Recruiters do not match job titles the way search boxes do.
A search box sees “Chief Executive Officer” and “Managing Director” and notices the obvious problem: almost no shared words. A recruiter sees the less obvious truth: these can be functionally close roles. Then the same recruiter sees “Director of Sales” and “Vice President, Marketing” and understands a different kind of relationship: not identical, but adjacent enough to matter.
That difference is the whole point of Semantic Textual Relatedness, or STR. Similarity asks whether two texts look alike. Relatedness asks whether they are meaningfully connected. In HR systems, this is not a philosophical distinction. It decides whether a candidate sees a plausible internal mobility path, whether a recruiter can justify a recommendation, and whether an automated matching system can explain itself before someone asks, rather inconveniently, “Why did the model recommend this?”
The paper behind this article, Towards Explainable Job Title Matching: Leveraging Semantic Textual Relatedness and Knowledge Graphs, proposes a self-supervised pipeline that combines fine-tuned sentence embeddings with a skill knowledge graph for explainable job-title matching.1 Its useful contribution is not merely that it adds a knowledge graph. Many systems add graphs the way cafés add “artisan” to the menu: sometimes meaningful, often decorative. The useful contribution is the mechanism: job titles are linked to description-derived semantics, then aligned with a skill graph, and finally evaluated by where the prediction sits on the relatedness spectrum.
That last part matters. The graph-augmented model is not best everywhere. It is strongest where job titles are already highly related. It is weak in the low-relatedness region. So the lesson is not “knowledge graphs improve job matching.” The lesson is sharper and more operational: use different matching machinery for different stages of the funnel.
The problem is not title matching. It is title matching with reasons.
A title-only matcher is tempting because job titles are cheap, universal, and already present in nearly every HR database. They are also messy little semantic traps.
“Software Engineer II”, “Backend Developer”, and “Platform Engineer” may overlap depending on organisation, industry, seniority, and actual duties. “Consultant” can mean anything from strategy advisory to implementation grunt work wearing a blazer. “Manager” may mean people manager, project owner, client lead, or simply “we needed a nicer title”.
The paper recognises this ambiguity and avoids treating job titles as isolated strings. Its pipeline starts with job descriptions, summarises them using a pretrained BART model to remove boilerplate and preserve functional content, embeds those summaries with SBERT, and uses pairwise cosine similarity between those description-derived embeddings to create self-supervised STR scores. Those scores then become training targets for title-pair matching.
That is an important design move. It does not ask humans to label thousands of title pairs. Instead, it uses job descriptions as weak semantic evidence for what the titles probably mean. Weak evidence is still weak, but at least it is evidence. The alternative is pretending that title tokens alone contain the whole occupational universe, which is how one ends up matching “Sales Engineer” to “Software Engineer” because both contain “Engineer”. Very efficient. Also wrong.
The simplified mechanism looks like this:
Job descriptions
↓ summarise functional content
Description embeddings
↓ cosine similarities
Self-supervised STR labels for title pairs
↓ fine-tune sentence model
Job-title embeddings
↓ align to skill graph
Skill-mediated STR score + explanation path
The important phrase is “skill-mediated”. The model is not only trying to say that two titles are close. It is trying to expose the skill relationships that made them close.
The knowledge graph changes the question from “how close?” to “close through what?”
Embedding-only systems can give a score. That is useful, but not satisfying in HR. A score of 0.82 between two job titles tells a recruiter almost nothing unless the system can explain the basis of the relationship. Is the match driven by shared technical skills, shared management responsibility, same industry language, or a generic skill like “communicate with stakeholders”, the mayonnaise of job descriptions?
The paper constructs a bipartite job-skill graph using job nodes and skill nodes. For each job, it selects top-ranked skills based on semantic similarity. It also prunes skills that are too common: skills with job share above 20% are removed, and remaining skills are reweighted by a specificity score based on inverse centrality degree. In plain terms, the graph tries to stop generic skills from dominating the explanation.
That matters because explanations are not equally useful. “These roles are related because both involve managing workflows and stakeholder communication” is barely an explanation. It is corporate fog. “These roles are related because both involve fraud risk assessment, regulatory reporting, and credit portfolio monitoring” is more useful because it gives a recruiter something inspectable.
Technically, the authors fine-tune SBERT using anchor-sample-score triplets with cosine similarity loss, learn graph embeddings with a relational graph convolutional network, and train a lightweight MLP to map job-title text embeddings into the knowledge-graph embedding space. At inference time, title embeddings can be projected into that graph space, where relatedness is estimated and explanatory skill paths can be recovered.
The point is not that the graph magically understands work. It does not. It inherits whatever the skill taxonomy captures, and whatever the data pipeline has linked correctly. The point is that the model now has a structured place to put its reasoning. That is already better than a mysterious cosine score floating in embedding space, wearing sunglasses indoors.
The self-supervised labels are clever, but not innocent
The paper’s self-supervised strategy is practical. Manual STR labels for job titles would be expensive, subjective, and probably inconsistent across industries. By deriving labels from job-description similarities, the authors create a scalable training signal.
But this also creates a dependency chain:
| Pipeline step | What it gives the system | What can go wrong |
|---|---|---|
| Description summarisation | Removes boilerplate and keeps functional duties | Summaries may drop context that distinguishes roles |
| SBERT description embeddings | Produces semantic similarity scores | Embedding bias becomes label bias |
| Synthetic STR labels | Enables fine-tuning without manual annotation | Weak labels may be noisy, especially for low-relatedness pairs |
| Skill graph alignment | Adds structure and explanation paths | Graph quality limits explanation quality |
| Stratified evaluation | Shows where models succeed or fail | Region boundaries are still design choices |
This is not a criticism of the paper. It is the price of building scalable HR infrastructure without hand-labelling every title pair. The paper is useful precisely because it does not hide that price. It gives us enough experimental detail to ask where the method helps, where it does not, and what kind of production system could use it responsibly.
The main evidence is regional, not global
The authors evaluate five model configurations:
- pretrained JOBBERT;
- JOBBERT fine-tuned on synthetic STR data;
- pretrained MPNET;
- MPNET fine-tuned on synthetic STR data;
- fine-tuned MPNET combined with R-GCN graph embeddings.
They then split STR into three regions:
| STR region | Score range | Operational interpretation |
|---|---|---|
| Low STR | 0.00–0.50 | Mostly unrelated or noisy title pairs |
| Medium STR | 0.50–0.75 | Ambiguous, borderline, partially related roles |
| High STR | 0.75–1.00 | Near-duplicates, synonyms, or highly related roles |
This is the paper’s best methodological instinct. Global RMSE can make a model look acceptable while hiding the exact region where it fails. In recruitment, that is not a minor dashboard issue. Different parts of the hiring or mobility funnel need different behaviour.
The reported RMSE results make the pattern clear:
| Model | Global RMSE | Low STR | Medium STR | High STR | Best use suggested by results |
|---|---|---|---|---|---|
| JOBBERT | 0.28 | 0.38 | 0.11 | 0.15 | Surprisingly better around medium/high than low |
| JOBBERT-F | 0.17 | 0.16 | 0.17 | 0.18 | Stable fine-tuned baseline |
| MPNET | 0.29 | 0.14 | 0.36 | 0.44 | Good low-STR separation, poor high-STR matching |
| MPNET-F | 0.16 | 0.14 | 0.16 | 0.18 | Best global score, strong general-purpose option |
| MPNET+RGCN | 0.23 | 0.30 | 0.14 | 0.11 | Best high-STR model, weak low-STR filter |
The headline result is tempting: MPNET+RGCN achieves the lowest high-STR RMSE at 0.11, compared with 0.18 for the fine-tuned text-only baselines. That is a meaningful improvement in the region where fine distinctions among already plausible roles matter.
But the same table also says something less convenient: MPNET+RGCN has low-STR RMSE of 0.30, much worse than MPNET and MPNET-F at 0.14. If the task is to reject obviously unrelated pairs, the graph-augmented model is not the hero. It may be bringing relational structure into cases where the best move is simply to say, “No, these are not related.”
This is why the paper’s result should be read as pipeline guidance, not leaderboard theatre.
The t-tests support asymmetry; they are not a second thesis
The paper also reports paired t-tests over absolute errors across STR regions. These tests are best understood as a robustness and diagnostic layer, not as a separate argument.
Their purpose is to show that the regional differences are not just visual impressions from the RMSE table. For example, MPNET shows strong significant differences across region pairs, with far lower errors in the low-STR region than in medium or high STR. MPNET+RGCN shows the opposite pattern: higher errors in low STR and lower errors in medium and high STR.
That supports the core interpretation: model behaviour is asymmetric across the relatedness spectrum.
It does not prove that one model is universally superior. It does not validate the system for hiring decisions. It does not solve fairness. It tells us something more modest and more useful: a model’s apparent quality depends heavily on which part of the relatedness range the business actually cares about.
That is exactly the sort of modest result production systems need. Large claims are cheap. Region-specific diagnostics are operational.
The explanation graphs are diagnostic tools, not decorative screenshots
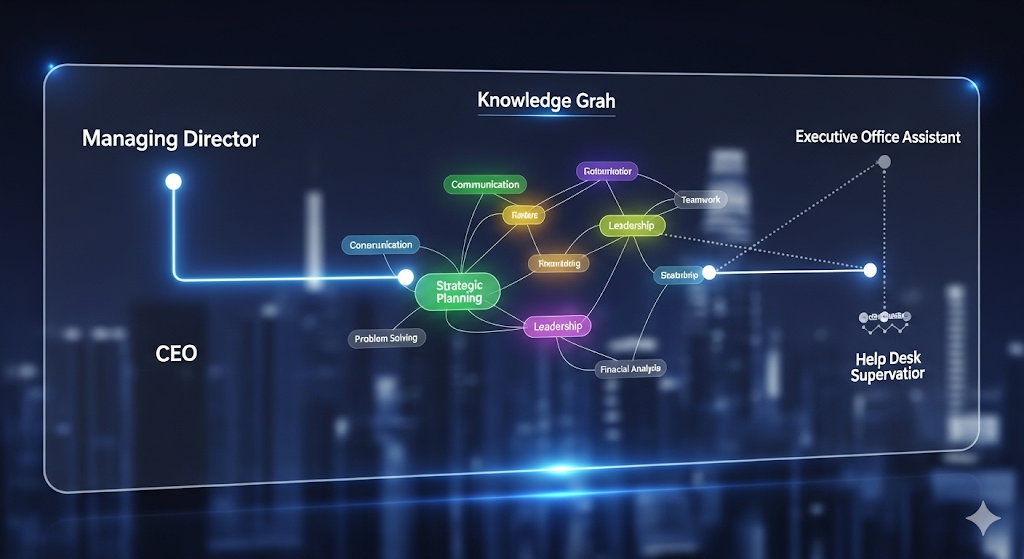
The paper includes two explanation examples. One is a high-STR pair: “Senior Performance and Project Analyst” and “Director, eCommerce & Retail”. The graph highlights shared, relatively specific skills, including “supervise brand management” with a specificity score of 0.67. The other is a poor match: “Executive Office Assistant” and “Help Desk Shift Supervisor”. There, the apparent link is driven by a generic skill, “supervise office workers”, with specificity 0.0.
The likely purpose of these figures is illustrative explanation, not quantitative validation. They show how the graph can expose whether a match is grounded in meaningful skill overlap or in generic noise.
That distinction is important for HR operations. A recommender system that merely says “match score: 0.76” forces recruiters either to trust the model blindly or ignore it politely. A system that says “these titles are linked through these specific skills, with these specificity scores” gives recruiters something to inspect, challenge, and log.
For governance, that is not a nice extra. It is the difference between a score and an audit trail.
The business architecture should be staged, not monolithic
The practical takeaway is a two-stage matching architecture.
Use a fast, strong text model for early filtering. MPNET and MPNET-F perform well in low STR, which makes them suitable for removing obvious non-matches, deduplicating noisy title lists, or screening out unrelated alternatives. At this stage, the system needs broad discrimination. It does not need elaborate skill explanations for every rejected pair.
Then use a fine-tuned, graph-aligned model for reranking plausible matches. Once the candidate set is already in the medium-to-high relatedness range, the challenge changes. The system must distinguish close alternatives, surface transferable skills, and explain why one role is adjacent to another. That is where the MPNET+RGCN result is most relevant.
The paper directly shows region-specific RMSE differences across job-title pairs. Cognaptus infers the staged architecture from those results.
| What the paper shows | Business inference | Boundary |
|---|---|---|
| MPNET-F has the best global RMSE at 0.16 and strong low-STR RMSE at 0.14 | Use fine-tuned text models as general-purpose filters | Global performance still hides regional failures |
| MPNET+RGCN has the best high-STR RMSE at 0.11 | Use graph alignment for final reranking among plausible matches | It is worse in low STR and should not be treated as a universal replacement |
| Explanation graphs reveal specific vs generic skill links | Show recruiters why two titles are related | The examples are illustrative, not a user study |
| Generic skills are pruned and remaining skills reweighted by specificity | Build explanation quality controls into the graph layer | This depends on taxonomy and graph construction quality |
| Evaluation is split into low, medium, and high STR | Match metrics to pipeline stage | Region boundaries may need calibration by domain |
This architecture is also a useful way to think about ROI. The value is not only higher accuracy. It is cheaper diagnosis. When a recruiter disputes a recommendation, the system can expose whether the match came from specific skills, generic overlap, or a questionable graph link. That makes debugging possible.
And in HR systems, “debugging possible” is a stronger business claim than “AI-powered”. Lower sparkle, higher usefulness.
What this does not prove
The paper is careful about its scope, and the business reader should be equally disciplined.
First, this is job-to-job title matching, not end-to-end hiring. It does not show that the method improves candidate selection, interview outcomes, retention, diversity, or hiring fairness. Those are downstream claims requiring different evidence.
Second, the labels are weakly supervised. STR scores are generated from description embedding similarities, not human-labelled ground truth. That is scalable, but it can introduce label noise, especially in low-similarity cases. If the source descriptions are thin, inflated, or industry-specific in odd ways, the training signal inherits those weaknesses.
Third, the knowledge graph is skill-centred. The authors note that future work should add industry classifications, seniority, and domain context. This is not cosmetic. “Data Scientist — Healthcare” and “Data Scientist — Finance” may share tools while differing sharply in regulatory context, domain knowledge, and business risk. A skill-only graph may underrepresent that difference.
Fourth, the evaluation uses a relatively small dataset. The appendix reports 14,000 job records from a Kaggle-derived source, 14,000 skills and competences from ESCO, and 50 skill categories from an Indeed-derived list. That is enough to explore the mechanism. It is not enough to claim broad labour-market generalisation across sectors, countries, languages, or company-specific title systems.
Fifth, the graph experimentation is narrow. The paper evaluates a limited set of graph embedding choices, focuses on cosine similarity loss, and uses a single negative sampling strategy. A stronger contrastive setup, different negative sampling, or richer graph schema might change the performance profile.
These limitations do not weaken the article’s central lesson. They locate it. The paper is best read as a design pattern for explainable semantic matching, not as a finished enterprise HR product.
The real lesson: measure the region where the decision happens
Most recommendation dashboards reward averages. Hiring workflows do not.
Early in the funnel, the system must confidently reject unrelated pairs. Later in the funnel, it must carefully distinguish related pairs. During governance review, it must explain why any of this happened. Those are different jobs. It is unsurprising that different models do them differently.
The paper’s strongest contribution is therefore not the high-STR RMSE number by itself, although 0.11 is the most attention-grabbing result. The stronger contribution is showing that regional evaluation changes the model-selection decision. A graph-aligned model can be the right choice for high-relatedness reranking and the wrong choice for low-relatedness filtering at the same time.
That sounds obvious after someone has done the work. Most useful engineering results do.
For HR teams, the implication is straightforward: stop asking whether a title matcher is “accurate”. Ask where it is accurate, what decision it supports, and whether it can explain itself in human-operational terms. A black-box score may be enough for internal experimentation. It is not enough for systems that affect work opportunities.
Titles are not tokens. They are compressed job stories. The paper’s mechanism gives those stories a more inspectable structure: descriptions become weak supervision, skills become graph links, and relatedness becomes something recruiters can challenge rather than merely receive.
That is the sort of AI progress worth taking seriously: not louder automation, but quieter accountability.
Cognaptus: Automate the Present, Incubate the Future.
-
Vadim Zadykian, Bruno Andrade, and Haithem Afli, “Towards Explainable Job Title Matching: Leveraging Semantic Textual Relatedness and Knowledge Graphs,” arXiv:2509.09522, 2025. https://arxiv.org/abs/2509.09522 ↩︎