The Proof Is in the Process
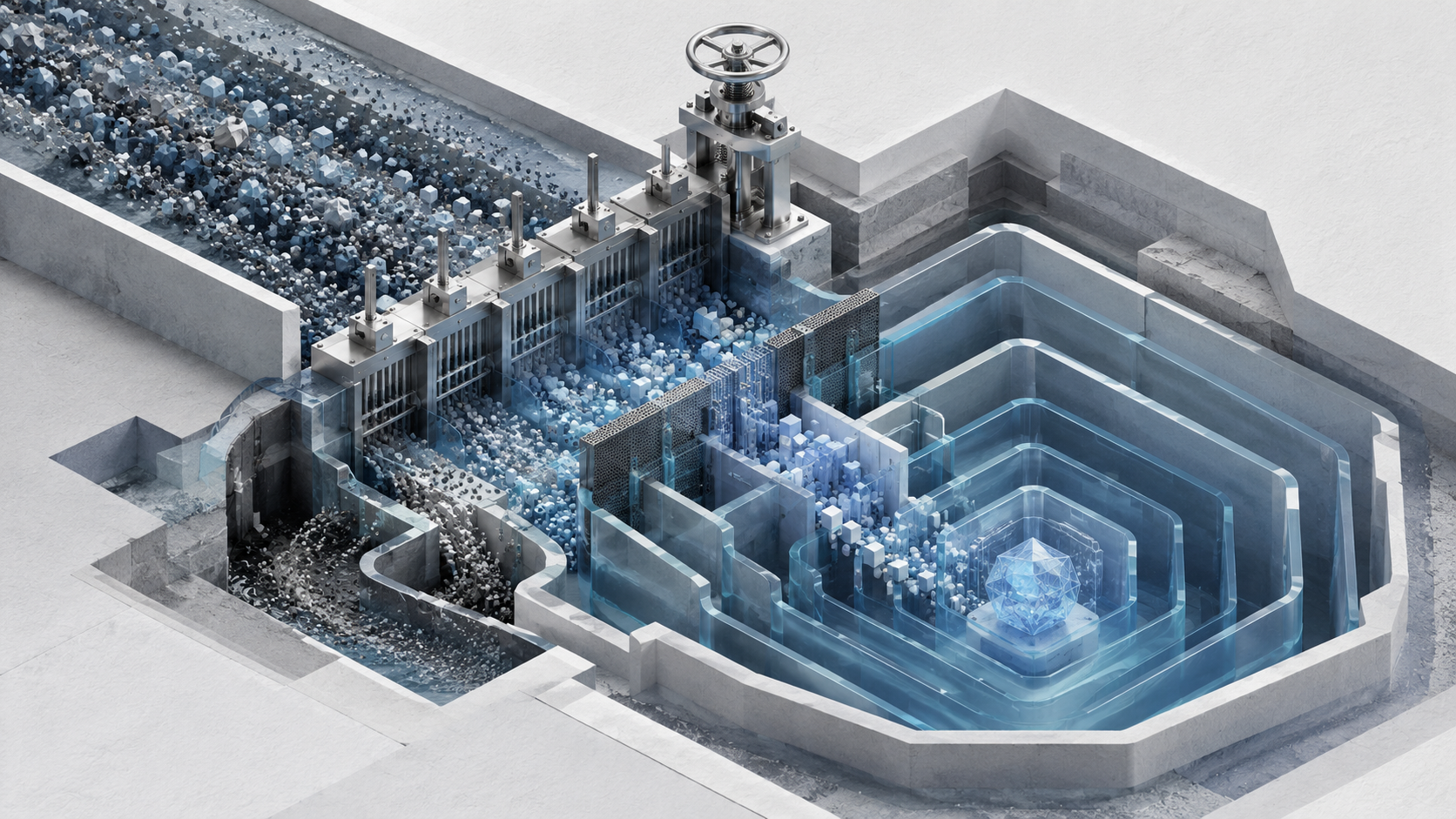
TL;DR for operators MaxProof is not primarily a story about a model suddenly becoming brilliant at mathematics. It is a story about wrapping an imperfect model in a disciplined production process. MiniMax trains M3 to perform three distinct jobs: write proofs, identify concrete errors in proofs, and repair proofs using those critiques. At inference time, MaxProof generates a population of candidate solutions, evaluates them conservatively, preserves competing approaches, applies both targeted patches and broader rewrites, and finally chooses one answer through pairwise comparison.1 ...