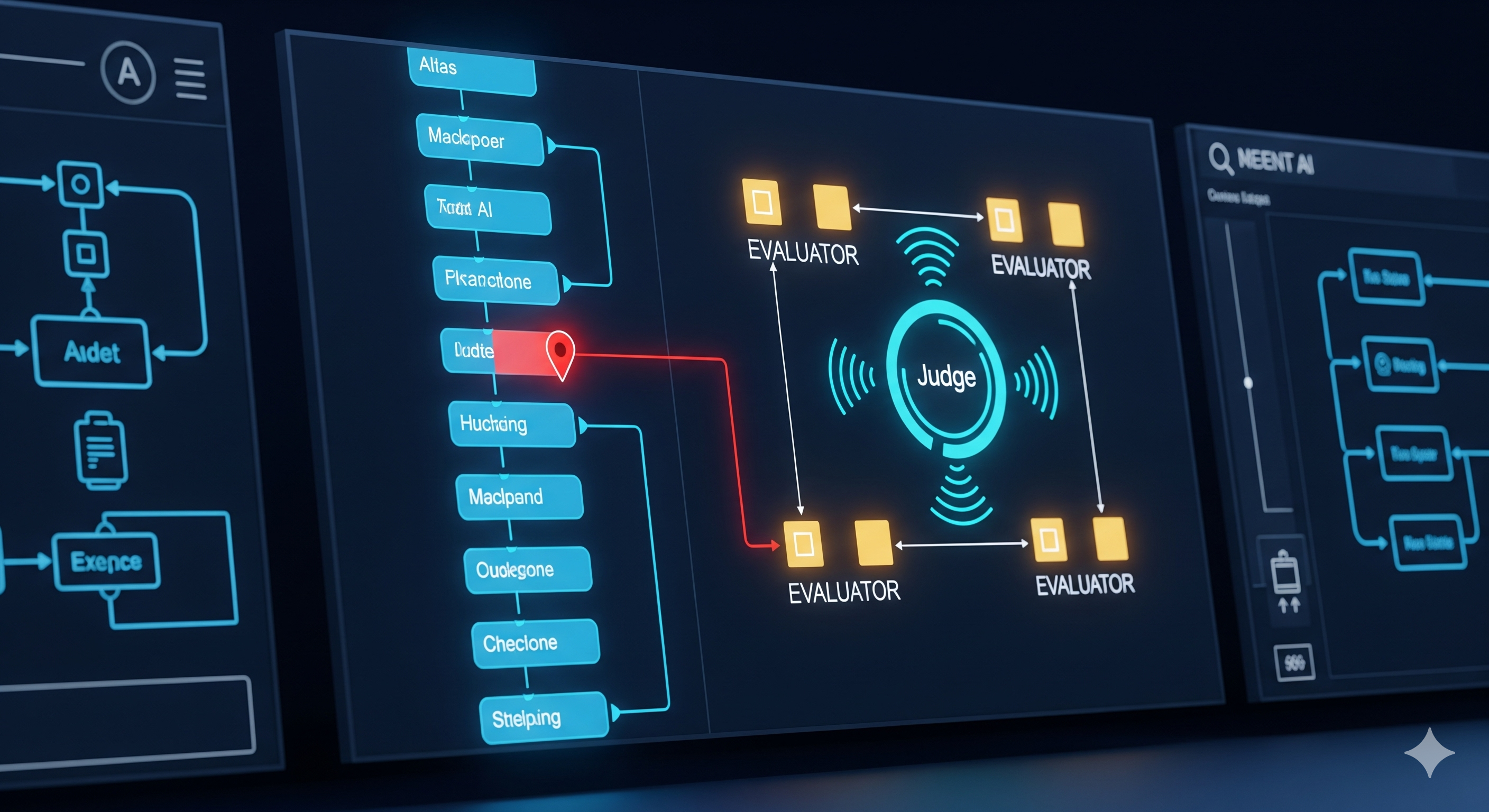
Fault Lines & Safety Nets: How RAFFLES Finds the First Domino in Agent Failures
TL;DR Most LLM agent evaluations judge the final answer. RAFFLES flips the lens to where the first causal error actually happened—then iterates with a Judge–Evaluator loop to verify primacy, fault-ness, and non-correction. On the Who&When benchmark, RAFFLES materially outperforms one-shot judges and router-style baselines. For builders, this is a template for root-cause analytics on long-horizon agents, not just scorekeeping. Why we need decisive-fault attribution (not just pass/fail) Modern agent stacks—routers, tool-callers, planners, web surfers, coders—fail in cascades. A harmless-looking plan choice at t=3 can doom execution at t=27. Traditional “LLM-as-a-judge”: ...