
The next generation of quantitative investment agents must be more than data-driven—they must be logic-aware and structurally adaptive. Two recently published research efforts provide important insights into how reasoning patterns and evolving workflows can be integrated to create intelligent, verticalized financial agents.
- Kimina-Prover explores how reinforcement learning can embed formal reasoning capabilities within a language model for theorem proving.
- Learning to Be a Doctor shows how workflows can evolve dynamically based on diagnostic feedback, creating adaptable multi-agent frameworks.
While each stems from distinct domains—formal logic and medical diagnostics—their approaches are deeply relevant to two classic quant strategies: the Black-Litterman portfolio optimizer and a sentiment/technical-driven Bitcoin perpetual futures trader.
How Quantitative Investment Systems Work—and Why They Break
In practice, most quant teams build pipelines that can be loosely divided into:
- Signal generation
- Risk modeling
- Portfolio construction
- Execution
|
Below is a high-level workflow of a traditional top-down portfolio strategy using the Black-Litterman framework: |
Another example, for Bitcoin perpetual futures strategy using technical signals and news sentiment: |

|

|
Pain Point 1: Hard-coded workflows can’t adapt to market regime shifts
In the Black-Litterman example, a macroeconomic shift (e.g., inflation surprise) might invalidate previous expert views, but the workflow continues to allocate as if the old assumptions hold. Without feedback mechanisms, such workflows miss key inflection points.
In the Bitcoin case, technical indicators tuned on past volatility regimes become irrelevant when a sudden regulation shift or whale liquidation distorts typical patterns.
Pain Point 2: Strategies are black boxes, making it hard to audit decisions
A portfolio manager using the top-down strategy may be unable to trace why the optimizer chose a particular weight—especially when combining subjective views. Without transparency, it’s difficult to explain to investment committees.
For crypto trades, automated entries triggered by obscure sentiment signals may leave no trace of reasoning—raising risk management concerns.
Pain Point 3: Updating models requires rewiring the pipeline
Switching from Black-Scholes to rough volatility modeling in a structured derivatives workflow often means rewriting core functions, testing compatibility, and manually debugging.
In the BTC example, if a new sentiment source (like Reddit) is added, the pipeline logic needs to be extended—without disrupting existing modules. This is fragile and time-consuming.
Pain Point 4: Data inconsistencies propagate downstream silently
Missing yield curves or stale price feeds can bias the entire Black-Litterman optimization without triggering alarms. Errors propagate without visibility.
In the crypto case, a misclassified sentiment score can lead to trades in the wrong direction—yet the trade history would appear “valid” unless deeper analysis is performed.
From Lean Proofs to Valuation Chains: Reasoning as a Financial Primitive
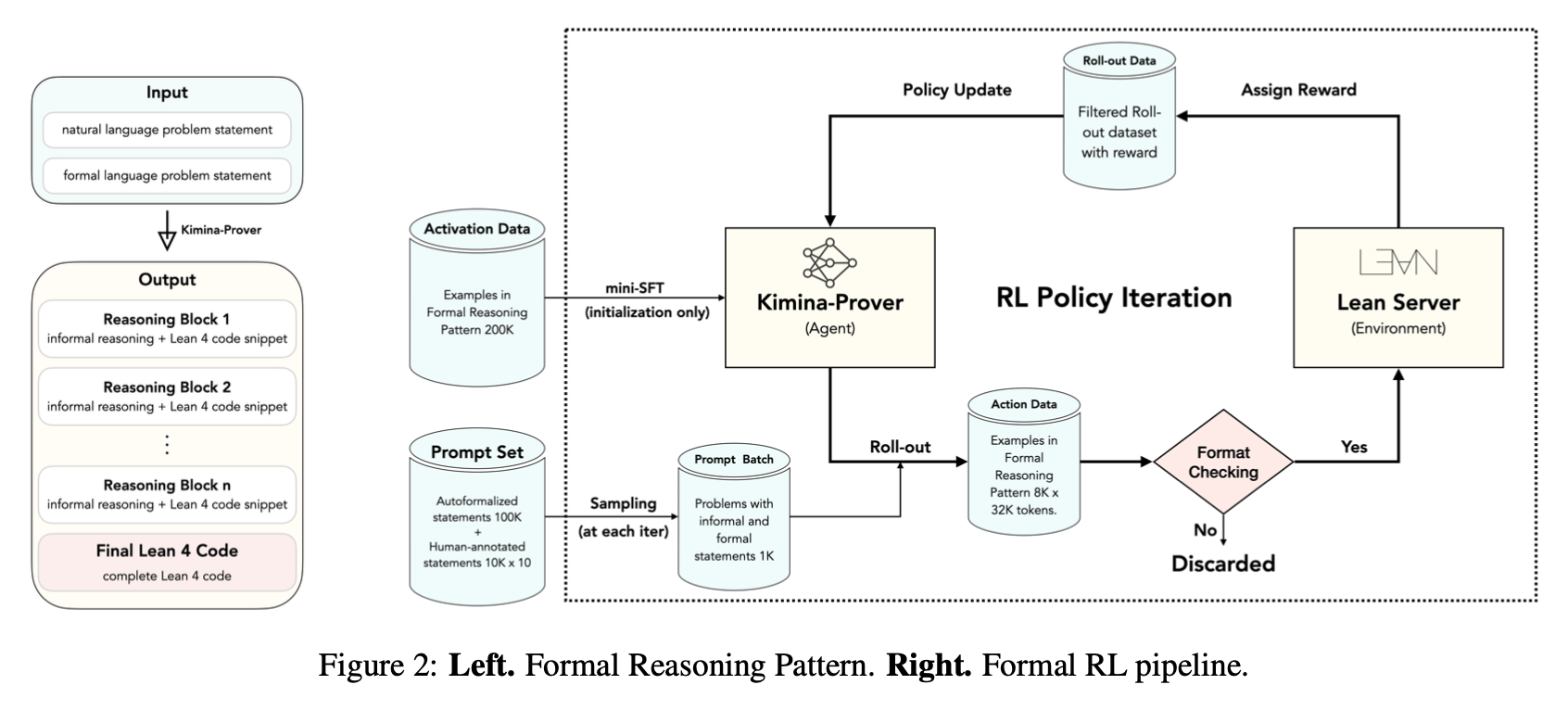
Kimina-Prover’s approach centers around embedding a structured reasoning format inside the model using reinforcement learning. It introduces a token pattern like:
<think>
"Volatility is unusually skewed due to event risk."
</think>
<code>
switch_model(local_vol)
</code>
The reward system evaluates not just correctness of the proof, but whether the reasoning trace leads to successful outcomes. In Lean 4, this is a binary judgment—proof passes or fails. In simple terms: it’s like checking not just whether the final math answer is right, but also if the steps the student used to solve it were logical and helpful. If the reasoning path usually leads to success, it gets rewarded.
Translating this to quant:
- In the Black-Litterman pipeline, the model might be rewarded if its thought process about interest rate shifts leads to improved Sharpe.
- In Bitcoin futures, a correct reasoning trace linking news to expected volatility could be reinforced during backtesting.
These “reasoning traces” help construct audit trails and allow reinforcement systems to associate valid reasoning chains with successful financial outcomes.
Such an approach could support a future where portfolio optimizers explain their risk views, or crypto trading bots write down their logic in interpretable form—making review, debugging, or even compliance easier.
From Static Scripts to Adaptive Graphs: Modular Workflow Learning for Finance
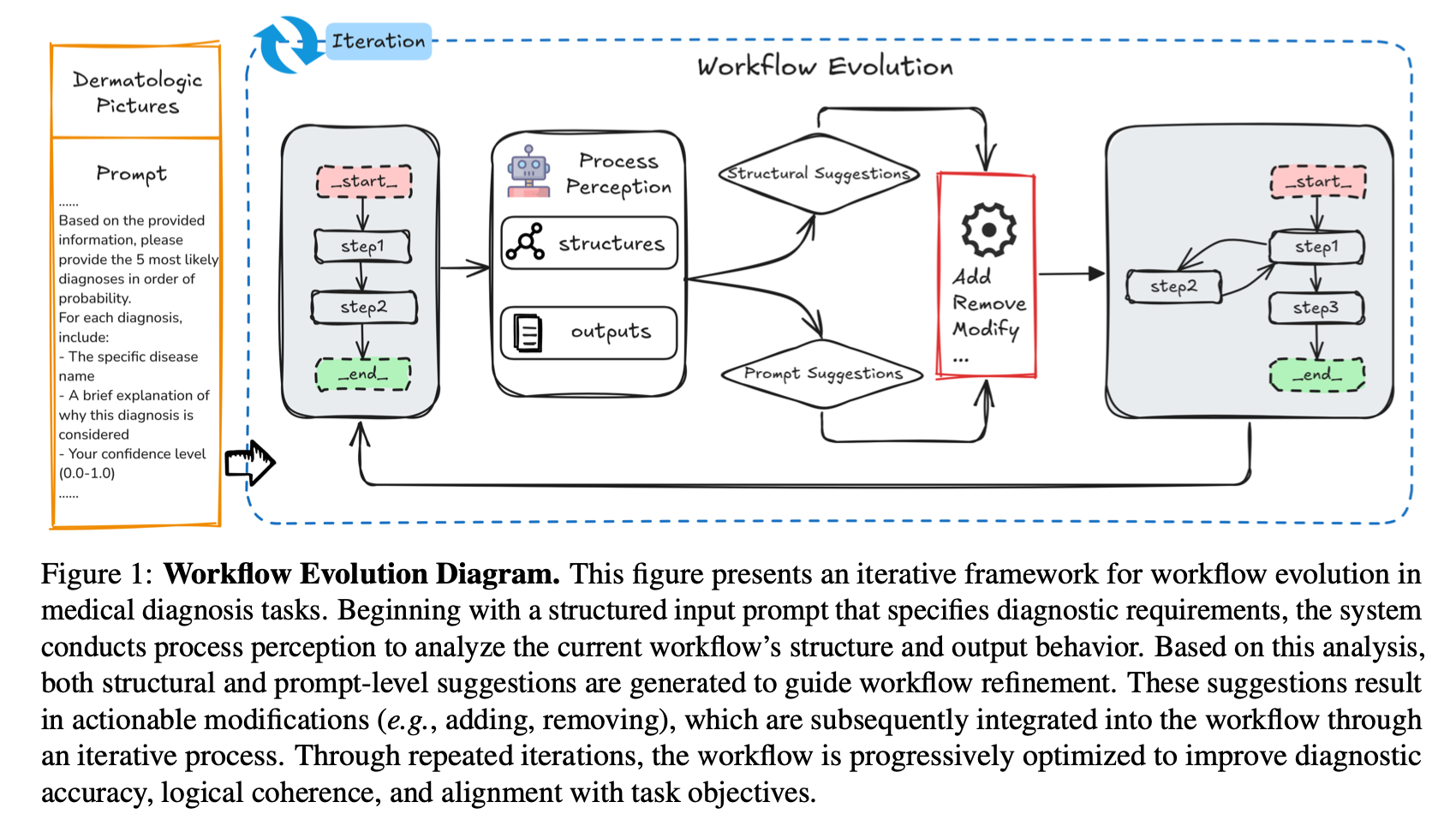
“Learning to Be a Doctor” reframes the workflow as a modifiable graph. Instead of hard-coded decision trees, nodes evolve via operations like add/modify/loop/branch.
This is particularly relevant for quant workflows. For instance:
- In the Black-Litterman setup, a node could monitor macro signals for contradiction. If it detects a divergence between expected and actual inflation paths, it adds a loop to test alternative optimizers (e.g., max drawdown-constrained rather than pure Sharpe).
- In the BTC futures system, if sentiment and price diverge sharply, a conditional branch could be inserted to downweight sentiment temporarily, or to switch to pure price action logic.
Such structures not only improve performance but also allow live feedback to alter the topology of a strategy. Instead of hard-coded responses, workflows evolve—similar to how an experienced trader refines their playbook over time.
How does this evolution happen?
In practice, we add a meta-layer above the existing graph, responsible for observing performance metrics (like drop in Sharpe ratio, high drawdown, model disagreement, or exception logs). Based on pre-configured or learned triggers, this layer can apply evolution operators (add/replace/loop/prune nodes).
Professionally speaking, this is similar to AutoML for workflows: the system searches through different architectural options and applies the one that improves diagnostic or financial metrics. In everyday terms, imagine a trader who, after three bad trades, says “maybe I should check news sentiment before acting on MACD” — and the system adds that check itself.
Bridging the Two: Toward Verticalized Agents in Quant Finance
The real opportunity lies in combining the two directions:
- Kimina’s reasoning-driven formatting and RL alignment gives models a way to explain decisions.
- The medical agent’s modular workflow model allows agents to restructure their behavior dynamically.
For the Black-Litterman framework, this means an agent that:
- Diagnoses mismatches between expert views and market behavior
- Explains why it shifts from Sharpe-optimal to risk-constrained logic
- Logs the rationale behind every allocation decision
For BTC perpetual trading:
- Explains why a breakout signal was ignored due to conflicting Reddit momentum
- Automatically inserts a volatility filter if price whipsaws on Fed news
- Records its reasoning trace and pipeline edits for every trade
This convergence enables quant systems to become not just “smart,” but “self-aware”—and traceable.
| Use Case | Reasoning-Driven Element | Workflow-Evolving Element |
|---|---|---|
| Black-Litterman Allocator | Thought process explaining view integration | Dynamic optimizer switching based on macro diagnostics |
| BTC Futures Trader | Justifies trade decisions using sentiment + technicals | Auto-switches filters/models when signal conflict is high |
| Audit Report Generator | Structured explanation tree for every decision | Automatically includes rationale changes per evolution step |
| Research Agent | Chains informal-to-formal hypothesis refinement | Adds self-loop nodes to revise conclusion under constraints |
Applications We Can Build Today
- Trade Structuring Assistant
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Black-Scholes payoff simulation for call spread
S = np.linspace(1000, 3000, 200)
K1, K2 = 1800, 2200 # lower and upper strikes
premium1, premium2 = 80, 40 # paid and received premiums
payoff = np.maximum(S - K1, 0) - premium1 - (np.maximum(S - K2, 0) - premium2)
plt.plot(S, payoff, label="Call Spread PnL")
plt.axhline(0, linestyle='--', color='gray')
plt.xlabel("Underlying Price")
plt.ylabel("PnL")
plt.title("Option Call Spread Structure")
plt.legend()
plt.grid()
plt.show()
- Volatility Regime Advisor
import yfinance as yf
import pandas as pd
from statsmodels.tsa.stattools import adfuller
btc = yf.download('BTC-USD', start='2023-01-01', end='2024-01-01')
returns = btc['Adj Close'].pct_change().dropna()
volatility = returns.rolling(window=10).std()
skew = returns.rolling(window=10).skew()
kurt = returns.rolling(window=10).kurt()
signal = "rough_vol" if (kurt.iloc[-1] > 3 and skew.iloc[-1] > 0.5) else "local_vol"
print(f"Last 10-day Skew: {skew.iloc[-1]:.2f}, Kurtosis: {kurt.iloc[-1]:.2f}")
print(f"Chosen Model: {signal}")
- Auto-Risk Committee
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
texts = [
"BTC is showing weakness despite ETF approval.",
"Recent on-chain data indicates potential inflow spike.",
"Fed decision likely to create volatility this week."
]
votes = []
for text in texts:
result = sentiment_pipeline(text)[0]
if result['label'] == 'POSITIVE' and result['score'] > 0.8:
votes.append("buy")
elif result['label'] == 'NEGATIVE' and result['score'] > 0.8:
votes.append("sell")
else:
votes.append("hold")
print("Committee Votes:", votes)
from collections import Counter
print("Decision:", Counter(votes).most_common(1)[0][0])
- Audit-First Research Generator
import json
research_log = {
"macro_signal": "US CPI YoY came in above expectations.",
"llm_reasoning": [
"Inflation surprise likely increases Fed hawkishness",
"Risk-off flows into USD, out of crypto",
"BTC likely to face headwinds"
],
"trade_response": {
"instrument": "BTCUSDT Perp",
"action": "Reduce Long",
"size_pct": -0.25,
"hedge_ratio": 0.5
}
}
with open("audit_btc_strategy.json", "w") as f:
json.dump(research_log, f, indent=2)
print("Audit log written to audit_btc_strategy.json")
Final Thought: Not Just Smarter, but More Structured
The next leap in financial AI won’t just come from bigger models. It will come from structured architectures and reflective feedback loops—blending fine-tuned logic and workflow evolution into agents that can reason, adapt, and act.
That’s how agents grow up—not just in IQ, but in institutional fit.
Cognaptus: Automate the Present, Incubate the Future.