TL;DR
Most LLM agent evaluations judge the final answer. RAFFLES flips the lens to where the first causal error actually happened—then iterates with a Judge–Evaluator loop to verify primacy, fault-ness, and non-correction. On the Who&When benchmark, RAFFLES materially outperforms one-shot judges and router-style baselines. For builders, this is a template for root-cause analytics on long-horizon agents, not just scorekeeping.
Why we need decisive-fault attribution (not just pass/fail)
Modern agent stacks—routers, tool-callers, planners, web surfers, coders—fail in cascades. A harmless-looking plan choice at t=3 can doom execution at t=27. Traditional “LLM-as-a-judge”:
- Focuses on the end product, missing the origin of failure.
- Struggles with long contexts, often biased to early or late steps.
- Offers limited guidance for remediation beyond “try a better prompt.”
Decisive-fault attribution asks a different question: What is the earliest step whose correction would have flipped failure into success? That’s actionable for owners of complex, multi-component systems.
The RAFFLES idea in one diagram (words)
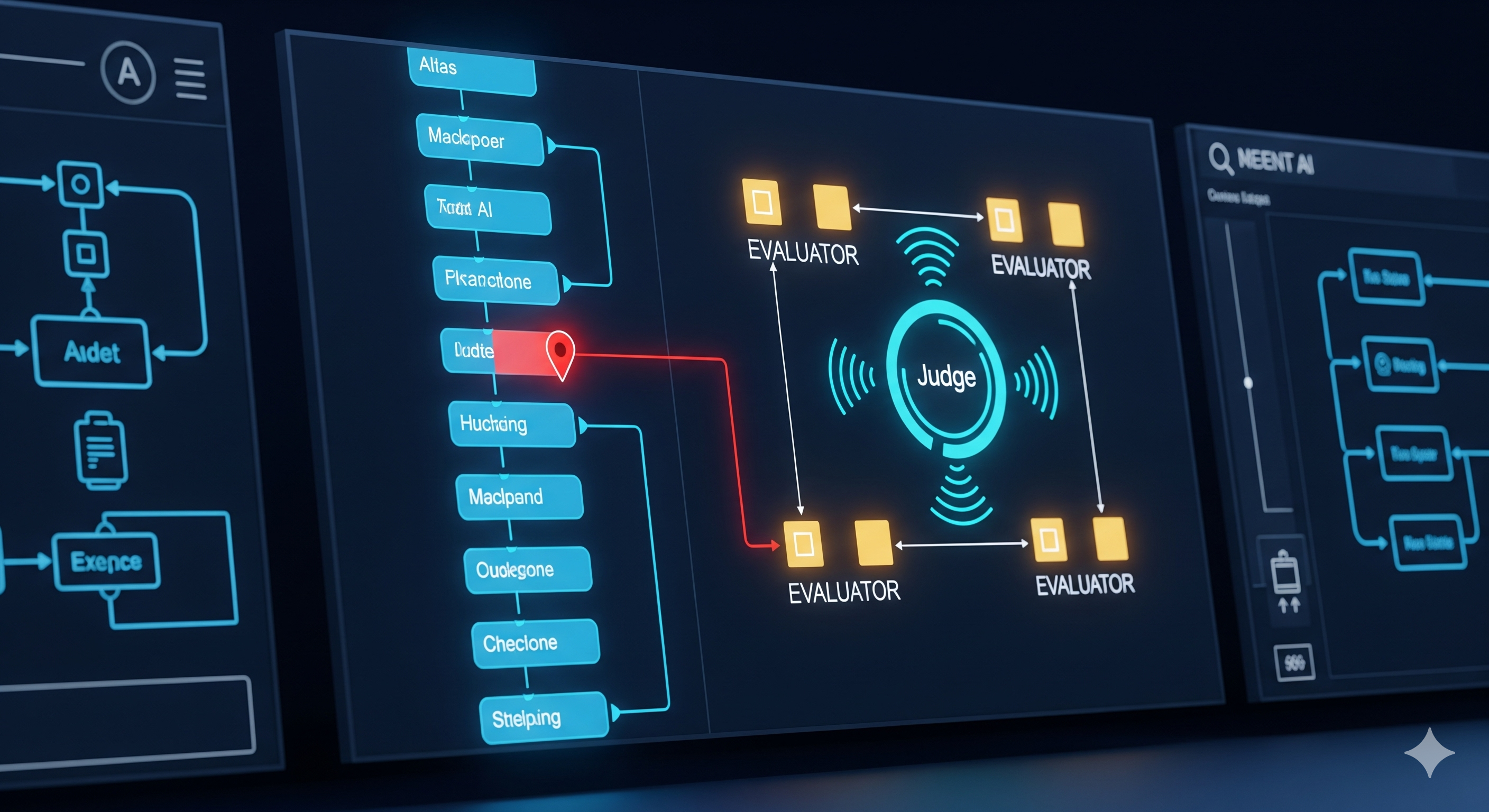
RAFFLES runs an iterative Judge–Evaluator pipeline over a full trajectory:
-
Judge proposes a candidate (agent i, step t) as the decisive fault, with structured rationales for three criteria:
- Fault condition: a real mistake occurred at (i, t).
- Primacy: it’s the first causal mistake.
- Non-correction: later steps didn’t correct it (nor could reasonably correct it).
-
Evaluators (E1–E3 + rule-check) critique those rationales independently—each focused on one criterion—and return natural-language confidence scores.
-
Memory H accumulates critiques; the Judge revises the candidate and rationales. Early stopping triggers when total confidence exceeds a threshold (or after K iterations; authors typically use K = 2).
Net effect: a reasoned search for the first causal domino, with built-in cross-examination.
What changes versus existing baselines
- Versus one-shot judges: RAFFLES decomposes the claim (fault / first / non-corrected) and subjects it to adversarial checks, rather than issuing a monolithic verdict.
- Versus routers / binary search: it preserves global context while zooming in, avoiding the myopia of partial windows.
- Versus flexible tool-callers: it trades “agentic freedom” for structured reliability—less clever wandering, more disciplined reasoning.
Results at a glance (Who&When benchmark)
Strict step-level accuracy (identify the exact failing step):
| Method (Representative) | Algorithmic subset | Hand-Crafted subset |
|---|---|---|
| One-shot LLM judge | ~19% | ~7% |
| Router (Step-by-Step / Binary) | ~0–16% | ~0–14% |
| Tool-Caller (planner+judge) | ~17–33% | ~7–17% |
| RAFFLES (K=2) | ~44% | ~21% |
Tolerance helps (±k steps). Under a ±2 window, RAFFLES sustains strong practical utility—often 70%+ on the algorithmic subset and ~26–30% on the hand-crafted subset—good enough to guide a human reviewer straight to the critical neighborhood.
Takeaway for teams: You don’t need perfect pinpointing to slash debug time. A small window around the decisive step already pays for itself.
Practical implications for enterprise agent stacks
1) Treat evaluation as an agent too.
- Implement a Judge that must write down three separate rationales (fault, first, non-corrected) for its choice.
- Add targeted Evaluators that check each rationale and return a confidence integer (0–100) with a short justification.
2) Adopt step-level metrics.
- Track strict step accuracy and tolerant step accuracy (±k)—they tell you how much human review remains.
- De-emphasize agent-only accuracy when labels are imbalanced (e.g., WebSurfer ≫ other agents). It can be misleading.
3) Expect long-context drift—and contain it.
- Use early stopping (fixed K) and confidence thresholds; iterative self-critique isn’t monotonic.
- Keep full trajectories available—but let Evaluators quote localized snippets to anchor claims.
4) Turn insights into fixes.
- Classify decisive faults by type (planning vs retrieval vs tool-use vs code vs verification). Map each to playbooks (e.g., “planner hallucination → enforce schema + plan-checker with queries-to-criteria”).
- Instrument your orchestrator to auto-collect the H memory and verdicts as artifacts for governance.
A mini example: RAG pipeline gone sideways
- Symptom (final): wrong summary.
- RAFFLES flow: Judge claims the decisive fault is retrieval@t=4 (irrelevant top-k due to bad query), not generation@t=12.
- Why: E1 finds verifiable mismatch between retrieved docs and query intent; E2 shows earlier steps were fine and no prior causal error exists; E3 argues later self-reflection didn’t correct the off-target corpus. Fixing t=4 flips outcome.
- Remediation: strengthen query reformulation, inject semantic filters, and add a retrieval-verifier Evaluator to catch future misfires.
Caveats & open questions
- Data scarcity: fault-attribution datasets are nascent; labels can be noisy. Don’t overfit to a single benchmark.
- Context limits: very long logs (hundreds of thousands of tokens) still stress today’s models; chunking strategies may be needed.
- Early-step bias: judges can over-select early steps; require Evaluators to explicitly test plausible later candidates.
- Cost & latency: iterative evaluation is pricier than one-shot scoring. Use it selectively—e.g., for failures, regressions, high-stakes runs.
A builder’s checklist (copy/paste)
- Persist full trajectories with step indices, agent IDs, tool I/O.
- Implement Judge with structured fields:
fault_reason,first_mistake_reason,non_correction_reason. - Implement Evaluators: (E1) fault check, (E2) primacy check, (E3) non-correction check, (E4) log-consistency rule.
- Use confidence aggregation + early stopping (K ≤ 2–3).
- Report strict and ±k tolerant step accuracy; archive H memory for audits.
- Close the loop: map decisive-fault types → targeted orchestrator patches.
Cognaptus: Automate the Present, Incubate the Future