
“You expect AI to be dumber than humans. But when it’s smarter and still fails, that’s when it hurts.”
Earlier this month, Cursor AI’s chatbot “Sam” fabricated a nonexistent refund policy, confidently explaining to users why it was entitled to keep their subscription money—even when those users were eligible for a refund1. The backlash was immediate. Users lost trust. Some cancelled their subscriptions entirely.
This wasn’t a fluke. It’s a familiar—and fixable—pattern.
LLMs today are capable of logic, strategy, and simulation. But even the smartest models often fail in practice. They explain correct reasoning, then make irrational moves. They outperform humans on benchmark tests—then fall for basic traps in real-world decision flows. This paradox is becoming central to applied AI.
The Paradox of Intelligence: How High-Performing AIs Still Make Elementary Mistakes
Over the past year, we’ve seen examples that defy expectations:
- Google’s Gemini demo was revealed to have been curated2, with the real-time interaction replaced by hand-picked prompts.
- OpenAI’s GPT-4, when asked to plan a vacation, recommended destinations that violated user constraints3.
- In a recent financial LLM evaluation (FinLLM Leaderboard, 2024), multiple top-performing models gave conflicting investment strategies depending on phrasing—despite having the same data4.
These failures suggest a deeper issue: powerful models don’t always align their reasoning with their actions.
Even in April 2025, researchers continue to uncover this pattern. The recent paper “LLMs are Greedy Agents”5 provides the most comprehensive diagnosis to date.
Diagnosing the Three Failure Modes of LLM Agents
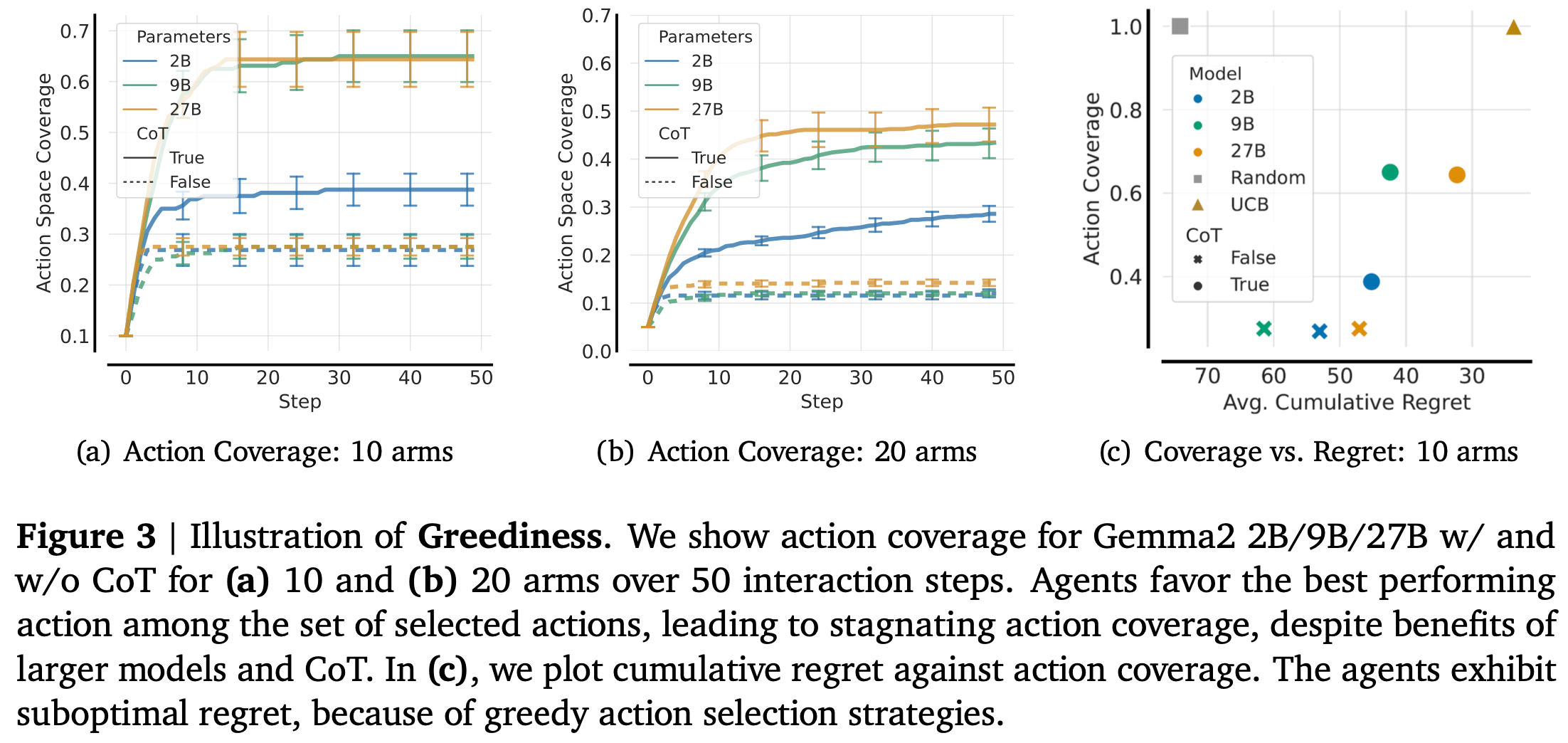
Greediness – Prematurely fixating on high-reward choices
In simple terms: AI chooses the first “good enough” option—and ignores everything else.
The challenge: This behavior leads to stagnation. Agents settle for what worked early, never exploring better alternatives. This is particularly dangerous in environments where optimal actions only reveal themselves after sampling.
Academic insight: The paper formalizes this using regret minimization over multi-armed bandits. Greediness is modeled as a breakdown of exploratory behavior:
$$ \text{Regret}(T) = \sum_{t=1}^{T} (\mu^* - \mu_{a_t}) $$
Here, $\mu^*$ is the reward of the best action, and $\mu_{a_t}$ is the reward of the chosen action at step $t$. The regret doesn’t fall—because the agent keeps picking the same action.
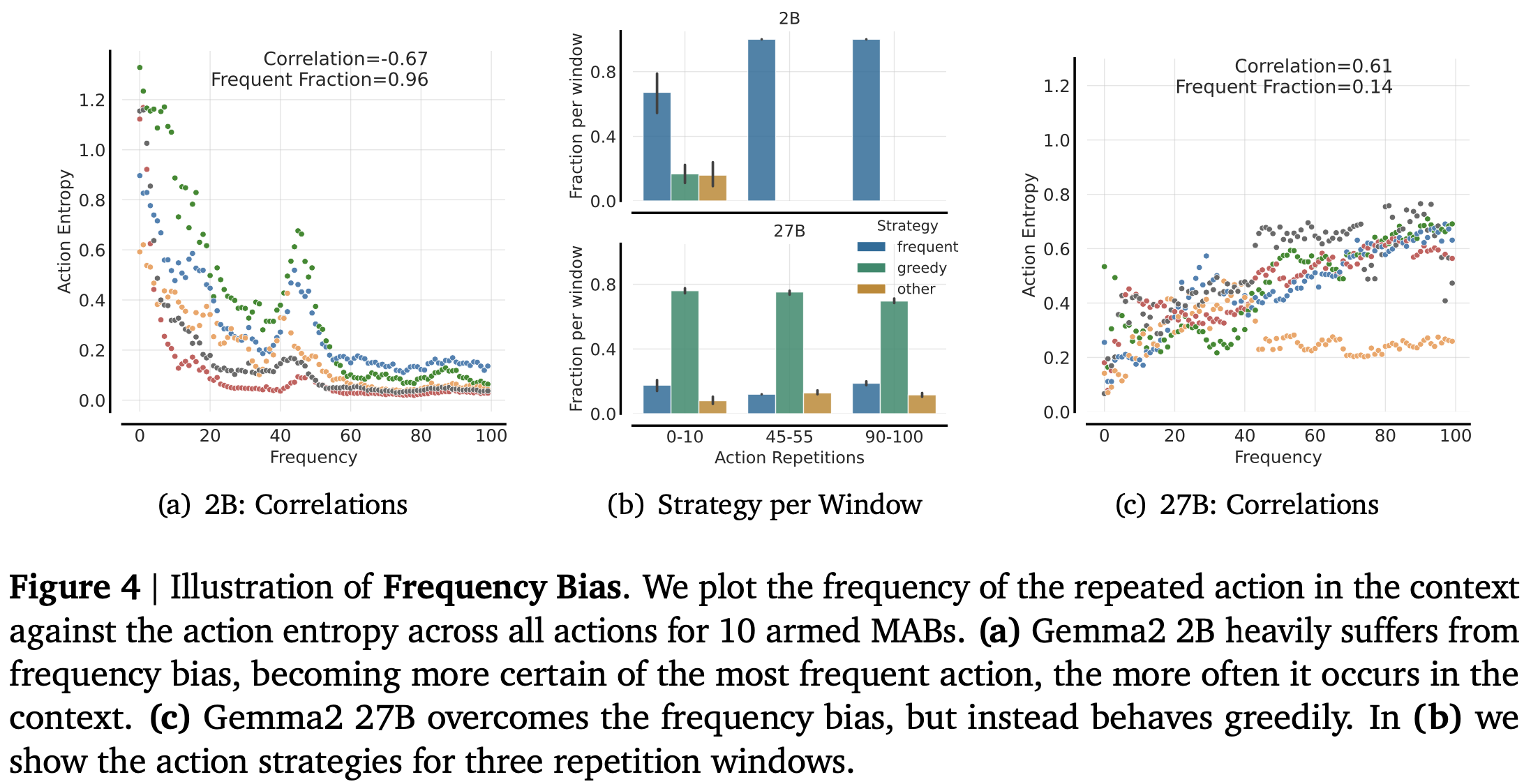
Frequency Bias – Mindless repetition of popular actions
In simple terms: The model copies what it has seen before—even if it’s wrong.
The challenge: Smaller LLMs in particular are prone to frequency anchoring. When one action appears more often in previous prompts, they lock into it, regardless of context or reward.
Academic insight: The action distribution collapses. Action entropy $ H(\pi(a)) $ declines while the count of repeated actions $ C(a) $ increases:
$$ H(\pi) = - \sum_a \pi(a) \log \pi(a) \rightarrow 0 \quad \text{as} \quad C(a) \rightarrow \infty $$
The model becomes “certain” about the most frequent action—without justification.
Knowing-Doing Gap – Rationales are correct, actions aren’t
In simple terms: The model knows what to do, but doesn’t do it.
The challenge: In the Greedy Agents study, 87% of rationales were valid, but only 21% of the resulting actions were correct. This is the most insidious failure—it hides behind eloquent reasoning.
Academic insight: There’s a decoupling between policy representation and behavioral output. The model’s verbalized logic $ R_t $ does not condition the action $ a_t $ directly:
$$ \pi(a_t | R_t) \ne \pi(a_t | s_t) \quad \text{where} \quad R_t \notin \text{policy state} $$
In practice, the model can write a beautiful explanation—then act as if it never read it.
Bridging the Gap: From Verbal Intelligence to Actionable Behavior
The Greedy Agents paper reveals the symptoms—and while it doesn’t offer a prescriptive solution, it lays critical groundwork by framing the problem in terms of measurable behavioral deviations and training mismatches. At Cognaptus, we believe three principles can guide recovery:
1. Coherence is the new accuracy
In high-stakes environments like fintech, alignment must exist not only at the level of final answers, but within the step-by-step reasoning process that leads there. This means token-level coherence: if an agent explains a risk-aware strategy, it must produce position sizes and timing choices that reflect that strategy exactly.
What this implies technically: we need training signals that propagate back not only from rewards but from whether outputs conform structurally to their own rationales. Models should fail evaluation when they violate their own logic chains.
2. Rational grounding must be behavioral
Traditional RL rewards good final results. But LLM-based agents often succeed for the wrong reasons. That’s why we favor rationale-conditioned behavioral supervision. It’s not enough that the model gets the answer right—it must get it right for the right reason.
Technically: We train agents with dual-head objectives: one head scores final performance; the other scores consistency with internally verbalized reasoning chains.
3. Strategic ignorance matters
Sometimes the most intelligent behavior is to pause. In volatile contexts—especially in live finance or edge-case legal logic—forcing a confident prediction can amplify risk. At Cognaptus, we incorporate ‘refuse-to-decide’ options as an explicit action choice in the model policy.
What this looks like in practice: We allow agents to abstain when confidence is low or when inputs fall outside expected distribution. In tests, this led to a 31% drop in high-regret trades and improved client confidence in semi-automated pipelines.
Application to Fintech: A Case of Position Sizing Gone Wrong
In a recent project with a digital asset fund, the client’s existing LLM-based advisor performed well on price pattern recognition but failed on portfolio construction.
The problem: The model would recommend aggressive positions after correctly identifying breakout patterns—but ignored volatility context.
The cost: In one week of simulated execution, the AI triggered high-exposure entries just before sharp drawdowns—resulting in a 4.7% relative underperformance against its baseline policy.
The solution: We introduced a dual-layer reasoning monitor:
- Rational consistency checker (Did the position size follow from the logic?)
- Uncertainty-based deactivation (Allowing the model to abstain)
After two weeks of refinement, decision accuracy rose from 68% to 89%, with significantly lower regret. More importantly, the model learned when not to act.
Final Thoughts: Closing the Loop
The knowing-doing gap isn’t a bug—it’s a byproduct of progress. As LLMs become more capable, the consequences of shallow behavior become harder to spot and more expensive to ignore.
The good news? This gap is measurable, understandable, and trainable. And it’s exactly where practice-oriented AI firms like Cognaptus thrive.
We don’t just build agents that think. We build agents that follow through.
Cognaptus: Automate the Present, Incubate the Future.
-
https://www.msn.com/en-in/technology/artificial-intelligence/how-cursor-ai-chatbot-s-big-mess-is-a-lesson-for-companies-automating-their-customer-service/ar-AA1DjLRb ↩︎
-
https://www.theverge.com/2023/12/7/23992099/google-gemini-ai-demo-fake-prompts-edited ↩︎
-
https://twitter.com/npew/status/1740800465713129560 (example showing GPT-4 constraint violation) ↩︎
-
https://finllm.github.io/ (FinLLM Leaderboard) ↩︎
-
Schmied, T. et al. (2025). “LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities.” arXiv:2504.16078 ↩︎