TL;DR for operators
OnGoal is not another attempt to make the chatbot magically “understand intent”. That would be adorable, and also not the paper. It is a goal-observability interface: a way to show users which goals the system thinks are active, how those goals change over a conversation, and whether each model response appears to confirm, contradict, or ignore them.1
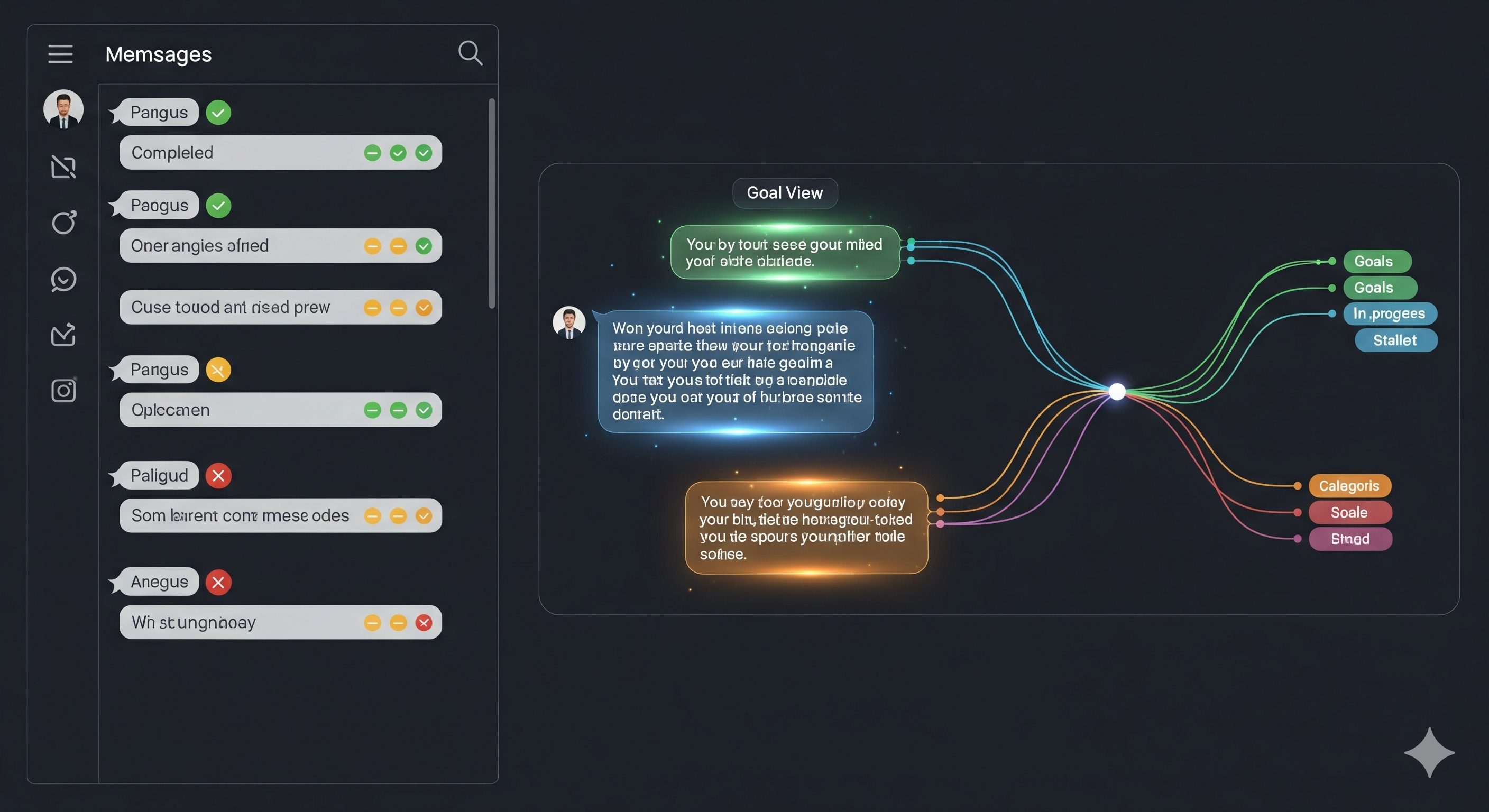
The paper’s useful idea is that long chat sessions should not be treated as scrollable transcripts. They should become inspectable work logs. OnGoal turns user requests, questions, offers, and suggestions into tracked goals; merges old and new goals when they overlap or conflict; evaluates model responses against those goals; and visualizes progress through inline glyphs, explanations, side panels, timelines, individual-goal views, and text highlighting.
The user study is modest but informative. In a 20-participant writing task, OnGoal users reported lower effort for reading and reviewing, lower mental demand, and higher confidence when evaluating goals. They also spent less time simply reading and more time evaluating or reviewing goal progress. That is not the same as proving better output quality. It means the interface shifted cognitive work away from rummaging through the chat log and toward explicit inspection.
For business teams building copilots, the lesson is immediate: bigger context windows do not solve the accountability problem. A 100-page chat history is still a haystack, only now with a luxury storage unit. Enterprise workflows need goal state, requirement history, contradiction alerts, evidence snippets, and reviewable progress snapshots.
The catch is important. OnGoal’s evaluation stage was the weak link. Participants rated infer and merge more accurate than evaluate, and some found the system’s judgements subjective or confusing. So the business version of this idea should not be “let the LLM grade itself and trust the colours”. It should be “make goal tracking visible, editable, auditable, and domain-calibrated”.
The ordinary chat log has no memory you can inspect
Everyone has had the same lovely experience: you ask an LLM for help, refine the answer, add constraints, correct a mistake, ask for a new version, then realise the model has quietly forgotten the thing you cared about twelve turns ago. The chat log is still there. Technically. Somewhere above the fold, buried under confident paragraphs and polite filler.
The problem is not only that models lose track of context. The user loses track too. A long LLM conversation forces people to remember which requirements were introduced, which ones were satisfied, which ones were replaced, which ones contradicted each other, and which ones the model nodded at before wandering off into the shrubbery.
OnGoal’s core insight is that this is an interface problem as much as a model problem. The paper does not claim to fix the model’s reasoning. It adds a visible layer above the conversation so the user can inspect the conversation’s goals as they evolve.
That distinction matters. Most enterprise AI product discussions still confuse three different things:
| Layer | Typical product instinct | OnGoal’s correction |
|---|---|---|
| Model capability | Use a stronger model with longer context | The model may still miss, reinterpret, or over-prioritise goals |
| Prompting | Write clearer instructions | Users often do not know which instruction failed until after the damage |
| Interface | Show the transcript | A transcript is not a state tracker; it is evidence storage with terrible ergonomics |
OnGoal is in the third layer. It asks: what should the interface show while the conversation is still alive?
The mechanism starts by turning user intent into objects
OnGoal defines conversational goals as user questions, requests, offers, or suggestions. This is deliberately simple. The system is not trying to model every psychological nuance of intent, because that road ends in a product meeting where someone says “holistic alignment layer” and everyone deserves to go home early.
Instead, OnGoal turns clauses in the user’s message into goal objects. In the paper’s implementation, this is done by a separate goal pipeline using GPT-4o, independent from the chat model the user is interacting with. The pipeline runs in three stages:
- Infer goals from the latest user message.
- Merge those inferred goals with existing goals from the conversation.
- Evaluate the chat model’s response against the final set of goals.
The merge step is where the paper becomes more interesting than a glorified checklist. New goals can combine with old ones, replace contradictory ones, or remain unique. That matters because real conversations do not behave like static requirement documents. Users revise, narrow, contradict, and soften their own requests. The interface has to preserve that movement without turning the workflow into a courtroom filing system.
The evaluation step then assigns each goal-response pair one of three statuses: confirm, contradict, or ignore. It also generates a short explanation and extracts supporting phrases from the model response. Those outputs become the raw material for the interface.
So the operating loop looks like this:
User message
→ inferred goals
→ merged goal state
→ response-level evaluation
→ visual feedback
→ revised user prompting
That loop is the real contribution. OnGoal does not merely label the chat after the fact. It creates a feedback circuit while the user is still steering.
The interface makes goal state visible in several ways
The paper’s system design is built around a familiar linear chat interface. This is important. Prior tools have explored more radical conversation structures: threads, diagrams, branching views, visual workspaces. Those can be powerful, but they also demand a new mental model from the user. OnGoal takes the more conservative route: keep the chat, add goal instrumentation around it.
That instrumentation appears in three main forms.
First, OnGoal adds inline goal glyphs beneath messages. Under a user message, the glyphs show the inferred goals. Under an LLM response, they show whether the active goals were confirmed, contradicted, or ignored. Clicking a glyph opens an explanation and supporting evidence. This gives the user a local answer to a local question: what did the system think happened here?
Second, OnGoal includes a progress panel with multiple views. The goals tab lists active goals and allows control actions such as locking, completing, or restoring goals in the full system. The timeline tab visualizes inference, merge, and evaluation events over time. The events tab gives a more verbose record of pipeline operations. In the user study, some controls were disabled for experimental consistency, but the design direction is clear: the conversation needs a state dashboard.
Third, OnGoal offers individual-goal views and text highlighting. Selecting a goal filters the chat to responses evaluated against that goal. Highlighting then helps the user compare key phrases, similar sentences, and unique sentences across responses. This is not decorative colour. It is search, comparison, and diagnosis wrapped into the workflow.
The useful mental model is not “chat with highlights”. It is closer to a lightweight issue tracker for conversation state.
| Interface element | Immediate function | Operational meaning |
|---|---|---|
| Goal glyphs | Show inferred and evaluated goals near each message | Fast local inspection |
| Explanations | Explain why a response confirmed, contradicted, or ignored a goal | Reviewable rationale, though not guaranteed truth |
| Goals tab | Show active goals and their histories | Working requirement list |
| Timeline/events views | Show how goals were inferred, merged, and evaluated over time | Audit trail for dialogue state |
| Individual-goal view | Filter conversation by one goal | Requirement-level review |
| Text highlighting | Surface evidence, repeated phrasing, and differences | Faster diagnosis of drift, stagnation, or partial compliance |
This is why the paper is stronger as a mechanism story than as a feature list. Each interface element exists because a specific cognitive burden appears in long chat: remembering goals, comparing responses, noticing contradictions, and deciding what to ask next.
The study tested goal management, not general intelligence
The authors evaluated OnGoal with a 1 × 2 between-subjects study involving 20 participants. One group used a baseline chat interface. The other used OnGoal. The task was an LLM-assisted writing exercise: participants had to produce a five-paragraph article while satisfying six goals from two fictional bosses.
The goals were intentionally awkward. One boss wanted non-formal conversational language, storytelling, emotional appeal, imagery, and creative metaphors. The other wanted formal technical language, research-backed credibility, facts, and less figurative language. In other words: a normal day in content operations, minus the Slack messages.
This task design matters because it creates global, sometimes conflicting requirements. OnGoal is strongest at tracking global goals such as tone, style, persuasion, and imagery across a whole response. It is less designed for fine-grained local edits like “make paragraph three warmer but keep the second sentence formal”. The authors are explicit about that boundary.
The baseline condition was not blind to the goals. Both groups saw the same fixed goals, and the baseline interface still showed a limited goal list with inference enabled. The difference was that OnGoal users saw the richer merge, evaluation, visualization, explanation, and review tools. That makes the comparison cleaner: the paper is not simply testing whether seeing goals helps. It is testing whether visualising goal progress changes how people manage the conversation.
The main evidence is cognitive redistribution
The study’s most useful finding is not “OnGoal users were faster”. The picture is subtler.
Participants using OnGoal spent less time reading the chat during the task: 56.8 seconds on average, compared with 66.5 seconds in the baseline condition, with weak evidence. They spent slightly more time evaluating and reviewing goals during the task. During the later validation phase, OnGoal users spent substantially more time reviewing: 30 seconds versus 16.8 seconds, with strong evidence.
At first glance, spending more time reviewing sounds like a regression. It is not necessarily. The authors interpret this as a shift from passive reading to active inspection. Users were not drowning in the chat log; they were using the interface to interrogate goal progress.
The self-report measures support that interpretation. OnGoal users reported lower effort for reading, lower effort for reviewing, lower mental demand, and slightly higher confidence when evaluating. For example, reviewing effort was rated 2.0 for OnGoal versus 3.2 for baseline, with strong evidence. Mental demand was 2.7 for OnGoal versus 3.9 for baseline, also with strong evidence.
So the practical reading is:
| Result type | What the paper shows | What it means | What it does not prove |
|---|---|---|---|
| Time logs | OnGoal users read less and reviewed more, especially during validation | The interface shifted attention from transcript scanning to goal inspection | It does not prove faster task completion in all settings |
| Effort ratings | Users reported lower reading/reviewing effort and lower mental demand | Goal visibility reduced some cognitive burden | It does not prove objective output quality improved |
| Confidence | Users were somewhat more confident evaluating goals | Explanations and visual signals helped users form judgements | It may partly reflect influence from seeing system judgements |
| Behaviour | Users tried more adaptive prompting strategies | Feedback changed how users communicated with the model | It does not prove the model itself became more capable |
That last row is the business prize. OnGoal made users behave differently. Baseline users often tried the classic doomed move: put everything in the initial prompt, then repeat themselves when the model failed. OnGoal users were more likely to refine requests, target specific sections, compare their own judgement with the system’s explanation, and adjust their strategy.
The system did not automatically fix misalignment. It made misalignment more visible, which gave users something concrete to respond to.
The weak link is evaluation, which is exactly where products will overclaim
The study also surfaces a problem that enterprise teams should treat as a flashing yellow light: goal evaluation is hard.
Participants rated the pipeline’s infer stage reasonably well in both conditions. Baseline users rated inference at 3.6 out of 5; OnGoal users rated it at 4.1. OnGoal users rated merge at 4.0. But they rated evaluate at only 2.9, and the paper reports that the difference between infer and evaluate was statistically significant.
This is not a minor implementation detail. It is the boundary between useful observability and false authority.
Inferring that a user asked for “more formal language” is one thing. Judging whether a generated response is sufficiently formal, sufficiently evidence-based, or sufficiently rich in imagery is messier. These are not always binary conditions. They are often matters of taste, context, threshold, and intent.
Some participants found the system’s explanations contentious. Others were confused when the evidence snippets appeared to support a different judgement from the label. That is the classic explainability trap: the system gives a reason, and now the user must decide whether the reason is helpful, wrong, or merely wearing a nice suit.
For business products, the implication is straightforward: do not present goal evaluation as oracle truth. Present it as a review signal.
A production-ready version should allow users to correct evaluations, adjust thresholds, mark examples as relevant or irrelevant, and distinguish between hard constraints and subjective preferences. “Must include regulatory disclaimer” is not the same kind of goal as “make it more energetic”. Treating both as the same coloured icon is how dashboards become theatre.
The business value is not prettier chat; it is requirement observability
The enterprise relevance of OnGoal is clearest when we stop thinking about writing assistance and start thinking about any workflow where the user’s intent accumulates over turns.
Sales teams ask copilots to draft proposals while preserving price constraints, customer objections, legal clauses, tone, and competitive positioning. Analysts ask AI systems to explore data while keeping hypotheses, assumptions, filters, and caveats intact. Support teams ask assistants to resolve cases while respecting policy, escalation triggers, customer history, and promised next steps. Compliance teams ask models to review documents while remembering jurisdiction, risk category, evidence source, and reviewer intent.
In all of these workflows, failure is rarely just “the model gave a bad answer”. Failure is often “the model answered one requirement beautifully while quietly ignoring three others”.
OnGoal suggests a product pattern:
Conversation → Goal state → Evidence-linked evaluation → User correction → Updated goal state
That pattern is more valuable than another prompt template library. Prompt templates help at the start. Goal logs help when work changes.
| Enterprise use case | Goal objects to track | Useful OnGoal-style feature | Boundary |
|---|---|---|---|
| Proposal drafting | Client requirements, exclusions, tone, pricing claims | Requirement status panel and contradiction alerts | Needs domain-specific legal/commercial rules |
| Data analysis | Hypotheses, filters, metrics, caveats, assumptions | Timeline of analytical goals and evidence snippets | Must connect to actual data lineage |
| Customer support | Customer issue, policy constraints, promised actions | Goal completion checklist and escalation alerts | Should not replace policy enforcement |
| Compliance review | Rule categories, evidence anchors, reviewer notes | Evidence-linked goal evaluation and audit trail | Requires expert-validated evaluation criteria |
| Product research | Research questions, participant segments, synthesis themes | Individual-goal view across responses | Subjective synthesis needs human review |
The return on investment is not simply reduced time. It is lower review friction, fewer forgotten constraints, better handoff between humans and AI, and a clearer audit trail when something goes wrong. Very glamorous, obviously. But in enterprise software, “less mysterious failure” is often the real luxury feature.
The design lesson: goals need controls, not just labels
A naïve implementation of OnGoal would add coloured badges to chat and call it a day. That would miss the point.
The paper’s discussion points toward a more interactive future. Users need multiple ways to communicate goals: front-loaded instructions, incremental edits, reactive corrections, and inferred goals. They need alerts when goals conflict, when too many goals are merged, or when a goal has been ignored over multiple turns. They need snapshots that answer the operator’s actual question: “What is left unresolved?”
Most importantly, users need feedback controls over evaluation itself. If a user disagrees with the system’s judgement, that disagreement should update the goal pipeline. Otherwise the interface becomes another boss: confident, uneditable, and very good at generating meetings.
The article-level business principle is simple:
A goal-tracking copilot should make the system’s interpretation visible, but it should not make that interpretation final.
That means building for correction from the start. Editable goals. Adjustable thresholds. Domain-specific goal types. Evidence snippets with user validation. Separation between objective constraints and subjective preferences. Version history for goal changes. And, in regulated settings, a clear distinction between “the model thinks this goal is satisfied” and “the organisation accepts this as compliant”.
The evidence should be read as promising, not finished
OnGoal is a strong interface paper, but it is not a deployment blueprint by itself.
The study involved 20 participants and a controlled writing task. That is appropriate for HCI exploration, but it does not establish general performance across enterprise workflows. The authors did not benchmark the goal pipeline against expert annotations. The evaluation accuracy remains untested beyond user-reported ratings. Smaller models, different LLM architectures, and domain-specific models were not systematically compared. Local, fine-grained goal tracking remains future work.
There is also a subtle learning-effect issue. Some participants may have become better at reviewing simply by getting more familiar with the LLM during the task. The paper notes that it remains unclear how much of the improvement came from OnGoal versus growing familiarity.
These limitations do not weaken the central idea. They keep it in the correct box. OnGoal is best read as evidence for a design direction: goal observability can change how users manage long LLM conversations. It is not proof that automated goal evaluation is solved.
For business use, the responsible roadmap would look like this:
| Stage | What to build | Validation needed |
|---|---|---|
| Prototype | Extract and display goals from multi-turn workflows | User studies on whether teams notice missed constraints faster |
| Controlled pilot | Add merge history, contradiction alerts, and evidence snippets | Compare against human review logs and known failure cases |
| Domain calibration | Define goal types for sales, support, compliance, analysis, or legal work | Expert-labelled benchmark for goal satisfaction |
| Human feedback loop | Let users correct evaluations and update goal definitions | Measure whether corrections improve later evaluations |
| Governance layer | Store goal history, evidence, overrides, and final acceptance | Auditability, policy alignment, and reviewer accountability |
That is less exciting than announcing an “autonomous enterprise agent”. It is also more likely to survive contact with a procurement team.
The real playbook is goal truthfulness, not chatbot cleverness
The phrase “goal-truthful LLM” can sound grander than the paper warrants. OnGoal does not make the model truthful to user goals in any deep philosophical sense. It makes the conversation’s goal state more inspectable. That is already enough.
In the current chat paradigm, users often discover goal failure late. The model has produced something plausible, the transcript is long, the missing requirement is subtle, and the user is tired. OnGoal changes the failure mode. It moves the question from “Do I remember whether this was handled?” to “What does the interface say happened, what evidence supports it, and do I agree?”
That is a better question. It still leaves room for disagreement, error, and judgement. Good. Serious business workflows are not improved by pretending judgement disappeared. They are improved by making judgement easier to locate.
The long-term design lesson for AI products is not that every chat interface needs Sankey diagrams. Please, no. The lesson is that conversational AI needs stateful, inspectable representations of intent. Requirements should not live only inside prompts. Constraints should not be rediscovered by scrolling. Goal progress should not depend on the user’s heroic memory.
Chat logs are where conversations go to accumulate. Goal logs are where work becomes reviewable.
Cognaptus: Automate the Present, Incubate the Future.
-
Adam J. Coscia, Shunan Guo, Eunyee Koh, and Alex Endert, “OnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models,” arXiv:2508.21061, 2025; also appearing at UIST ’25. ↩︎