If AI is going to understand people, it first has to understand relationships. But when it comes to parsing character connections from narrative texts — whether news articles, biographies, or novels — even state-of-the-art language models stumble. They hallucinate links, miss cross-sentence cues, and often forget what they’ve just read.
Enter SymbolicThought, a hybrid framework that gives LLMs a logic-boosted sidekick: symbolic reasoning. Developed by researchers at King’s College London and CUHK, the system doesn’t just extract character relationships from text; it builds editable graphs, detects logical contradictions, and guides users through verification with a smart, interactive interface.
The Problem: Language Models Think in Sentences, Not Structures
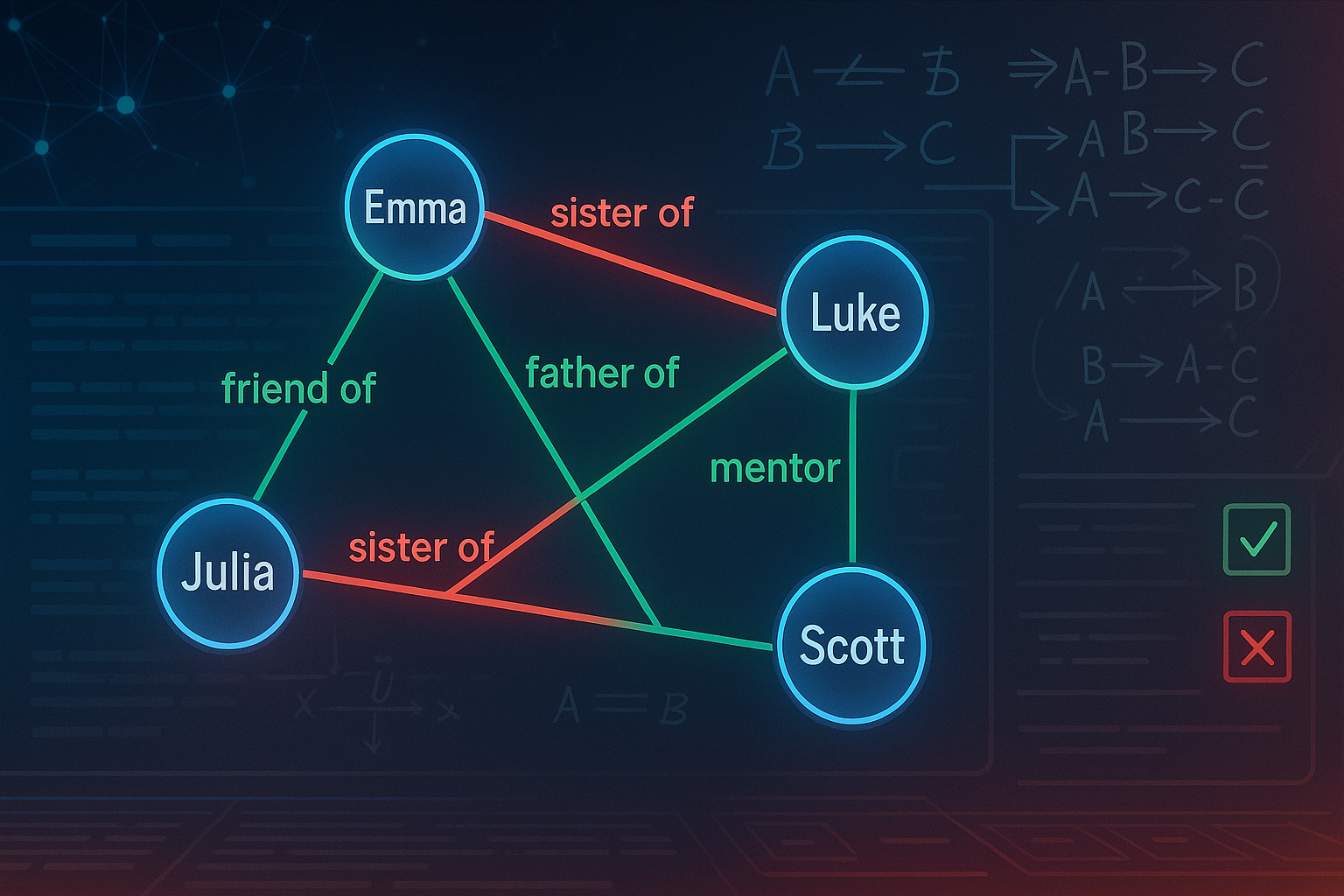
Narrative understanding isn’t just about identifying named entities. It’s about connecting them into a web of meaningful, coherent relationships: who loves whom, who betrayed whom, who raised whom. But most LLMs are linear thinkers. They process words in order, not holistically. That means they often:
- Miss symmetrical or inverse relationships (e.g., if A is B’s father, B should be A’s child).
- Fail to infer obvious links (e.g., if A is B’s wife and B is C’s son, A is likely C’s daughter-in-law).
- Propose contradictory edges (e.g., A is B’s daughter and also B’s father).
The result is messy, unreliable relationship graphs that require human clean-up.
The Solution: Injecting Symbolic Logic into the Loop
SymbolicThought tackles this with a two-step, human-in-the-loop system:
-
Character Extraction:
- An LLM proposes named entities with temperature sampling.
- Annotators confirm, merge aliases, and disambiguate homonyms via an intuitive UI.
-
Relationship Extraction & Refinement:
- Another LLM suggests relationship triples.
- A symbolic reasoning engine applies seven logical operations to infer missing edges and flag contradictions:
| Category | Example |
|---|---|
| Symmetry | A is friend of B ↔ B is friend of A |
| Inversion | A is parent of B ↔ B is child of A |
| Composition | A is sibling of B, B is child of C → A is child of C |
| Hierarchy | “elder brother” is a subtype of “brother” |
| Incompatible | A is father of B ≠ A is child of B |
| Asymmetric | A is boss of B → B cannot be boss of A |
| Exclusive | A is spouse of B → A cannot be spouse of C |
If a contradiction is detected, SymbolicThought highlights it in red and fetches supporting context using RAG (retrieval-augmented generation). Then it reframes the conflict as a multiple-choice prompt for the LLM, improving precision.
The Results: More Recall, Less Guesswork
SymbolicThought was tested on 19 narrative texts (biographies, histories, fictions). Compared with prompting, self-consistency, and self-reflection, it delivered consistent improvements in F1 score across all major models:
| Model | Prompting F1 | SymbolicThought F1 |
|---|---|---|
| GPT-4.1 | 33.4 | 37.9 |
| GPT-4o-mini | 9.9 | 18.8 |
| Qwen2.5-32B-Ins | 14.8 | 22.5 |
Even better: it outperformed human annotators in both recall and speed. For instance, on biography texts:
- Human Recall: 67.3% vs. SymbolicThought Recall: 91.4%
- Average Annotation Time: 87.2 mins vs. 45.5 mins
That’s not just a marginal gain. That’s a productivity doubling.
Why This Matters
This is more than annotation optimization. SymbolicThought points toward a hybrid AI future where statistical models generate, but symbolic systems validate and complete. It’s also a compelling case study in LLM limitations: even the best models struggle with graph structure, logic directionality, and implicit family ties.
For AI systems that aim to understand literature, legal documents, or social behavior — not to mention applications in explainable AI — this blend of LLMs + logic + interface is a powerful triad. It also shows the value of human-in-the-loop systems that highlight what machines miss, rather than blindly trusting their outputs.
Cognaptus: Automate the Present, Incubate the Future.