Document-level machine translation (DocMT) has long been riddled with a paradox: while LLMs can translate fluent paragraphs and even simulate discourse, they often falter at stitching meaning across paragraphs. Pronouns go adrift, tenses waver, and terminology mutates like a broken telephone game. The new paper GRAFT: A Graph-based Flow-aware Agentic Framework for Document-level Machine Translation proposes an ambitious fix: treat a document not as a sequence, but as a graph — and deploy a team of LLM agents to navigate it.
From Sentences to Segments: Why Graphs Matter
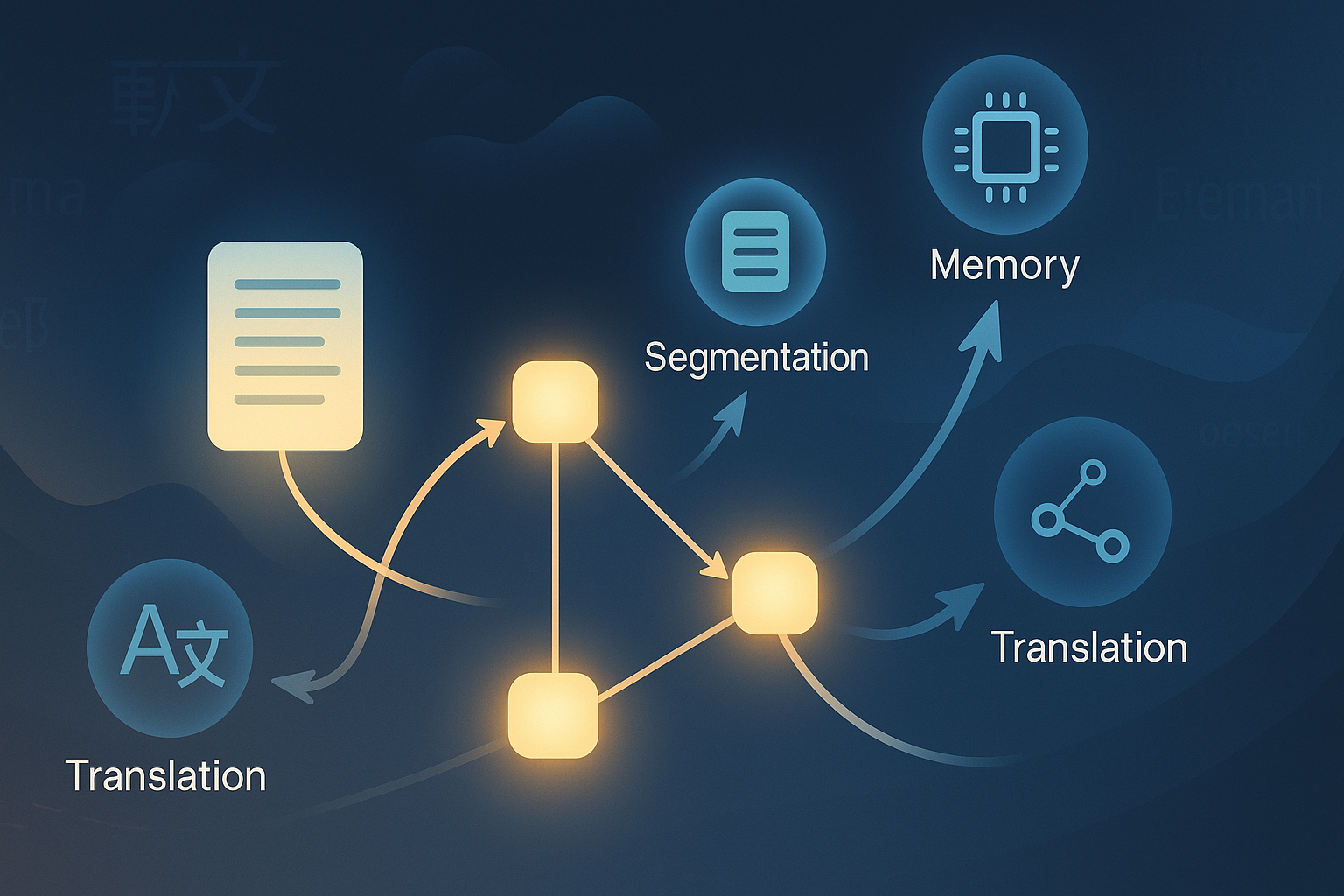
GRAFT’s core innovation is to represent the source document as a directed acyclic graph (DAG), where each node is a discourse segment — not arbitrarily split, but crafted by a segmentation agent (Discourse Agent) trained via LLM prompting. Edges are determined by an Edge Agent, which identifies whether a segment depends on another for accurate translation (e.g., resolving a pronoun or maintaining lexical cohesion).
Think of it as mapping out the flow of dependencies: who needs to know what, and when?
Compared to older methods that concatenate fixed context windows or use simple memory caches, the DAG structure is both flexible and expressive. It enables non-sequential context flow, such as when a later paragraph refers back to an earlier one without needing every sentence in between.
The Four Agents of Coherence
GRAFT’s architecture comprises four LLM agents working in concert:
| Agent | Role |
|---|---|
| Discourse Agent | Segments the document into coherent discourse units |
| Edge Agent | Creates edges to model translation dependencies between discourse units |
| Memory Agent | Extracts structured memory (e.g., pronoun mappings, connectives, phrase alignments) after each translation |
| Translation Agent | Uses context from connected nodes and memory to produce the final translation |
This agentic setup allows GRAFT to simulate a translator with a working memory and a discourse map, rather than one operating blindfolded sentence by sentence.
Why It Works: Beyond BLEU
The authors show that GRAFT, when implemented with LLaMA-3.1-70B or Qwen2.5-72B as the LLM backbone, outperforms strong baselines like GPT-4o-mini, DELTA, and even commercial systems like Google Translate on multiple translation directions (En-Zh, En-De, etc.).
Especially in domain-specific contexts — news, fiction, Q&A — GRAFT shines. It shows marked gains in:
- Terminology Consistency (cTT): up to 6% improvement
- Zero Pronoun Translation (aZPT): up to 7% gain over GPT-4o-mini
- Overall coherence: higher human evaluation scores, particularly on long-range dependencies
These aren’t just numerical improvements; they reflect better discourse fidelity, which is crucial when translating nuanced texts like legal contracts or novels.
Case in Point: Long-Form Resilience
In one striking example, GRAFT translated an entire novel (over 16K sentences) as a single document and scored 4.3 d-BLEU points higher than translating chapter by chapter. This reinforces the DAG’s role in preserving thematic continuity across large spans — something linear models can’t do without massive context windows and computational strain.
What This Means for the Future of MT
GRAFT is not just another LLM wrapper. It suggests a new way to think about document processing: as a structured traversal rather than a linear pass. This resonates with a broader trend we’ve observed in AI system design — from pipelines to agents, and from flat sequences to semantic graphs.
But perhaps more crucially, GRAFT reopens the door to modular, interpretable MT systems. With each agent’s output and memory traceable, debugging translation failures or aligning outputs to translation guidelines becomes more tractable than with monolithic black-box models.
Limitations and Trade-offs
Of course, the price is complexity. GRAFT makes multiple LLM calls per document, increasing latency and cost. Yet in domains where accuracy trumps speed, such as policy translation or high-stakes technical documentation, this trade-off is acceptable.
Moreover, its reliance on in-context learning means performance is still tethered to the quality of few-shot prompts. Fine-tuning or integrating lighter-weight agents could make GRAFT more scalable.
Final Thoughts
GRAFT’s agentic, graph-based architecture sets a new benchmark for discourse-aware translation. Its success affirms a growing intuition in NLP: structure matters — and not all structure is sequential.
For any AI team building next-gen translation tools, GRAFT offers more than an algorithm. It offers a blueprint.
Cognaptus: Automate the Present, Incubate the Future