The big idea
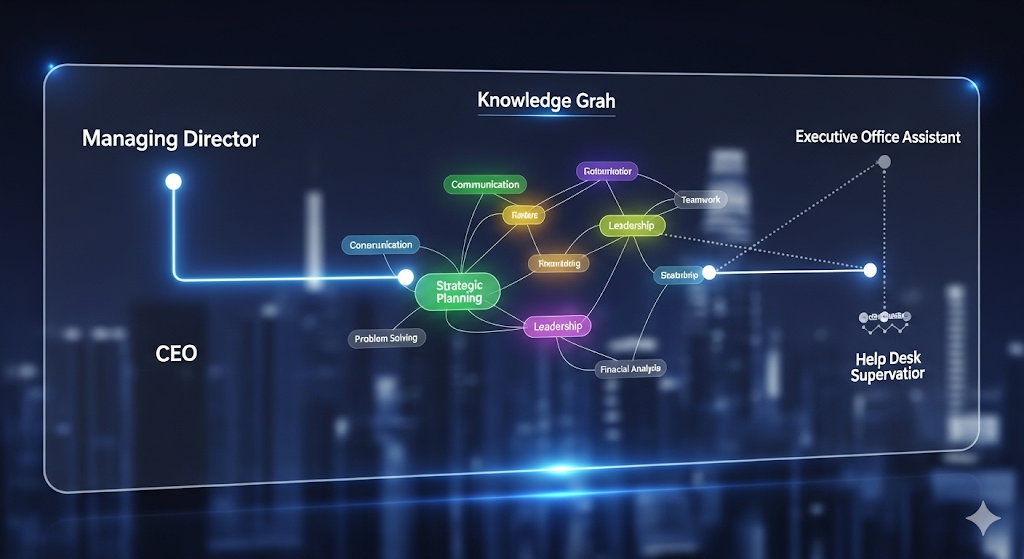
Job titles are messy: “Managing Director” and “CEO” share zero tokens yet often mean the same thing, while “Director of Sales” and “VP Marketing” are different but related. Traditional semantic similarity (STS) rewards look‑alikes; real hiring needs relatedness (STR)—associations that capture hierarchy, function, and context. A recent study proposes a hybrid pipeline that pairs fine‑tuned Sentence‑BERT embeddings with a skill‑level Knowledge Graph (KG), then evaluates models by region of relatedness (low/medium/high) instead of only global averages. The punchline: this KG‑augmented approach is both more accurate where it matters (high‑STR) and explainable—it can show which skills link two titles.
Why this matters for business
- Auditability & compliance: EU AI Act classifies many HR systems as high‑risk. Text‑only “black boxes” won’t cut it; regulators and candidates will ask why a match was made.
- Operational fit: Early funnel stages need “not similar” detection (dedupe, outlier filtering). Later funnel stages need fine discrimination among already relevant options. Region‑aware evaluation maps cleanly onto these phases.
- Talent mobility: Internal job moves hinge on relatedness (transferable skills), not word overlap. A skills graph exposes those transfer paths.
What the paper actually does (in business English)
-
Self‑supervised labels: Summarize job descriptions (BART), embed with SBERT, take cosine similarities to create STR training targets—no manual labeling.
-
Skill graph: Ingest a curated skill list (e.g., ESCO), connect jobs↔skills, prune generic skills (>20% job share) and reweight by specificity (inverse degree) to avoid vague explanations.
-
Hybrid model:
- Fine‑tune SBERT on job‑pair STR.
- Learn a light MLP mapping from text embeddings into the KG embedding space (e.g., R‑GCN/ComplEx), so text and graph “speak the same language.”
- At inference: encode both titles → project to KG space → cosine for STR and produce skill‑path explanations.
-
Region‑aware evaluation: Split the STR range into Low (0–0.50), Medium (0.50–0.75), High (0.75–1.0) to reveal where each model excels or fails.
What improved—and where
The authors benchmark five setups (pretrained vs fine‑tuned SBERT/MPNet; with/without R‑GCN). Two patterns jump out:
- Fine‑tuning matters: JOBBERT‑F and MPNET‑F slash global RMSE vs their pretrained baselines, with stable performance from medium→high STR. That’s exactly the region you use for reranking near‑duplicates.
- KGs help where stakes are highest: MPNET+RGCN improves the high‑STR band (lowest RMSE there), indicating that structured skills tighten matches when two titles are already close.
Translation: Use a general model to toss out obviously unrelated titles. Switch to fine‑tuned + KG once you’re ranking among plausible options.
The explainability you can show to recruiters
The system renders mini explanation graphs for each pair:
- Good match example: “Senior Performance & Project Analyst” ↔ “Director, eCommerce & Retail” is justified by specific overlapping skills (e.g., brand management supervision) with high specificity scores.
- Weak match example: “Executive Office Assistant” ↔ “Help Desk Shift Supervisor” hinges on generic skills (e.g., supervise office workers) with low specificity—easy to down‑rank or flag.
This is policy‑ready evidence: you’re not just giving a score; you’re giving the skill path that led to the score.
How to put this to work in your stack
Decision playbook (pipeline‑aligned):
- Ingest & summarize job posts (strip boilerplate); embed titles + summaries (SBERT/MPNet).
- Filter (low STR): Use a fast, general model to remove unrelated items (optimize for low‑band accuracy & speed).
- Rerank (medium/high STR): Hand candidates to a fine‑tuned model projected into a skill KG space; compute scores + skill‑path explanations.
- Show your work: Expose top‑N shared skills with specificity and coverage; let recruiters expand the graph for transparency.
- Governance: Log STR score, top skills, and KG traversal for each recommendation. That’s your audit trail.
Minimal data you need
- Job titles + concise duty summaries.
- Skill taxonomy (e.g., ESCO/O*NET) with hierarchical relations.
- Basic priors for pruning (e.g., treat skills appearing in >20% of jobs as “too generic”).
Metrics that won’t mislead you
Avoid only “overall RMSE” dashboards. Track per‑region RMSE and error distributions:
- Low STR RMSE → good for dedupe/noise screens.
- Medium STR RMSE → ambiguity resolver.
- High STR RMSE → critical for final ranking and hiring decisions.
Where this approach still needs work
- Beyond skills: Add industry, seniority, and domain context (e.g., Healthcare vs Finance Data Scientist) to the KG.
- Loss & negatives: Try contrastive/triplet losses and smarter negative sampling to sharpen the medium band.
- Resume↔job, multilingual: Extend from job↔job to resume↔job and cross‑language scenarios for global hiring.
A quick comparison cheat‑sheet
| Model family | Training | KG‑aligned? | Strength | Watch‑outs |
|---|---|---|---|---|
| Pretrained SBERT/MPNet | None | No | Fast low‑band filtering | Weak mid/high discrimination |
| Fine‑tuned SBERT/MPNet | Self‑supervised STR | No | Stable medium→high | Still opaque (why?) |
| Fine‑tuned + KG mapping (R‑GCN) | STR + graph MLP | Yes | Best in high STR + explanations | Needs taxonomy quality + graph ops |
Executive takeaway
Stop treating title matching as a synonym search. Treat it as relatedness over regions, and insist that your model shows its skill‑based reasoning. You’ll get fewer false positives early, better rankings late, and an audit trail recruiters (and regulators) can live with.
Cognaptus: Automate the Present, Incubate the Future