Blame the Blueprint: Why AI Risk Starts in the Architecture
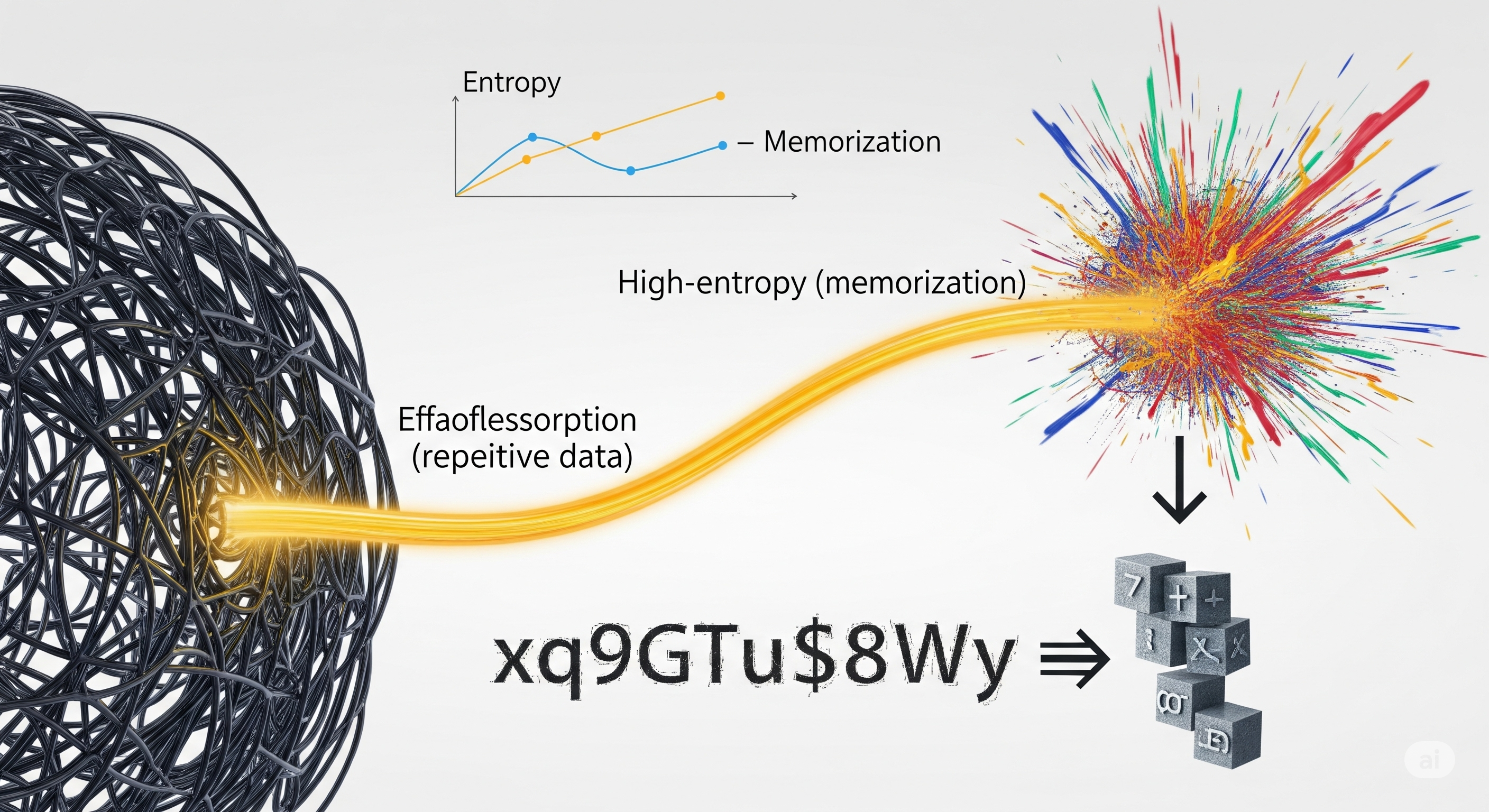
AI risk reviews still tend to begin with comforting questions. Who is the responsible developer? What policy applies? What did the model output? Was the user allowed to ask that? Did the compliance team approve the deployment checklist? Useful questions, certainly. Also slightly late. Two recent arXiv papers point to a less convenient lesson: some AI risks are not merely produced by bad prompts, careless users, malicious deployment, or weak legal controls. They are produced by architecture. One paper shows this at the model-training layer, where Batch Normalization can amplify memorization of atypical samples and increase privacy leakage.1 The other shows it at the ecosystem layer, where decentralized AI can dissolve the very addressee that conventional governance assumes, forcing governance to move from policy instructions to protocol-level constraints.2 ...