
Cut the Fluff: Leaner AI Thinking
When it comes to large language models (LLMs), brains aren’t the only thing growing—so are their waistlines. As AI systems become increasingly powerful in their ability to reason, a hidden cost emerges: token bloat, high latency, and ballooning energy consumption.
One of the most well-known methods for boosting LLM intelligence is Chain-of-Thought (CoT) reasoning. CoT enables models to break down complex problems into a step-by-step sequence—much like how humans tackle math problems by writing out intermediate steps. This structured thinking approach, famously adopted by models like OpenAI’s o1 and DeepSeek-R1 (source), has proven to dramatically increase both performance and transparency.
Originally introduced as a prompt-only technique (early OpenAI reference), CoT eventually influenced how models were trained—embedding reasoning structure directly into model capabilities.
But here’s the rub: CoT is computationally hungry. Every thought step adds tokens. More tokens mean more time, more power, more dollars. Great for accuracy, not so great for efficiency.
Atom of Thoughts: One Step at a Time
Atom of Thoughts (AoT) is more than a prompting strategy—it is a test-time reasoning framework designed to transform how LLMs decompose and solve tasks. It introduces a Markov-style reasoning paradigm, where each step (or “atom”) depends only on the present subproblem—not on the entire history of reasoning.
Each task is structured as a Directed Acyclic Graph (DAG) of subquestions:
- Independent subquestions are solved in isolation.
- Dependent subquestions are contracted and reformulated as the task evolves.
This process consists of two cycles:
- Decomposition: breaking the question into smaller, manageable pieces.
- Contraction: solving and merging results into a simplified state.
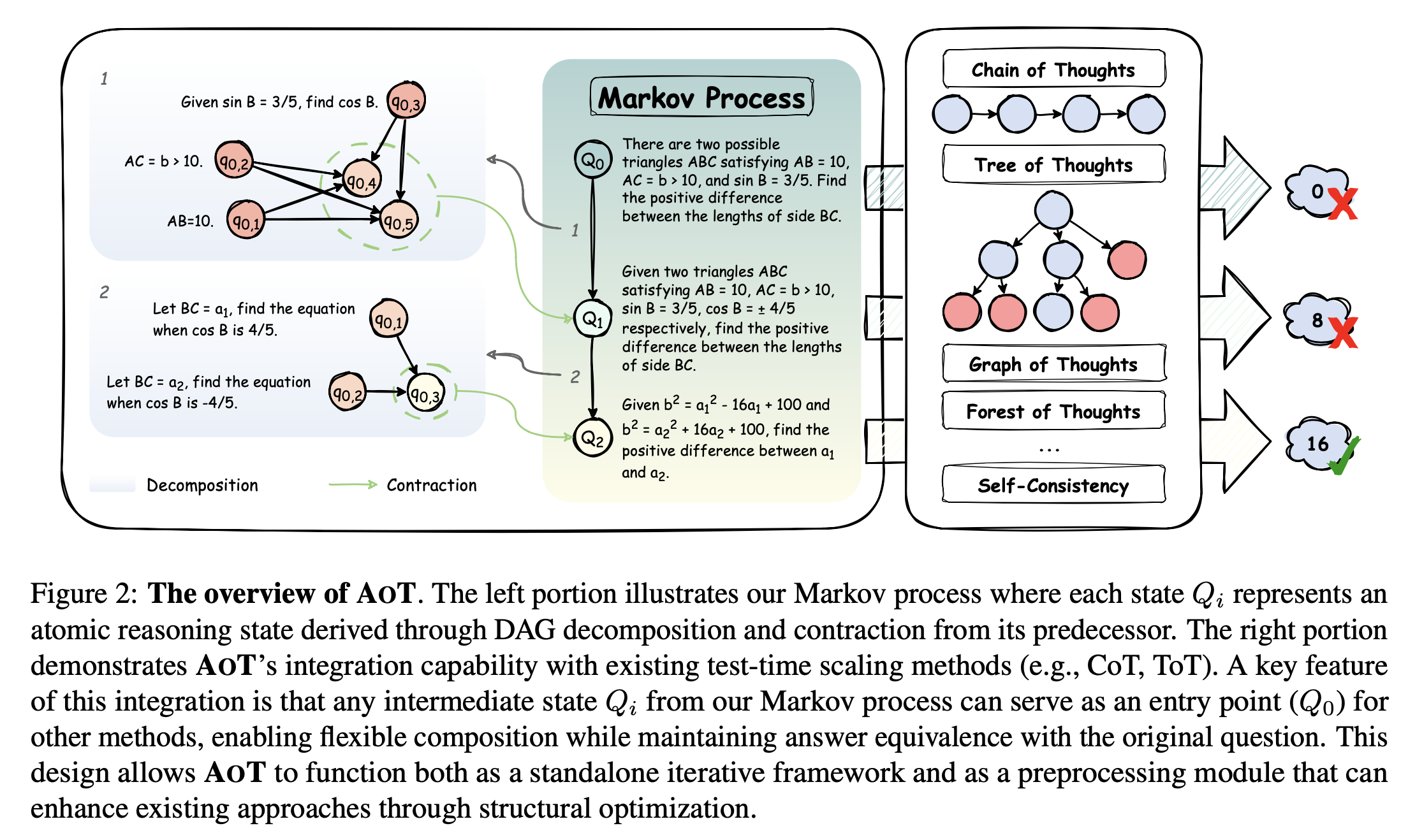
As shown in Figure 2 (Page 2, Teng et al., arXiv:2502.12018), AoT’s DAG and contraction structure enables localized, atomic reasoning without accumulating historical baggage.

The step-by-step process is further defined in Algorithm 1 (Table 1, Page 5). After this table, it’s important to emphasize that AoT is designed not for prompting alone, but for plug-and-play integration with reasoning agents. It supports modular composition, making it suitable for tools requiring recursive reasoning, such as customer analytics pipelines, multi-step form validation, or troubleshooting flows in business automation.
In practice, using AoT means breaking a client’s workflow query (e.g., “Why are our northern region sales down?”) into self-contained atoms like:
- “What are this quarter’s northern region sales figures?”
- “What were they last quarter?”
- “What products saw the largest change?”
Each of these can be independently processed by the LLM, and then contracted into a larger insight, such as a markdown summary or CRM flag.
Chain of Draft: Think Brief, Not Loud
Chain of Draft (CoD) rethinks CoT by embracing minimalistic reasoning—just like how humans scribble fast drafts on the side while solving problems.
Instead of verbose, step-by-step explanations, CoD encourages the LLM to:
- Capture only critical reasoning insights
- Limit outputs to ~5 words per step
- Abstract irrelevant context
In tests across reasoning tasks like arithmetic (GSM8k), commonsense (BIG-bench), and symbolic logic (coin flips), CoD achieved:
- Up to 92.4% fewer tokens than CoT
- Up to 76.2% latency reduction
- Comparable or even better accuracy in many tasks
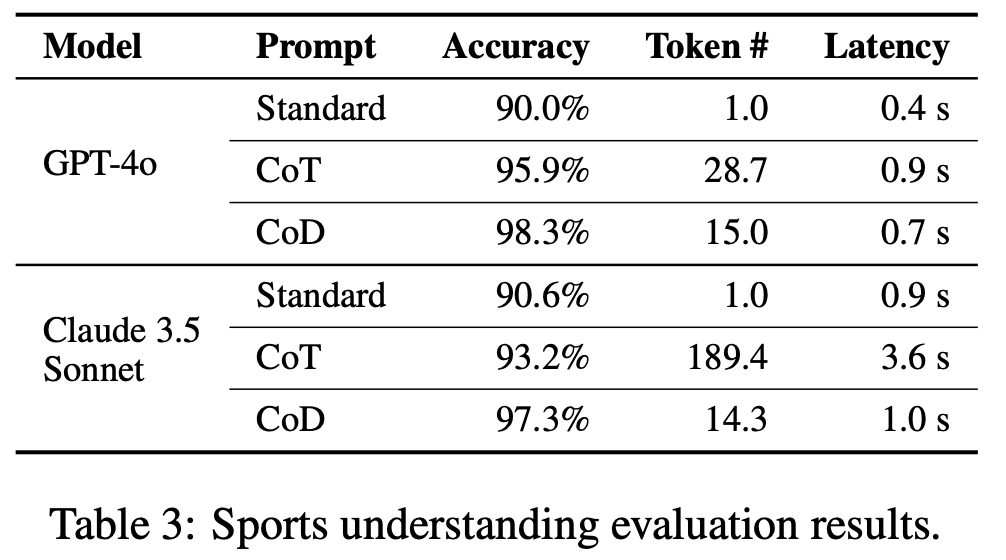
As shown in Table 3 (Page 5, Xu et al., arXiv:2502.18600), CoD significantly reduces token usage and latency while maintaining strong performance.
Why This Matters: Cognaptus Case
At Cognaptus, many of our small-firm clients use LLMs to generate marketing copy, competitive insights, or data narratives within budget-constrained web apps.
In Q1 2025, we found that:
- CoT prompts increased API costs by 4–5x relative to baseline prompting.
- Average latency per generated report reached 4–6 seconds, hurting user experience.
After switching to CoD-formatted prompting in one of our tools, we:
- Reduced average output latency to 1.5 seconds
- Lowered token usage by over 70%
- Cut API expenses by 38% in a single billing cycle
Here’s what a CoD-formatted chain might look like in a real client scenario:
- Prompt: “Compare competitor price trends last 3 months”
- Draft Steps:
- Fetch competitor SKUs
- Extract price points by month
- Calculate change per SKU
- Average across product groups
- Output summary #### “Avg price up 8.2%”
By enforcing this terse, efficient thought structure, Cognaptus helps clients keep both latency and cost under control while still supporting business-critical automation.
We’re now evaluating AoT for CRM-related analytics modules that require modular and recursive reasoning. Its minimal memory footprint and composable design show promise in keeping reasoning efficient across chains of sub-insights.
The Future: Think Light, Think Smart
As AI continues its march into real-world applications—education, finance, operations—the cost and speed of response become non-negotiable.
With methods like AoT and CoD, we are witnessing the next evolution of model prompting: from verbose to efficient, from weighty to agile.
So the next time your AI assistant solves a problem without rambling—thank its reasoning diet.
Cognaptus Insights is your guide to smarter, leaner AI systems. Want more? Visit us at cognaptus.com or follow us for weekly deep dives into the minds of machines.