Bias, Baked In: Why Pretraining, Not Fine-Tuning, Shapes LLM Behavior
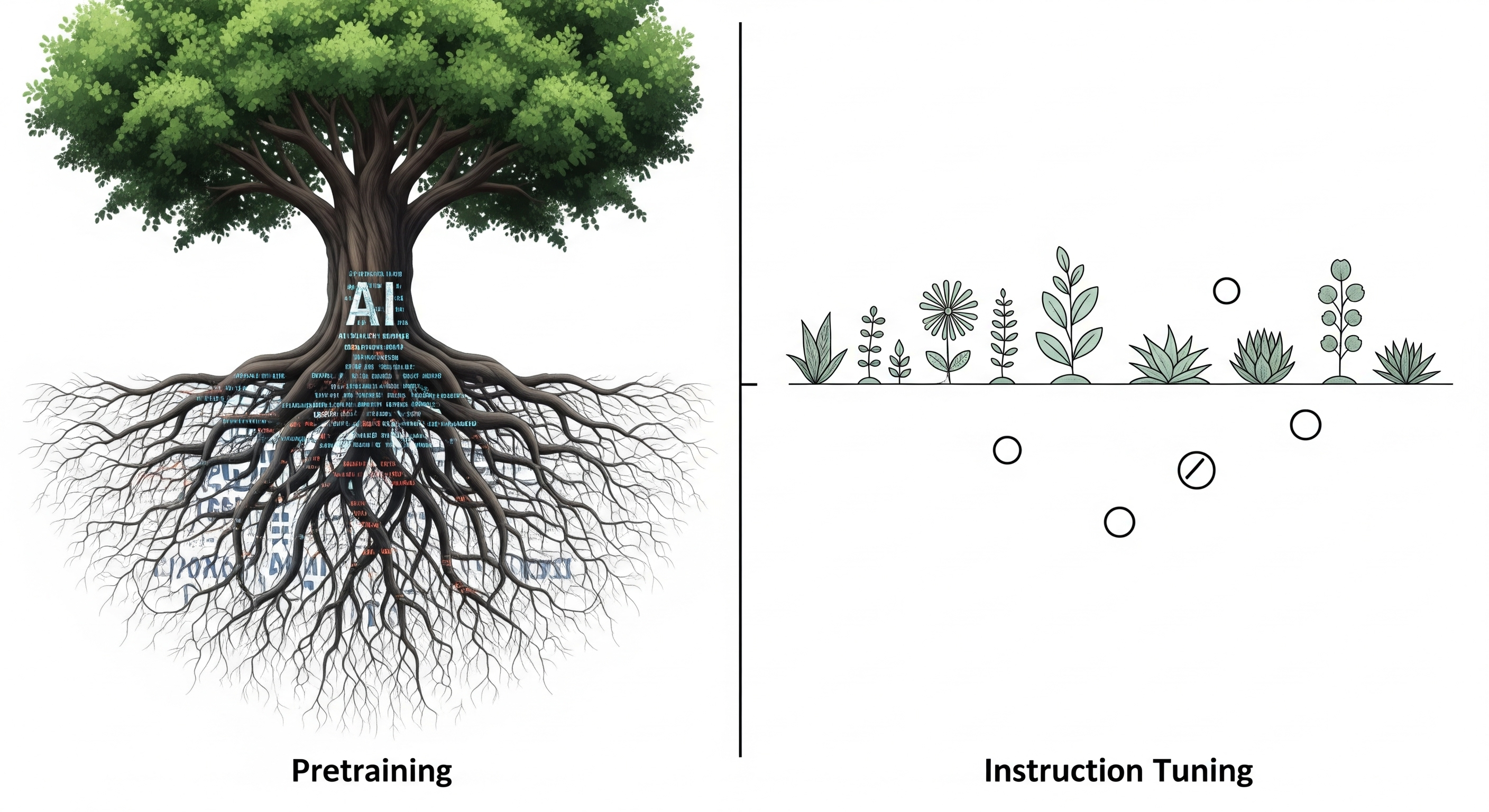
What makes a large language model (LLM) biased? Is it the instruction tuning data, the randomness of training, or something more deeply embedded? A new paper from Itzhak, Belinkov, and Stanovsky, presented at COLM 2025, delivers a clear verdict: pretraining is the primary source of cognitive biases in LLMs. The implications of this are far-reaching — and perhaps more uncomfortable than many developers would like to admit. The Setup: Two Steps, One Core Question The authors dissected the origins of 32 cognitive biases in LLMs using a controlled two-step causal framework: ...