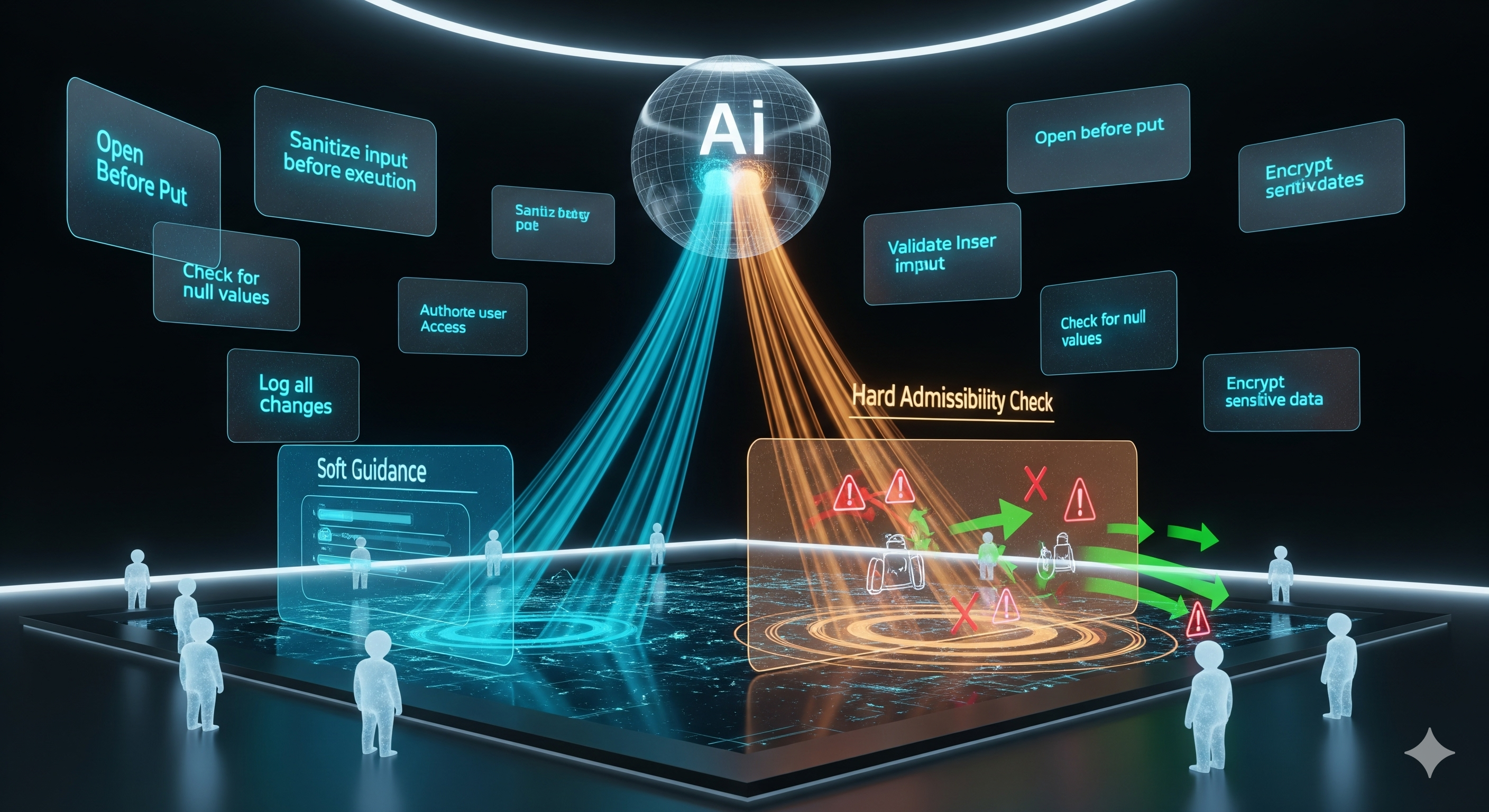
Stop Signs Are Not Steering Wheels: TRIAD and the Case for Repairable Agent Guardrails
TL;DR for operators Most agent guardrails behave like stop signs. They inspect a proposed action, decide whether it looks safe, and then allow or block execution. This is neat, legible, and often operationally clumsy. Real agent failures are not always cleanly harmful from the first word. A useful business request can be contaminated by a prompt injection, a malicious tool response, or an unsafe intermediate plan. Blocking the whole task may reduce risk, but it also throws away the legitimate work. Excellent safety theatre, less excellent operations. ...