When language models take flight, consensus becomes not just possible, but programmable.
Modern UAV swarms face the daunting task of coordinating across partial observability, adversarial threats, and shifting missions. Traditional Multi-Agent Reinforcement Learning (MARL) offers adaptability, but falters when role differentiation or semantic reasoning is required. Large Language Models (LLMs), meanwhile, understand tasks and intent—but lack grounded, online learning. RALLY (Role-Adaptive LLM-Driven Yoked Navigation) is the first framework to successfully integrate these two paradigms, enabling real-time, role-aware collaboration in UAV swarms.
The Core Insight: Roles Aren’t Just Labels, They’re Policies
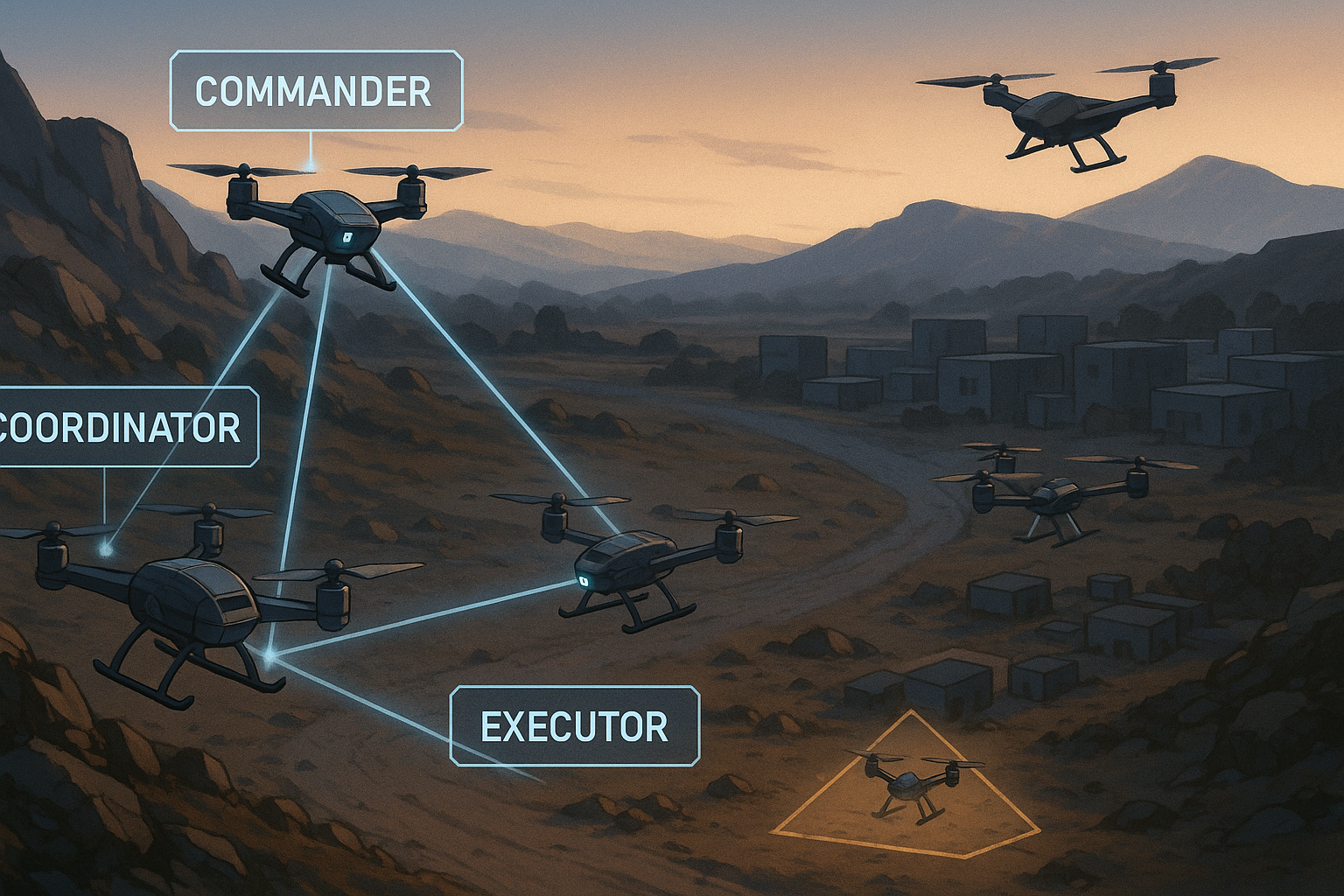
Most MARL approaches treat agents as interchangeable. But real-world UAV missions demand heterogeneous behaviors—a Commander to lead, a Coordinator to balance, and an Executor to follow. RALLY introduces dynamic role assignment, not as a static designation, but as a learned, context-aware policy.
It does so through a two-stage LLM-based reasoning process:
- Intention Generation (
LLMinit): Each UAV uses structured prompts to propose a goal and role based on local observation. - Consensus Refinement (
LLMcons): Agents exchange messages and refine decisions collaboratively via Chain-of-Thought (CoT) prompting.
This language-mediated consensus allows for human-like negotiation—even under limited bandwidth and partial observability.
Why Pure LLM or MARL Fails Alone
| Approach | Strengths | Limitations |
|---|---|---|
| MARL (e.g. CIHRL) | Dynamic learning, decentralized | Poor interpretability, rigid roles, fragile generalization |
| LLM-only (e.g. CoNavGPT, DITTO) | Strong task understanding | No exploration, stuck in local optima, fixed reasoning logic |
RALLY combines the best of both:
- LLM for semantic intent and explainable planning
- MARL (via RMIX) for credit assignment and online learning
RMIX: Where Roles Earn Their Keep
A key innovation is the Role-value Mixing Network (RMIX):
- Trains agents to select the role (Commander, Coordinator, Executor) that yields the best long-term return.
- Uses monotonic value decomposition to ensure consistent credit assignment.
- Bootstrapped with GPT-4o-generated offline role suggestions, then fine-tuned online.
This resolves the classic MARL dilemma: agents can now both explore and explain their behavior.
Tiny Models That Think Big
Deploying GPT-4o directly is impractical for UAVs. RALLY solves this by fine-tuning lightweight models (like Qwen2.5-1.5B) via instruction distillation:
- Generates a dataset of 8,231 LLM-guided decisions using GPT-4o
- Filters and uses these to fine-tune a 1.5B LoRA model
- Compresses inference footprint to under 5GB, enabling distributed, onboard reasoning
The result? Near-GPT-quality planning at edge-device latency.
Generalization Under Pressure
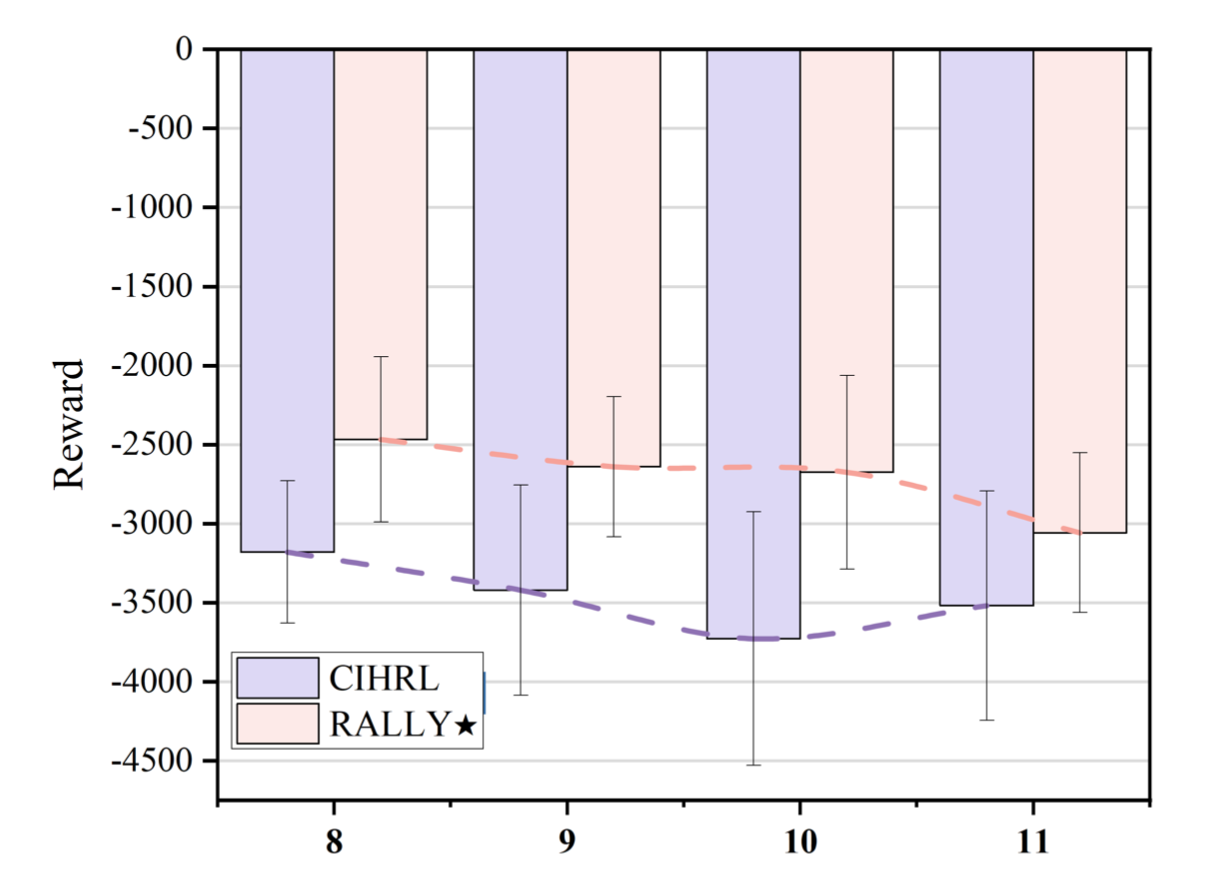
In experiments on both MPE and PX4 SITL environments, RALLY consistently outperformed state-of-the-art methods:
- Higher reward and lower variance across episodes
- Maintained coordination even as swarm size increased from 8 to 11
- Adapted roles in real-time under enemy pursuit and obstacle disruption
Critically, adding too many roles (e.g. Decoy) hurt performance—underscoring that effective heterogeneity is about balance, not complexity.
Real Swarms, Real Decisions
The paper’s most impressive contribution may be its realism. RALLY is validated in a high-fidelity Gazebo-ROS-PX4 SITL setup:
- Each UAV runs an independent offboard LLM/MARL agent
- Communication is localized; decisions are distributed
- Enemy UAVs pursue clusters; obstacles interfere with paths
One scenario shows a Coordinator UAV deliberately intercepting an enemy to protect a forming cluster—a decentralized, emergent behavior that mirrors tactical sacrifice.
The Takeaway for Industry
RALLY is not just a step forward for UAV swarms. It’s a blueprint for agentic AI collaboration:
- Semantic prompting replaces brittle numeric protocols
- Lightweight LLMs bridge local understanding with global coordination
- Roles become contextually assigned, not hardcoded
In warehouse robots, autonomous fleets, or emergency response drones, dynamic task allocation and consensus-building are central challenges. RALLY offers a model where agents can reason, adapt, and align—all in real-time.
Cognaptus: Automate the Present, Incubate the Future