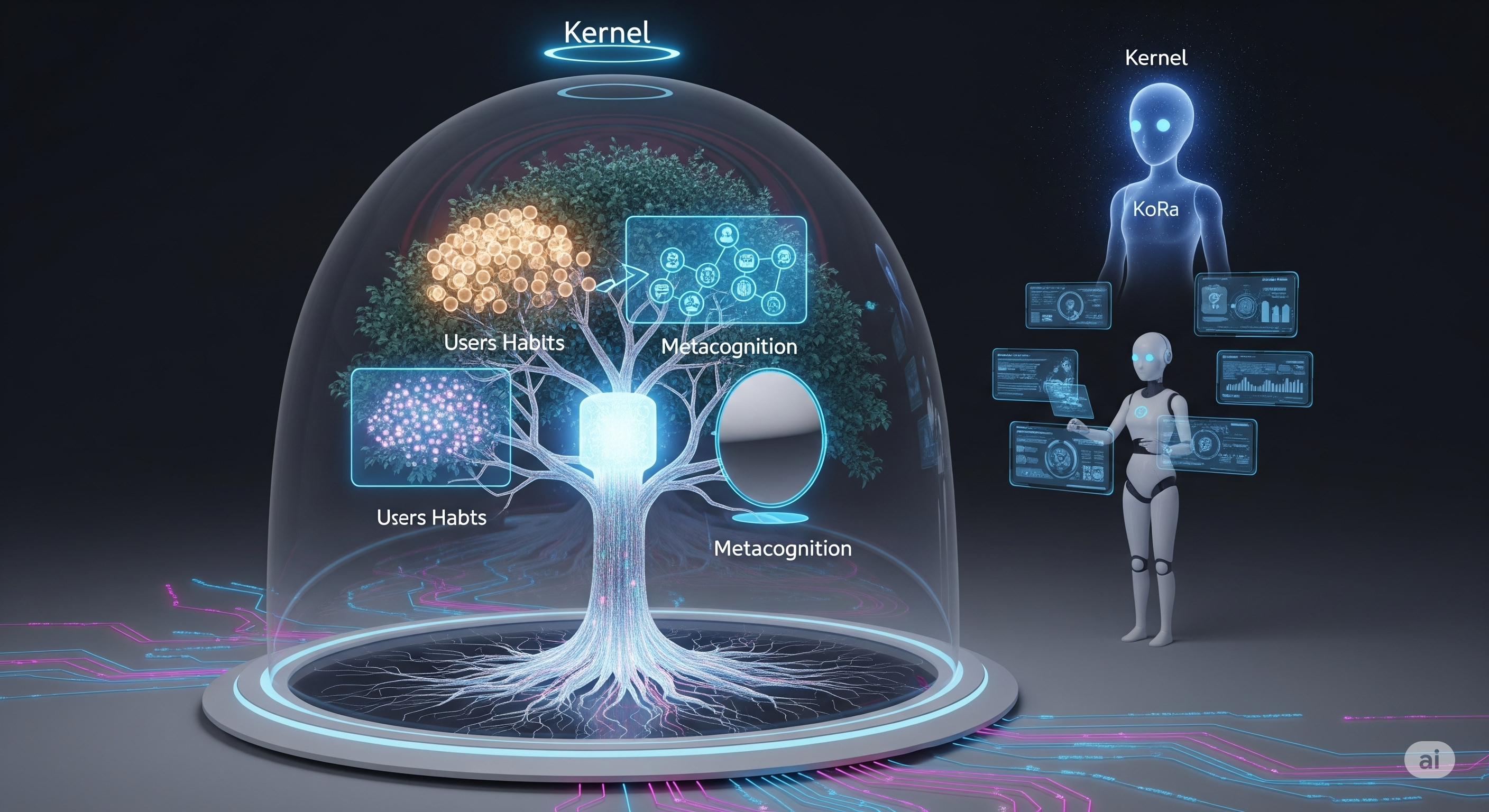
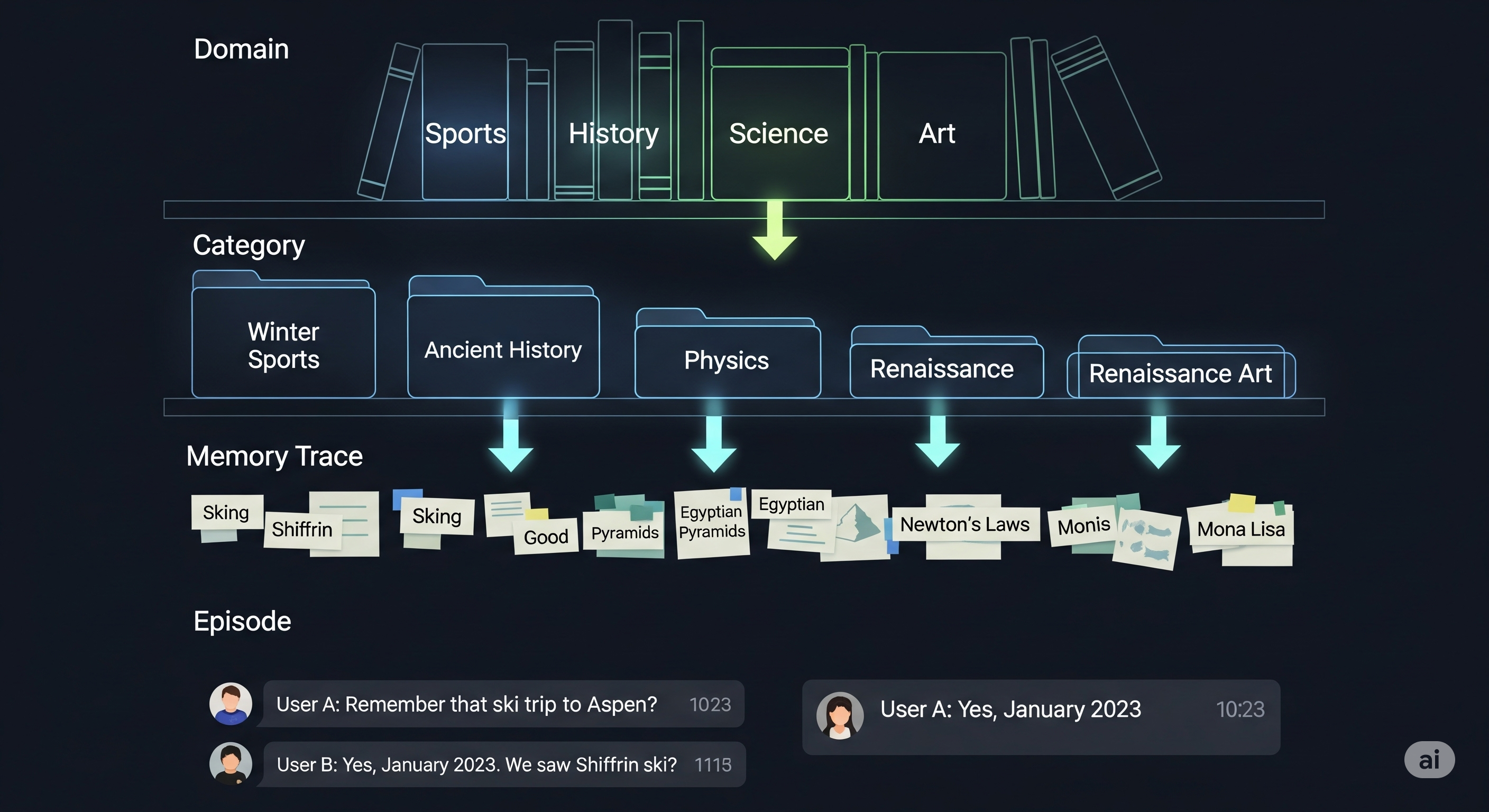
Meta-Game Theory: What a Pokémon League Taught Us About LLM Strategy
When language models battle, their strategies talk back. In a controlled Pokémon tournament, eight LLMs drafted teams, chose moves, and logged natural‑language rationales every turn. Beyond win–loss records, those explanations exposed how models reason about uncertainty, risk, and resource management—exactly the traits we want in enterprise decision agents. Why Pokémon is a serious benchmark (yes, really) Pokémon delivers the trifecta we rarely get in classic AI games: Structured complexity: 18 interacting types, clear multipliers, and crisp rules. Uncertainty that matters: imperfect information, status effects, and accuracy trade‑offs. Resource management: limited switches, finite HP, role specialization. Crucially, the action space is compact enough for language-first agents to reason step‑by‑step without search trees—so we can see the strategy, not just the score. ...