
Update or Revise? Turns Out It’s the Same Argument in a Better Suit
A formal belief-change result shows why AGM revision is best read as a stricter version of KM update, with the real gap hiding in how systems handle unsurprising information.
A formal belief-change result shows why AGM revision is best read as a stricter version of KM update, with the real gap hiding in how systems handle unsurprising information.

A research-backed look at why LLM trading agents may depend less on agent count and more on how expert workflows are decomposed, routed, and validated.

A mechanism-first reading of how GRAVE², GRAVER, and GRAVER² preserve search strength under tight memory budgets.

A mechanism-first reading of ODEBRAIN, a Neural ODE framework that models EEG brain networks as continuous graph dynamics rather than fixed-window classifications.
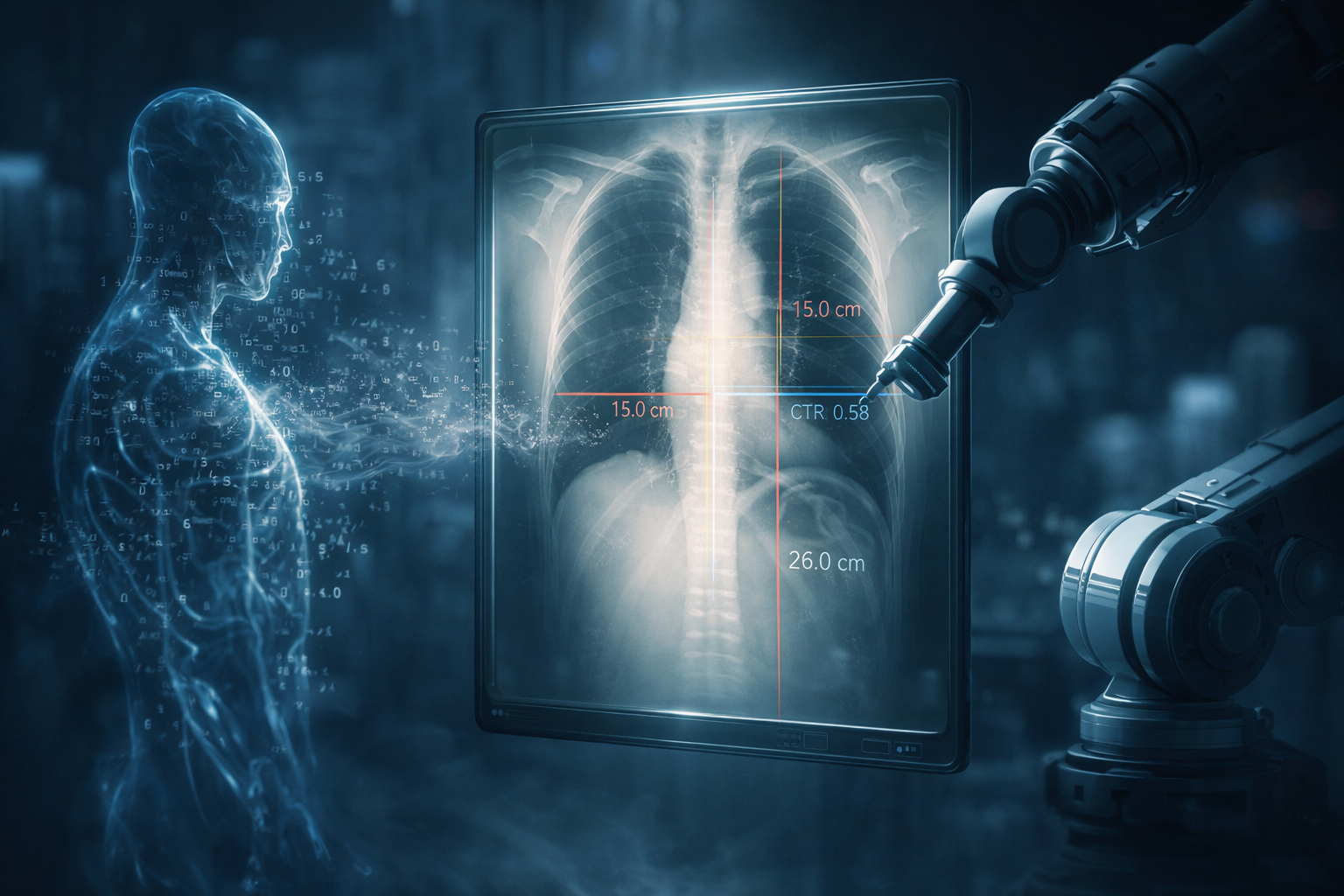
CXReasonAgent shows why clinical AI needs verifiable evidence pipelines more than another layer of fluent medical-sounding text.

A mechanism-first reading of DAD, a claim-decomposition framework that shows factuality pipelines need trained interfaces, not merely stronger verifiers.

A variable-isolation study shows why forcing an LLM to define the task can improve reliability more than adding profile data or retrieval context.

A mechanism-first reading of ProactiveMobile, showing why proactive mobile agents are not just reactive agents with better prompts.

A comparison-based reading of SPG-LLM, showing how LLMs can shrink symbolic planning tasks before grounding while trading speed for coverage and guarantees.

A study on LLMs’ inconsistent trust in humans and algorithms shows why AI governance must test what models choose, not only what they say.