If you put a large language model in a classroom for a year, what kind of student would it become? According to Simulating Human-Like Learning Dynamics with LLM-Empowered Agents, the answer isn’t flattering: most base LLMs act like “diligent but brittle surface learners”—hardworking, seemingly capable, but unable to generalize deeply.
From Psych Lab to AI Lab
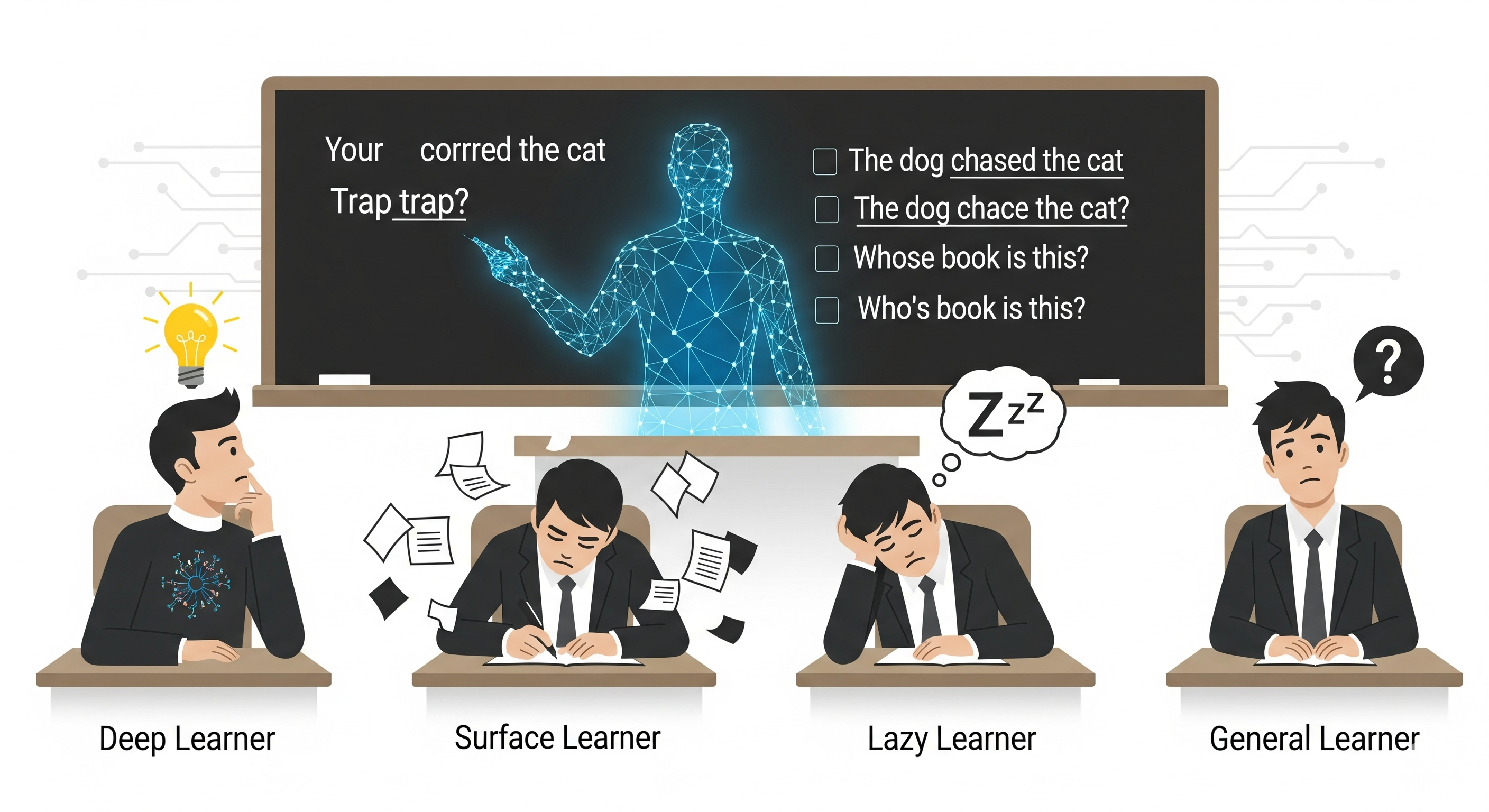
Educational psychology has spent decades classifying learners into profiles like deep learners (intrinsically motivated, reflective, conceptual) and surface learners (extrinsically motivated, test-oriented, shortcut-prone). The authors built LearnerAgent, a multi-agent framework grounded in these theories, and dropped four AI ‘students’ into a simulated high school English class:
| Profile | Motivation | Self-Concept | Development Strategy |
|---|---|---|---|
| Deep Learner | Intrinsic | High | Long-term, reflective |
| Surface Learner | Extrinsic | Moderate | Test-oriented |
| Lazy Learner | Minimal | Low | Passive |
| General Learner | None | Emergent | Whatever the base LLM defaults to |
Over 12 months, these agents attended weekly lessons, made study/rest decisions, sat monthly and final exams, and debated peers. Their memories were split into short-term (last 3 turns) and long-term (structured history retrieval) stores, allowing behaviours like reviewing past mistakes or recalling debate arguments.
Trap Questions: The Great Equalizer
The most telling evaluations were trap questions: items structurally similar to past exercises but with a subtle twist in meaning. These tripped up every profile except the Deep Learner. For instance:
- Weekly: “Take a photo of the broken cup” → correct.
- Monthly trap: “Take a photo of the cup as it hits the floor” → correct is breaking.
Only the Deep Learner adapted. Surface, Lazy, and General reused “broken” without rethinking—a perfect illustration of shortcut learning.
What Emerged from the Simulation
The longitudinal data paints a clear hierarchy:
- Deep Learner steadily improved in all categories, dominated trap questions, and used the richest reasoning (longest answers, most contrastive logical connectors).
- Surface Learner excelled at short-term review questions but collapsed on traps, mirroring many human cram-and-forget patterns.
- Lazy Learner was erratic, resting more and engaging less.
- General Learner—the base LLM—looked good on paper (high self-improvement rate, strong knowledge integration) but performed like a surface learner when challenged.
A striking psychological twist: the General Learner’s self-concept (confidence) climbed to match the Deep Learner’s by year-end, despite its shallow reasoning gaps. Overconfidence in LLMs isn’t just a user perception issue—it can be an emergent trait.
Why Businesses Should Care
For enterprises adopting LLMs, this research is a warning: your model may be a ‘star student’ in routine tasks but brittle under domain shifts or subtle problem changes. Like a junior analyst who aces template reports but falters when the data pattern breaks, an LLM trained without cognitive scaffolding will:
- Over-rely on pattern reuse – great for speed, risky for novel cases.
- Display inflated confidence – may assert wrong answers with persuasive language.
- Underperform in transfer learning – struggle to apply known concepts in unfamiliar contexts.
These are not abstract risks. In regulated sectors (finance, healthcare, law), a single trap-like misinterpretation can mean compliance failures or costly errors.
Toward Deeper AI Learning
The authors argue—and I agree—that frameworks like LearnerAgent could be used to train the trainers of AI systems. By identifying where an LLM’s “student” profile falters, developers can:
- Introduce structured reflection phases in fine-tuning.
- Use adversarial ‘trap’ data to stress-test generalization.
- Align evaluation metrics not just to accuracy but to reasoning robustness.
It’s a shift from treating LLMs as static models to treating them as evolving learners whose cognitive styles can be shaped.
Final Thought
If your LLM is a student, don’t be fooled by perfect attendance and neatly written essays. The real measure is how it handles the unexpected. In AI, as in school, depth beats diligence when the exam changes.
Cognaptus: Automate the Present, Incubate the Future