Anonymize Customer Data with AI
How to use AI to detect and redact sensitive customer information while understanding the limits of automated anonymization.
How to use AI to detect and redact sensitive customer information while understanding the limits of automated anonymization.
What a private LLM deployment means in practice, when it makes sense, and how to evaluate the operational trade-offs beyond simple privacy slogans.
A plain-English guide to deciding which business data should not be sent to public LLM endpoints and what safer alternatives exist.

Opening — Why this matters now “Right to be forgotten” has quietly become one of the most dangerous phrases in AI governance. On paper, it sounds clean: remove a user’s data, comply with regulation, move on. In practice, modern large language models (LLMs) have turned forgetting into a performance art. Models stop saying what they were trained on—but continue remembering it internally. ...

Opening — Why this matters now RAG was supposed to make LLMs safer. Instead, it quietly became a liability. As enterprises rushed to bolt retrieval layers onto large language models, they unintentionally created a new attack surface: sensitive internal data flowing straight into a model that cannot reliably distinguish instructions from content. Prompt injection is not a corner case anymore—it is the default threat model. And telling the model to “behave” has proven to be more of a suggestion than a guarantee. ...

Opening — Why this matters now Multimodal models have learned to see. Unfortunately, they have also learned to remember—and sometimes to reveal far more than they should. As vision-language models (VLMs) are deployed into search, assistants, surveillance-adjacent tools, and enterprise workflows, the question is no longer whether they can infer personal information from images, but how often they do so—and under what conditions they fail to hold back. ...

Opening — Why this matters now Personalized AI assistants are rapidly becoming ambient infrastructure. They draft emails, recall old conversations, summarize private chats, and quietly stitch together our digital lives. The selling point is convenience. The hidden cost is context collapse. The paper behind this article introduces PrivacyBench, a benchmark designed to answer an uncomfortable but overdue question: when AI assistants know everything about us, can they be trusted to know when to stay silent? The short answer is no—not reliably, and not by accident. ...

Centralized Retrieval-Augmented Generation (RAG) systems promise smarter answers, but they quietly assume one big, clean dataset in one place. Reality is far messier: hospitals, insurers, or financial groups each hold their own silo, often in incompatible formats, and none are willing—or legally allowed—to pool raw data. The HyFedRAG framework tackles this head‑on by making RAG federated, heterogeneous, and privacy‑aware. Edge First, Cloud Second Instead of centralizing records, HyFedRAG runs retrieval at the edge. Each hospital or business unit: ...

The latest tutorial by Li, Huang, Li, Zhou, Zhang, and Liu surveys how GANs, diffusion models, and LLMs now mass‑produce synthetic text, tables, graphs, time series, and images for data‑mining workloads. That’s the supply side. The demand side—execs asking “will this improve my model and keep us compliant?”—is where most projects stall. This piece extracts a decision framework from the tutorial and extends it with business‑grade evaluation and governance so you can decide when synthetic data is a shortcut—and when it’s a trap. ...
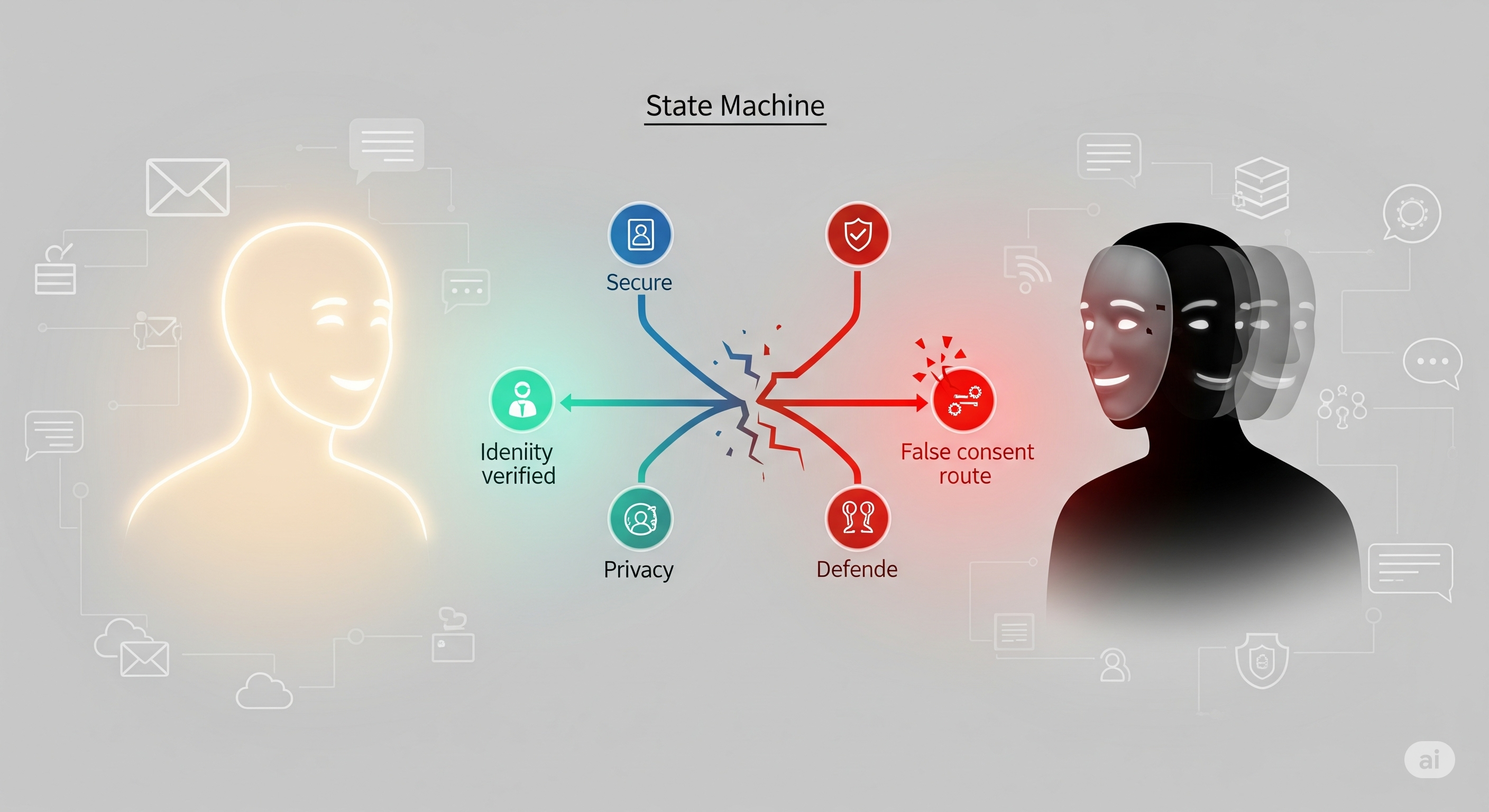
When organizations deploy LLM-based agents to email, message, and collaborate on our behalf, privacy threats stop being static. The attacker is now another agent able to converse, probe, and adapt. Today’s paper proposes a simulation-plus-search framework that discovers these evolving risks—and the countermeasures that survive them. The result is a rare, actionable playbook: how attacks escalate in multi-turn dialogues, and how defenses must graduate from rules to identity-verified state machines. ...