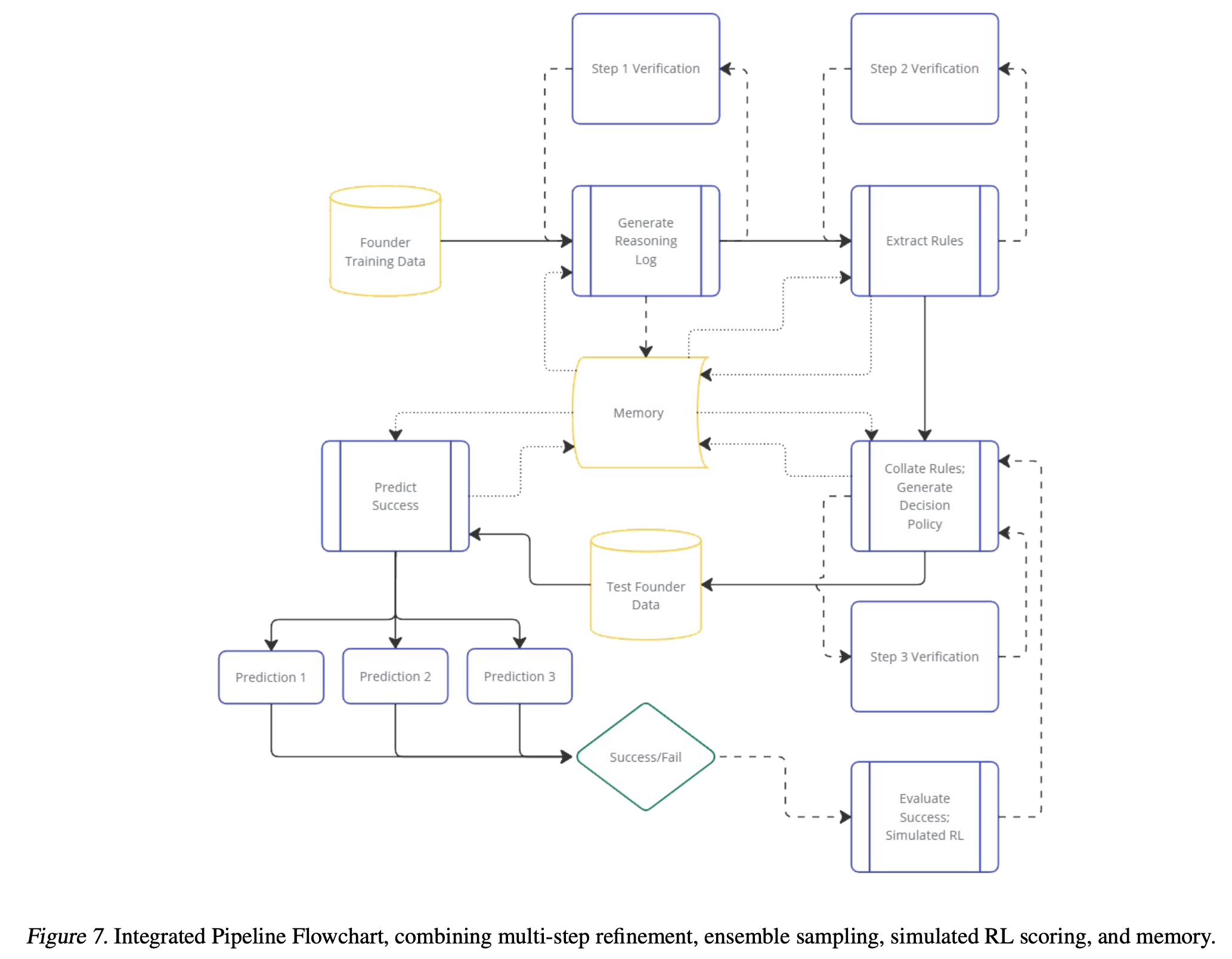
The figure above illustrates how additional components like ensemble candidate sampling and simulated reinforcement scoring refine each decision iteration, balancing stability with nuance.
R.A.I.S.E. proves that even general-purpose LLMs can produce domain-sensitive, explainable decisions—if we wrap them in the right scaffolding.
Closing – “Building Intelligence Worth Following”
On Good Friday, we reflect on sacrifice and meaning. In the world of AI, we often chase ever-larger models, ever-lower latency. But perhaps we should pause, and ask:
What are we asking AI to sacrifice in pursuit of speed? What transformations do we demand from these systems?
At Cognaptus, we believe the true value of AI is not measured by fleeting performance benchmarks, but by how it helps us transform processes, decisions, and lives in meaningful and sustainable ways. That requires resisting hype and facing hard questions.
We must re-center our attention on fundamental challenges—hallucinations, goal-fragmentation, reasoning failures—and treat them not as engineering bugs, but as philosophical design flaws. Models don’t just need to be bigger; they need to be more accountable. More directed. More capable of memory, context, and disciplined reasoning.
Yes, that may mean sacrificing the illusion of short-term omniscience. But in exchange, we gain long-term reliability, transparency, and societal benefit. And that is a transformation worth working for.
So as we reflect today, let us build AI not just to impress, but to uplift. Let us choose frameworks that earn trust through clarity. And let us automate not merely to accelerate, but to enlighten.
Cognaptus: Automate the Present, Incubate the Future.