
The Trouble With Stack Overflow-Style Benchmarks
Large language models (LLMs) have been hailed as revolutionizing programming workflows. But most coding benchmarks still test them like they’re junior devs solving textbook exercises.
Benchmarks such as HumanEval, MBPP, and even InfiBench focus on code synthesis in single-turn scenarios. These tests make models look deceptively good — ChatGPT-4 gets 83% on StackEval. Yet in real development, engineers don’t just ask isolated questions. They explore, revise, troubleshoot, and clarify — all while navigating large, messy codebases.
What happens when we drop LLMs into actual GitHub issues and ask them to help across multiple turns with real project context?
Introducing CodeAssistBench: A New Standard
The team behind CodeAssistBench (CAB) has built exactly that. It’s not just a benchmark — it’s a simulated workplace.
CAB includes 3,286 real GitHub issues pulled from 231 repositories across seven languages. Each issue is turned into a simulated multi-turn dialogue between a user (asking for help) and an LLM-based “maintainer agent.” The maintainer gets access to the full codebase and a containerized environment (via auto-generated Docker builds). The conversation continues until either the user is satisfied or they give up.
This is an ambitious leap forward from prior benchmarks, which mostly:
| Benchmark | Single-Turn | Project Context | Auto Evaluation | Multi-Turn |
|---|---|---|---|---|
| HumanEval | Yes | No | Yes | No |
| SWE-Bench | Yes | Yes | Yes | No |
| StackEval | Yes | No | Yes | No |
| ConvCodeWorld | Yes | No | Yes | Partial |
| CodeAssistBench | No | Yes | Yes | Yes |
How It Works: Simulated Conversations, Real-World Stakes
Each CAB issue comes with:
- A real GitHub issue, reformatted into a multi-turn dialogue.
- A Docker container build for full environment access.
- Automatically extracted “satisfaction conditions” (what success looks like).
- A simulated user who probes the LLM based on reference interactions.
Evaluation isn’t a simple pass/fail test case. Instead, an LLM judge scores the model’s response on three axes:
- Technical correctness (Does it solve the problem?)
- Satisfaction alignment (Are the user’s goals met?)
- Interaction quality (Was it efficient and helpful?)
This is the closest we’ve come to evaluating LLMs not just as coders — but as collaborators.
Brutal Results: The Illusion of Competence
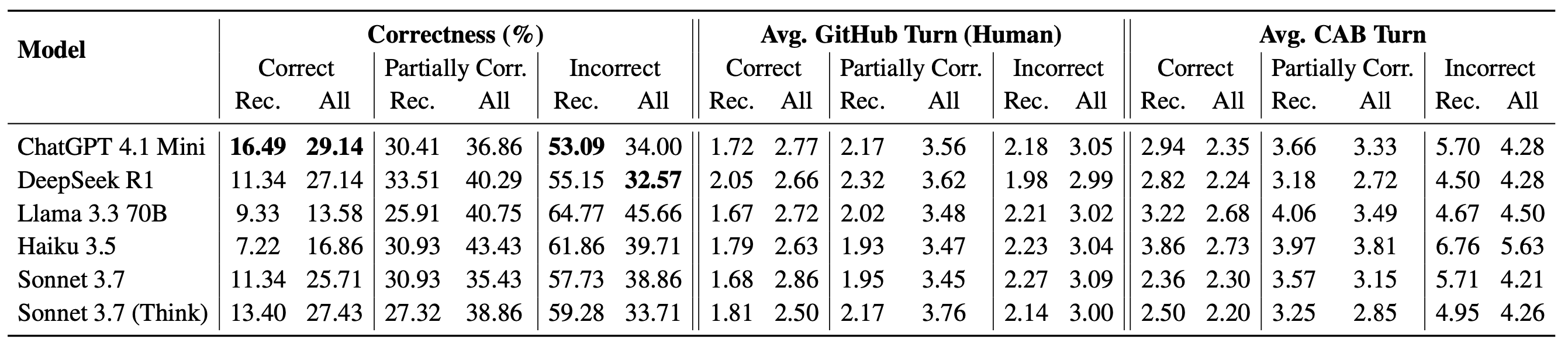
CAB makes one thing crystal clear: LLMs that shine on Stack Overflow questions collapse in real project contexts.
Take ChatGPT-4.1 Mini:
- On StackEval: ~83% correctness.
- On recent CAB issues: just 16.49%.
Other top models like DeepSeek R1, LLaMA 3.3 70B, and Sonnet 3.7 Think Mode fared even worse in many categories. Statically typed languages (C++, C#, Java) were particularly punishing.
Even on all-time GitHub issues (pre-2024), best-in-class models solve fewer than 30% of cases.
Here’s why:
- Many real issues demand contextual file edits, environment-aware debugging, and layered follow-ups.
- Existing models are brittle — giving up too easily or hallucinating paths and configs.
- Long, vague conversations wear them down. When the user doesn’t ask a clear follow-up, the LLM drifts or over-talks.
In other words, real developer interactions are not just harder — they’re a different species of problem.
Developer Expectations Are Higher Than Ever
According to the Stack Overflow 2024 developer survey, a majority of devs want AI tools not just for code generation, but for:
- 🔍 Searching for answers (77.9%)
- 🐞 Debugging and troubleshooting (77.3%)
- 🧠 Learning new codebases (73.6%)
CAB reflects this vision — and shows how far we are from it.
Why CAB Matters — and What Comes Next
CAB’s contributions go beyond just benchmarking:
- 🛠 It’s fully automated — enabling continuous updates from new GitHub issues.
- 🧪 It evaluates multi-turn agent performance, not just output quality.
- 📦 It simulates environment-dependent resolution, not just toy problems.
This is crucial for companies and researchers designing LLM-based engineering copilots. If your agent can’t navigate a 10-minute GitHub thread with code access, it’s not ready for production.
Yet CAB is also fair. By simulating users and providing extracted satisfaction conditions, it avoids subjective human evaluations and noisy test-case heuristics.
What’s Missing?
Even so, CAB has limits. Its condition extraction prioritizes precision over recall, meaning some user goals may be missed. Also, it only covers seven languages and open-source projects with permissive licenses — no enterprise code or obscure build setups.
But it sets a bar. Future iterations could expand into private corpora, better user simulation, and richer judgment schemas.
Final Thoughts
CodeAssistBench is a benchmark, but it feels more like a stress test for coding copilots.
As we imagine AI tools that truly pair with engineers — helping them dig through codebases, diagnose bugs, and explain architectural quirks — we need systems that train and test for that world.
CAB is the first credible step in that direction.
Cognaptus: Automate the Present, Incubate the Future