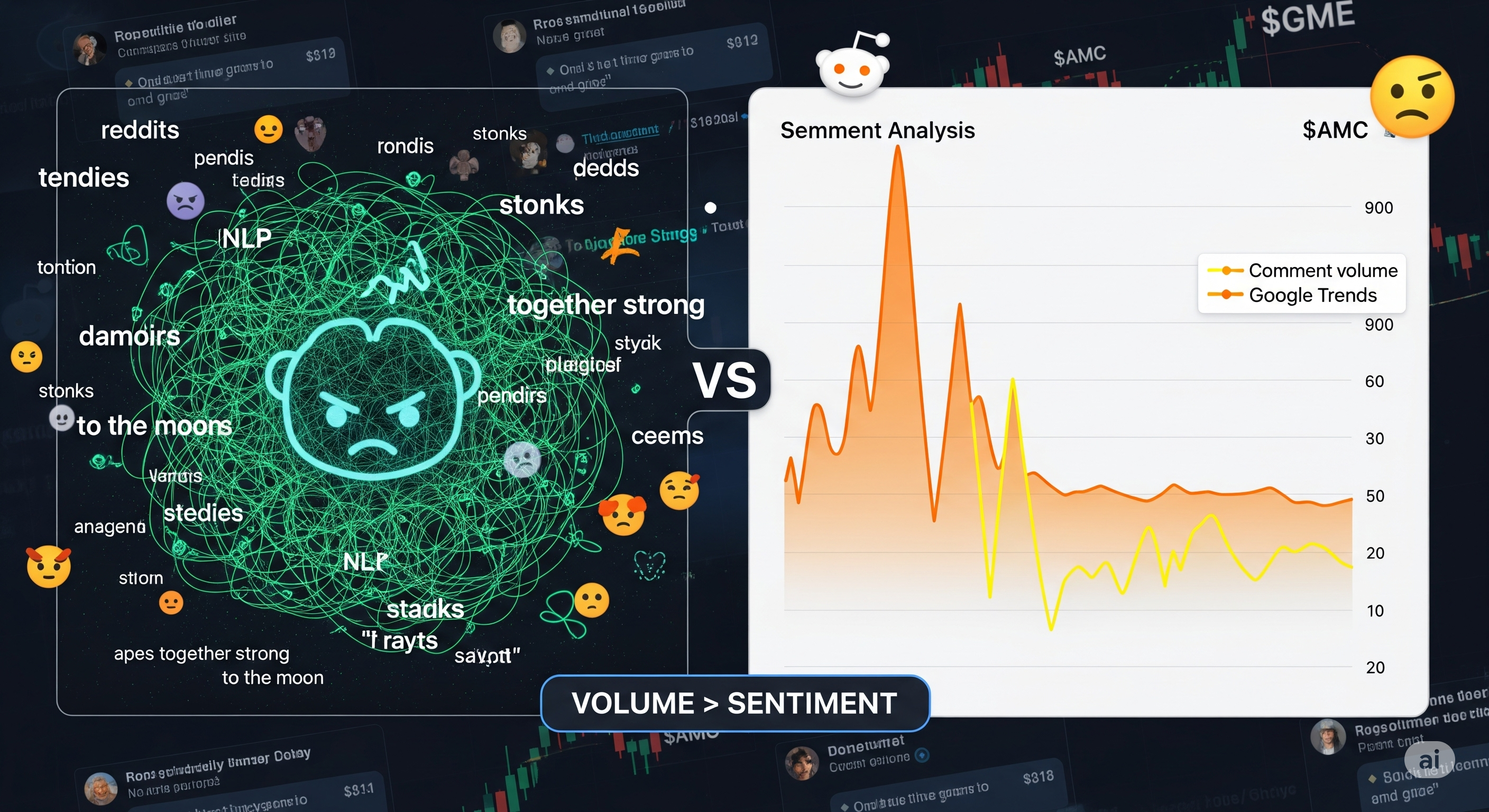
When the Market Speaks: A New Dataset That Actually Listens
In financial sentiment analysis, the devil has always been in the labeling. Most datasets — even the industry-standard Financial-Phrasebank — ask human annotators to tag headlines as positive, negative, or neutral. But here’s the problem: the market often disagrees. Take a headline reporting widening losses. Annotators marked it “negative.” Yet the stock rose the next day. Welcome to the disconnect. Enter FinMarBa, a bold new dataset that cuts out the middleman — the human — and lets the market itself do the labeling. Developed by Lefort et al. (2025), this 61,252-item dataset uses next-day price reactions to classify financial news, creating a labeling method that is empirically grounded, scalable, and (critically) aligned with investor behavior. ...