
Most LLM editing approaches operate like sledgehammers—bluntly rewriting model weights and praying generalization holds. But a new method, Latent Knowledge Scalpel (LKS), dares to be surgical. Rather than changing the model itself, it targets how the model thinks—rewriting entity representations in the hidden layers, like swapping memories without touching the brain.
From Entities to Knowledge Blocks
The authors begin with a provocative observation: the internal representation (embedding) of an entity like “Alfred Nobel” doesn’t just encode a name, but a structured, meaningful knowledge block (KB). These latent vectors reflect factual associations like birthplace or occupation, and remarkably, they retain semantic and syntactic structures. For instance, swapping Nobel’s KB with that of “Shelley” shifts the model’s predicted birthplace from Sweden to England—even though the prompt wasn’t changed.
This sets the stage: if entity KBs encode structured knowledge, why not edit them directly?
The Scalpel Design: Lightweight, Modular, Powerful
LKS consists of three cleanly separated modules:
- Edit Scope Indicator: Detects if a prompt involves an entity to be edited, using fuzzy matching (e.g., Levenshtein distance).
- New KB Generator: A simple, compact neural network (linear or MLP) trained to produce an updated representation of the entity, reflecting the new knowledge.
- KB Replacer: Hooks into a selected transformer layer and swaps the entity’s original latent representation with the updated one, leaving the rest of the model untouched.
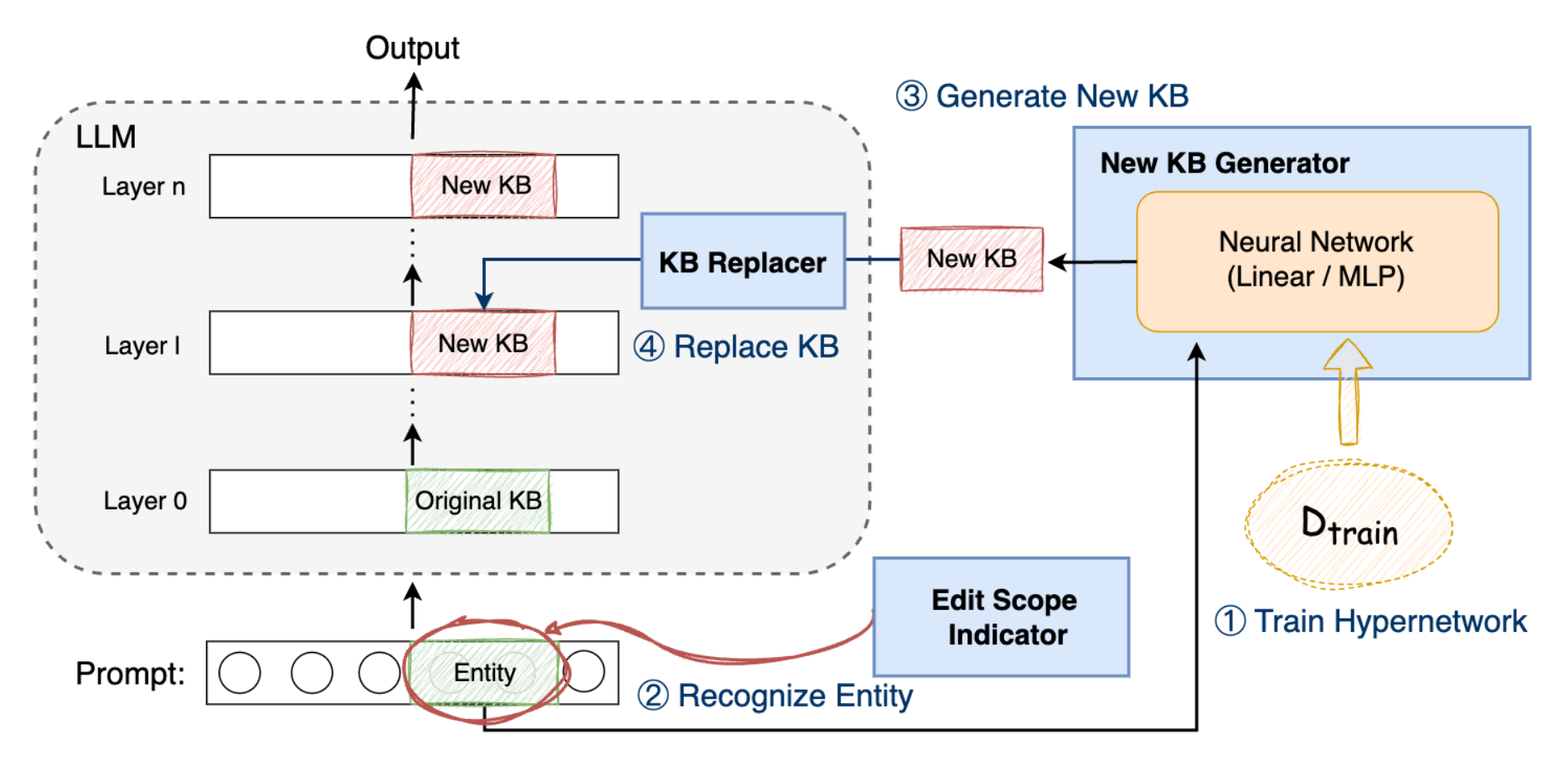
Because LKS only injects a single vector into a single layer during inference, it is fast, precise, and preserves the model’s behavior outside the edit scope. The actual LLM weights remain frozen.
Massive Editing? No Problem
One of the standout features of LKS is its ability to scale.
| # of Edits | LKS Edit Performance (EP) | MEMIT EP | AlphaEdit EP |
|---|---|---|---|
| 10 | 93.7% | 78.0% | 79.0% |
| 1,000 | 91.1% | 60.3% | 71.7% |
| 10,000 | 88.5% | 29.1% | 7.82% |
Unlike MEMIT or AlphaEdit, which degrade dramatically as the number of simultaneous edits increases, LKS maintains high performance even at 10,000 edits. The key lies in how it uses a trained hypernetwork to compress factual updates into efficient latent codes.
How is this even possible?
The authors provide a clever training strategy:
-
Generate factual updates and paraphrased prompts using GPT-4o-mini.
-
Train the hypernetwork to minimize three losses:
- Edit loss: match updated fact.
- Equivalence loss: generalize to paraphrases.
- Locality loss: preserve unrelated predictions (measured via KL divergence).
The result is a highly localized and generalizable editing mechanism that doesn’t require retraining the main model.
Preserving Fluency and Reasoning
A persistent fear with model editing is damaging general abilities. LKS addresses this head-on:
- On benchmark tasks like GSM8K (math reasoning), RTE (NLI), and SST2 (sentiment), LKS-edited models perform nearly identically to their vanilla counterparts.
- In contrast, competitors like MEMIT and AlphaEdit suffer drastic drops, particularly on tasks requiring logical reasoning.
- Fluency is also preserved: LKS achieves equal or better n-gram entropy than all baselines.
| Model | GSM8K Acc | RTE Acc | SST2 Acc | Fluency (n-gram entropy) |
|---|---|---|---|---|
| Vanilla | High | High | High | 5.36 / 6.09 |
| LKS (10k ed) | ~Equal | ~Equal | ~Equal | 5.65 / 6.01 |
| MEMIT | Lower | Lower | Lower | 5.34 / 5.88 |
| WISE | Unstable | Varies | Drops | 2.60 / 3.30 |
Implications: Editing Without Forgetting
The central innovation of LKS is showing that LLMs can be massively and precisely edited without retraining or degradation—as long as edits are treated as vector-level surgeries in semantic space.
This approach radically shifts the paradigm:
- ✅ Modular: LKS edits are plug-and-play, affecting only specific entities.
- ✅ Scalable: Up to 10,000 facts edited with no weight change.
- ✅ Safe: Preserves reasoning, sentiment, and fluency.
It paves the way for lifelong factual updating, domain-specific personalization (e.g., brand knowledge), or redaction of sensitive content—without the fear of model collapse.
Final Thoughts
LKS embodies a subtle but powerful shift in how we think about LLM memory: not as monolithic weights to be rewritten, but as composable, interpretable knowledge blocks that can be swapped like LEGO pieces. If the promise holds in larger-scale, multi-domain systems, we may have found the right tool for the job—not a hammer, but a scalpel.
Cognaptus: Automate the Present, Incubate the Future.