The Sink That Remembers: Solving LLM Memorization Without Forgetting Everything Else
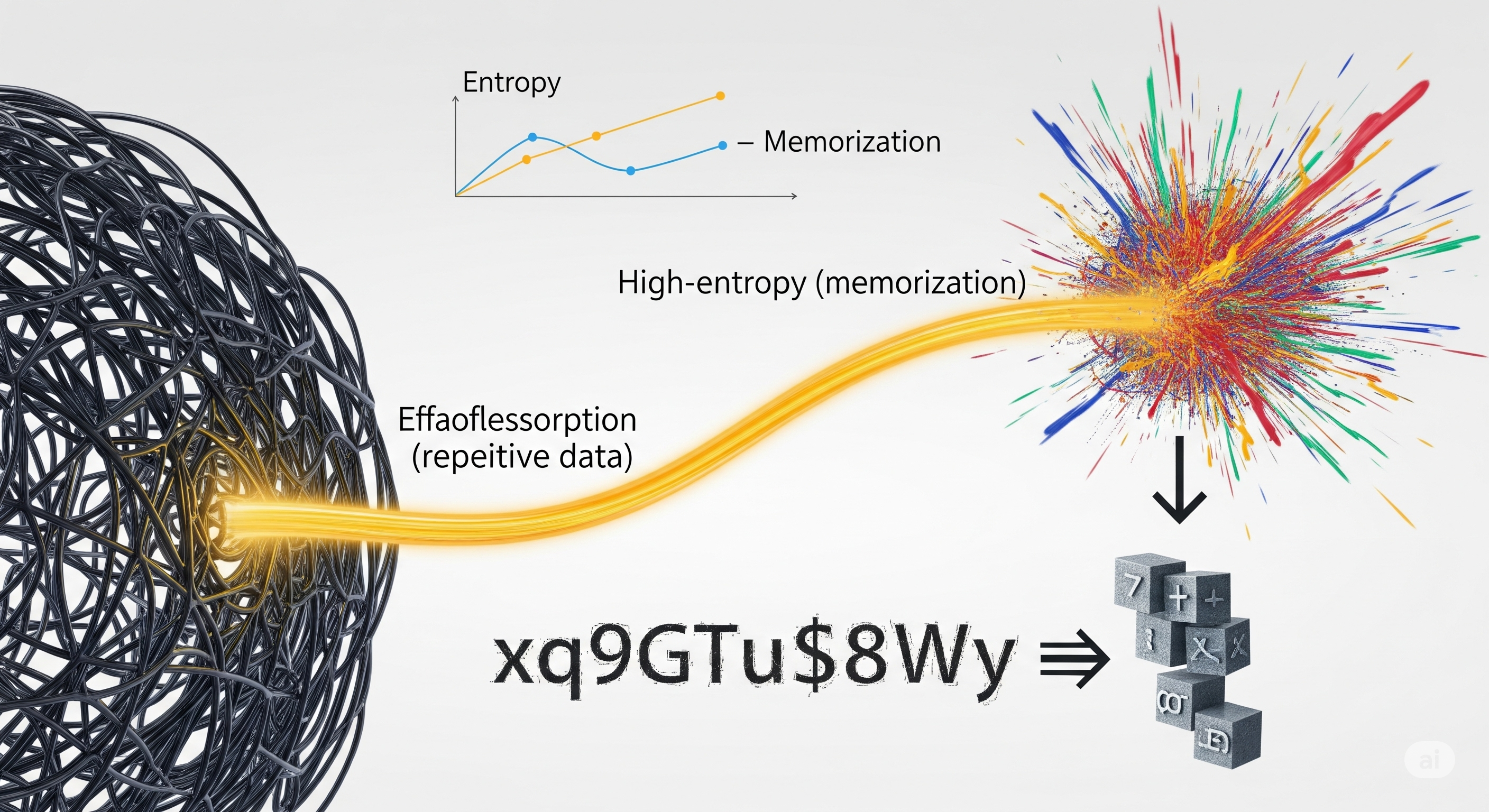
TL;DR for operators Deletion is simple in a database. It is not simple in a neural network that has already used the deleted record to improve its internal machinery. That is the unpleasant little invoice this paper presents. Gaurav R. Ghosal, Pratyush Maini, and Aditi Raghunathan study why repeated natural text is hard to remove from language models after training, then propose MemSinks, a training-time mechanism designed to make memorization easier to isolate later.1 The important shift is not “better pruning.” It is architectural accounting. Instead of hoping that memorized text happens to live in a few removable neurons, MemSinks gives repeated sequences a controlled place to accumulate memorization during training. ...