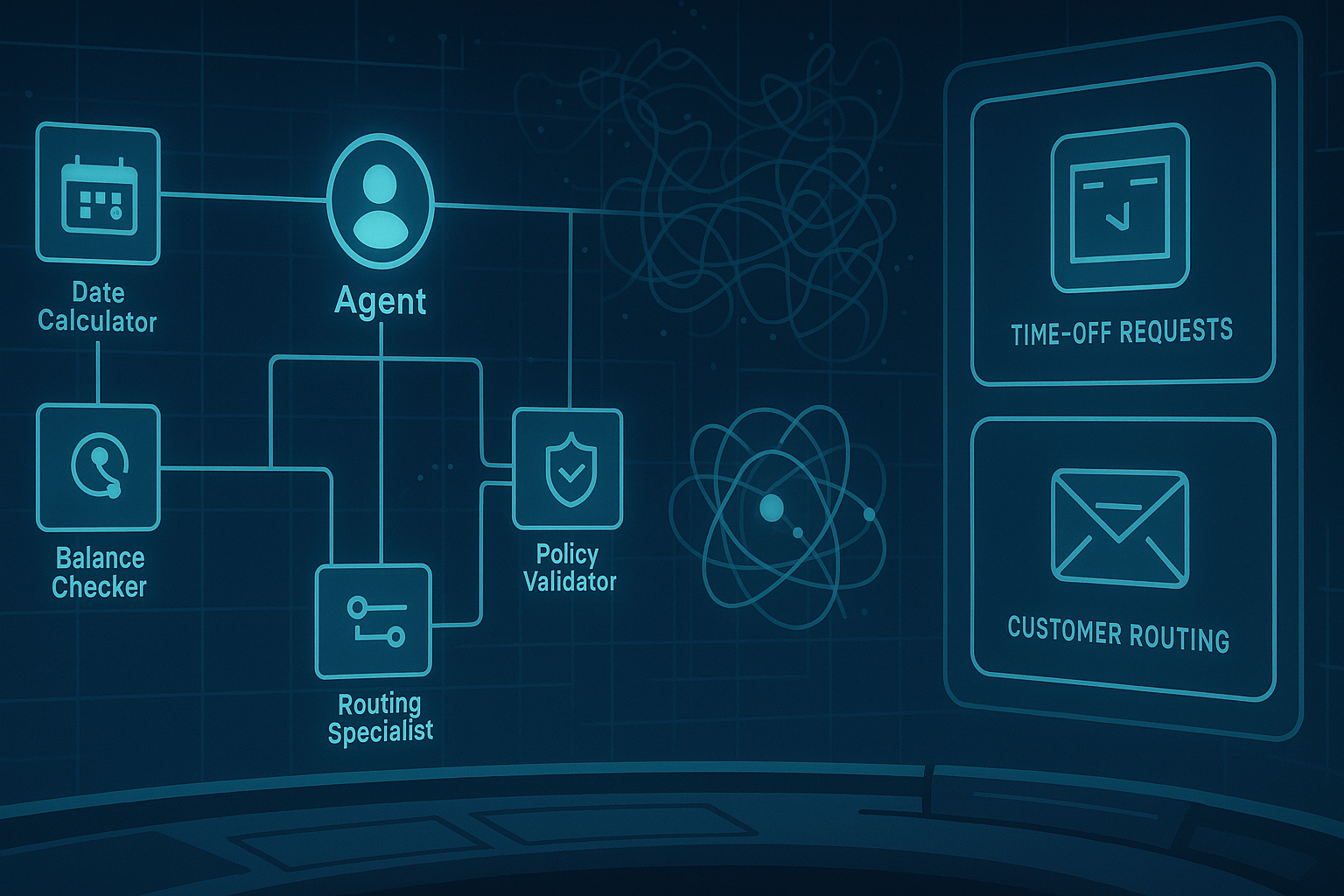
From Prototype to Profit: How IBM's CUGA Redefines Enterprise Agents
When AI agents first emerged as academic curiosities, they promised a future of autonomous systems capable of navigating apps, websites, and APIs as deftly as humans. Yet most of these experiments never left the lab. The jump from benchmark to boardroom—the point where AI must meet service-level agreements, governance rules, and cost-performance constraints—remained elusive. IBM’s recent paper, From Benchmarks to Business Impact, finally brings data to that missing bridge. The Benchmark Trap Generalist agents such as AutoGen, LangGraph, and Operator have dazzled the research community with their ability to orchestrate tasks across multiple tools. But academic triumphs often hide operational fragility. Benchmarks like AppWorld or WebArena measure intelligence; enterprises measure ROI. They need systems that are reproducible, auditable, and policy-compliant—not just clever. ...