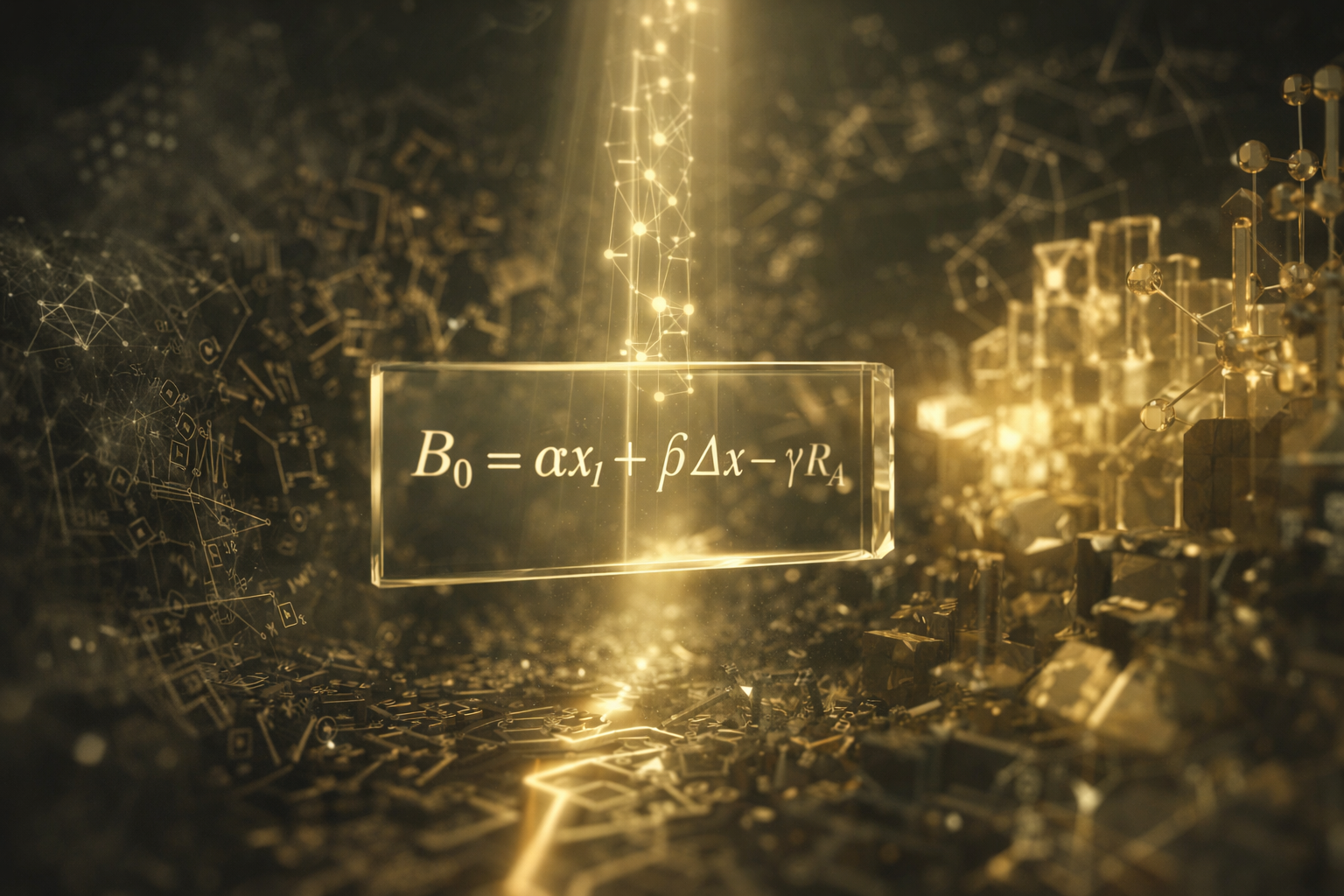Wrong on Purpose: FalsifyBench and the Agent Skill We Keep Forgetting
A good analyst should occasionally try to break their own idea. Not performatively. Not with a decorative “on the other hand” paragraph. Actually break it. Ask the kind of question that could make the current hypothesis collapse, then watch whether the evidence forces a better one. That simple discipline is the center of FalsifyBench: Evaluating Inductive Reasoning in LLMs with Rule Discovery Games, a new paper by Leonardo Bertolazzi, Katya Tentori, and Raffaella Bernardi.1 The paper is framed around scientific reasoning, but its practical message travels well beyond science. If an AI agent cannot test outside its own current belief, it may look careful while doing something much less impressive: confirming the first plausible story it invented. ...