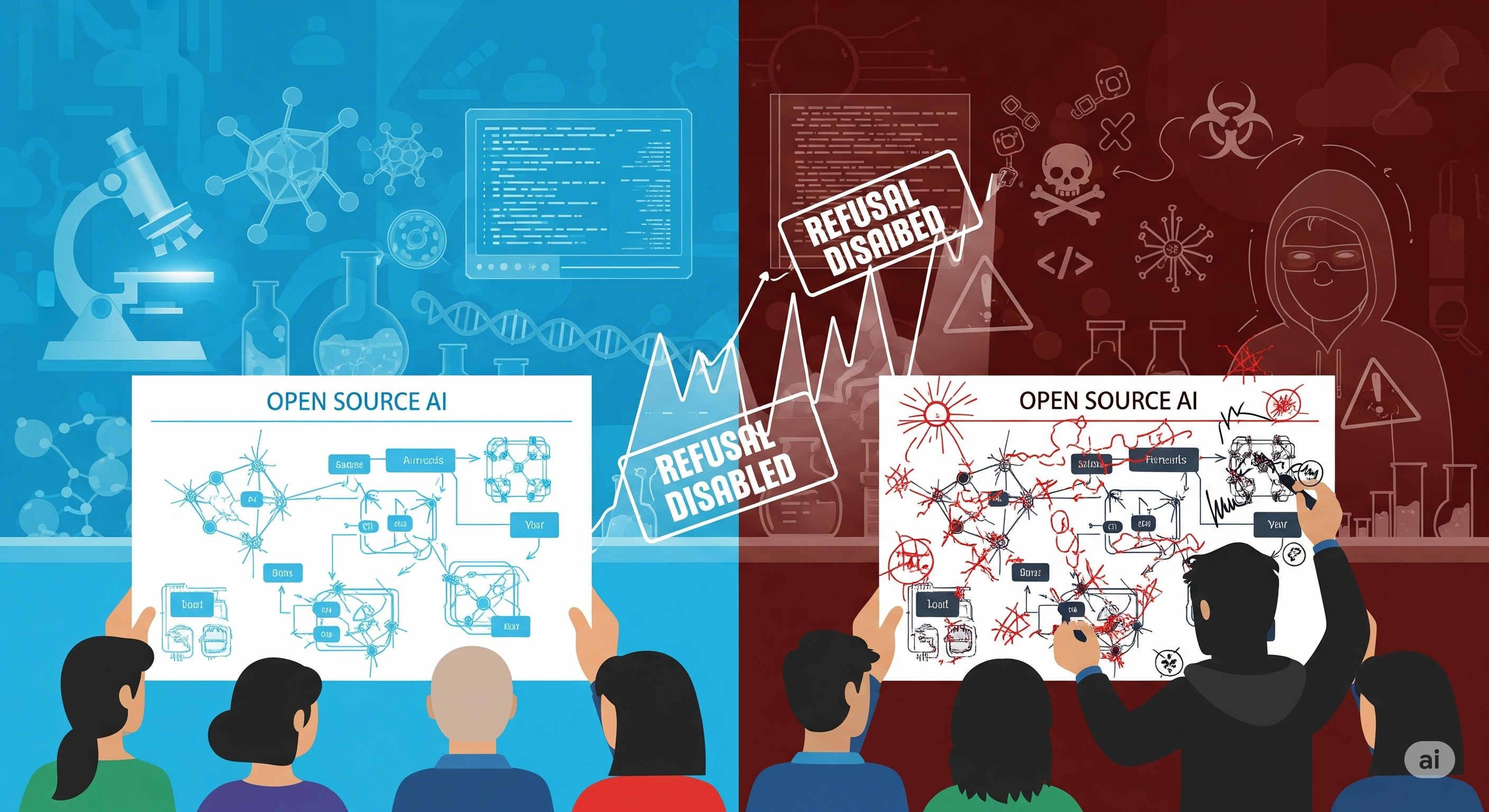
Open-Source, Open Risk? Testing the Limits of Malicious Fine-Tuning
TL;DR for operators Open-weight model safety is not just a question of what the released model refuses to answer. Once weights are public, the more relevant question is what a capable actor can make the model do after post-training. That is the problem this paper tackles. The paper introduces malicious fine-tuning as a release-evaluation method: take the model, assume a sophisticated adversary with serious reinforcement-learning infrastructure, and try to elicit the maximum dangerous capability in high-risk domains. The authors apply this to gpt-oss-120b, focusing on biology and cybersecurity rather than self-improvement. ...