The punchline
Competitive analysis for drug assets isn’t a tidy table—it’s a scavenger hunt across press releases, registries, investor decks, and alias-riddled drug names. A new paper shows that scaffolded, web-native LLM agents can reliably enumerate true competitors for a given indication, then filter hallucinations with an LLM-as-judge, beating popular “deep research” tools and cutting analyst turnaround from ~2.5 days to ~3 hours.
This matters now: the EU’s Joint Clinical Assessments (JCA) regime makes comparator choice visible and consequential; missing a relevant competitor can ripple into pricing, market access, and trial design. In short: MoA (mechanism of action) meets moat (defensible advantage)—and the moat is built from recall.
What’s genuinely new here
1) A domain-grounded benchmark built from real diligence
- Five years of a biotech VC’s memos are parsed into an indication → competitor list → attributes corpus.
- Crucially, the team accepts that there’s no paywall-free “ground truth.” Instead, they operationalize recall against expert-curated lists and measure precision with a conservative validator agent.
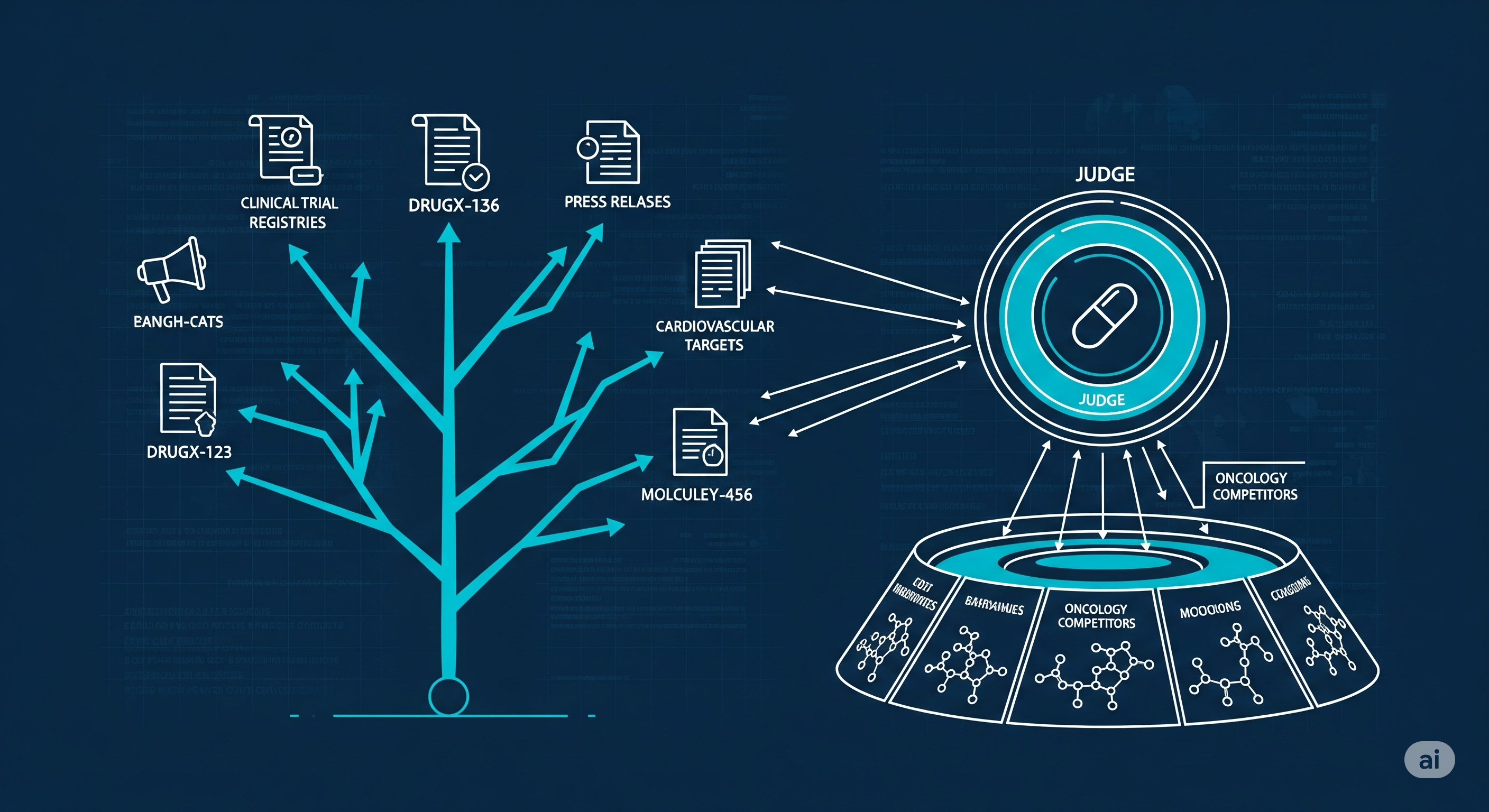
2) An agentic architecture that privileges coverage
- Explorer: A REACT-style web agent (step-parallel fan‑out + tool choice across Gemini/Perplexity) hunts competitors with deterministic low‑temperature runs; on hard cases it persists with more hops.
- Validator: A second LLM (LLM‑as‑judge, web‑grounded) applies strict inclusion rules (must show indication‑level clinical/pre‑clinical evidence), suppressing false positives before results hit the analyst.
- Alias resolution: LLM judgment replaces brittle synonym lists (e.g., brand/generic, salt forms, code names) to avoid undercounting.
3) Production discipline
- Versioned prompts, CI/CD checks for recall & precision, budget/timeout limits per tool, and an analyst‑in‑the‑loop UI. The result: 20× faster competitive scans in a VC case study.
The headline results (business lens)
-
Recall, filtered for precision (after validator):
- REACT‑12 step‑parallel ensemble: 0.83
- OpenAI Deep Research (UI): 0.65
- Perplexity Labs (UI): 0.60
- Frontier “no‑web” baseline: 0.67
-
Attributes extraction (selected metrics):
- Modality: 100%
- Status & Stage: 92%
- Company info (site + ticker + description): 89%
- MoA & Targets: ~61% / 84% (hardest field remains MoA; still decision‑useful but requires human glance)
-
Operational impact: ~20× cycle‑time reduction (2.5 days → ~3 hours) without sacrificing analyst‑verified precision—and with previously unseen, valid competitors surfaced beyond historical lists.
Why you should care: Comparator choice is an ROI lever. If your asset’s trial comparator set is incomplete, you risk over‑ or under‑performing against the wrong yardstick, which drives price, access, and partner negotiations downstream.
How the agent stays accurate without becoming timid
The paradox: Web agents that chase every long‑tail mention tend to hallucinate; agents tuned for precision miss the tail.
The resolution: Separate search from selection.
-
Search for breadth (REACT with parallel queries):
- Multi‑hop, tool‑switching web searches.
- Step‑summaries keep a structured memory of candidates & evidence.
-
Select for evidence (LLM‑as‑judge with strict rules):
- Include only drugs with verifiable indication‑level evidence: trial registry entries, approvals, or preclinical/IND‑enabling work tied to that indication.
- Exclude umbrella platforms, wrong identifiers, adjacent‑but‑distinct indications, and purely mechanistic hypotheticals.
-
Normalize names via judgment, not regex:
- Let the judge map Utrogestan ↔ Progesterone and code names ↔ brands to prevent recall loss.
A quick comparison table
| System / Setting | Web‑native? | Scaffolding | Recall (filtered) | Notes |
|---|---|---|---|---|
| REACT‑12 step‑parallel (ensemble) | Yes | REACT + fan‑out | 0.83 | Best coverage at fixed precision; deterministic base runs + small ensemble |
| OpenAI Deep Research (UI) | Yes | Vendor agent | 0.65 | High precision, lower coverage on fragmented cases |
| Perplexity Labs (UI) | Yes | Vendor agent | 0.60 | Similar pattern: precise but misses long tail |
| o3‑pro (no web) | No | Single‑pass | 0.67 | Collapses on “hard” indications; good only on popular/linked assets |
Interpretation: On hard indications (where non‑web models recover ≤40% of ground truth), scaffolded web agents degrade far less, implying the biggest gains precisely where diligence risk is highest.
Design pattern you can reuse beyond biotech
This paper’s recipe is portable. Here’s the blueprint to adapt to, say, fintech competitor scans, cybersecurity vendor mapping, or SaaS feature parity checks.
-
Bootstrap a truthy corpus from your past work Turn analyst notes, deal memos, or win/loss reports into normalized JSON (entity → segment → competitors → attributes). Accept that it’s incomplete, but make it measurable.
-
Separate exploration from validation
- Explorer agent maximizes recall with multi‑hop, parallel web queries and tool choice.
- Validator agent enforces inclusion rules tied to your definition of a competitor (market, segment, geography, regulation).
- Codify messy realities
- Alias/ontology mismatches are the norm; use LLM‑judged alias resolution and controlled vocabularies with open‑world extension.
- Ship with ops guardrails
- Version prompts and datasets; add CI checks for recall/precision; set time/budget per tool; expose an analyst‑in‑the‑loop UI.
- Measure what moves the business
- Track: time to first credible list, analyst edits per asset, precision on validator pass, and delta‑competitors that change decisions (e.g., comparator selection, pricing comps).
Where it still struggles—and what to do about it
- Mechanism‑of‑Action (MoA) granularity: Still the noisiest attribute. Practical fix: present MoA with a confidence flag and 2–3 citations; route low‑confidence cases to humans.
- Adjacent indications & lines of therapy: Requires clinical nuance. Fix: encode indication ontologies + line‑of‑therapy rules in the validator prompt and add a mini‑checklist (e.g., adjuvant vs metastatic, first‑ vs later‑line).
- Paywalled silos: The best sources are often licensed. Fix: let the agent see both public web and your licensed APIs; keep audit traces of evidence.
A simple operating model for teams
- Day 0: Convert last year’s diligence docs to a seed corpus; define “competitor” for your context; craft validator rules.
- Day 1: Stand up the REACT explorer + validator; wire to a review UI; set budgets.
- Week 1: Add CI metrics; track analyst overrides; retrain validator prompts on new negatives.
- Month 1: Expand attributes (company/ticker, stage, trial IDs); integrate your paywalled sources; start pushing comparator recommendations into trial/HEOR workflows.
Bottom line
If your diligence still depends on hero analysts and spreadsheets, you’re leaving moat on the table. Agentic web exploration for breadth + LLM‑as‑judge for evidence is the practical pattern that flips competitor discovery from an artisanal craft to an auditable, accelerated service. In regulated domains like biopharma—where comparator mistakes echo into market access—this is not a nice‑to‑have. It’s table stakes.
Cognaptus: Automate the Present, Incubate the Future.