
📺 Watch this first: Jimmy O. Yang on “Guess How Much”
“Because the art is in the savings — you never pay full price.”
💬 “Guess How Much?” — A Philosophy for AI Developers
In his stand-up comedy, Jimmy O. Yang jokes about how Asian families brag not about how much they spend, but how little:
“Guess how much?”
“No — it was $200!”
It’s not just a punchline. It’s a philosophy. And for developers building LLM-powered applications for small businesses or individual users, it’s the right mindset.
While others chase the flashiest model, savvy devs optimize for cost-effectiveness — spending just enough to deliver value, and not a dollar more.
💸 AI API Pricing Summary
Let us check the price of some popular LLM APIs first.
All these numbers are fetched by Cognaptus Insights on Mar 30, 2025.
Note: “N/A” = Free unless otherwise noted. Batch discounts of 50–75% apply.
Source links:
Gemini | OpenAI | Claude | DeepSeek
| Provider | Model | Input ($/1M tokens) | Output ($/1M tokens) | Caching / Context ($/1M tokens or per hour) | Fine-Tuning ($/1M tokens) | Notes |
|---|---|---|---|---|---|---|
| Gemini | 2.0 Flash | $0.10 (text/img/vid), $0.70 (audio) | $0.40 | $0.025 (text/img/vid), $0.175 (audio); $1/hr storage | N/A (Free) | Starts Mar 31, 2025 |
| 2.0 Flash-Lite | $0.075 | $0.30 | Starts Mar 31, 2025 | N/A (Free) | Compact/low-cost model | |
| 1.5 Flash | $0.075 (≤128k), $0.15 (>128k) | $0.30 (≤128k), $0.60 (>128k) | $0.01875 / $0.0375; $1/hr storage | Free tuning service | 1M token context | |
| 1.5 Flash-8B | $0.0375 (≤128k), $0.075 (>128k) | $0.15 (≤128k), $0.30 (>128k) | $0.01 / $0.02; $0.25/hr storage | Free tuning service | Lower intelligence variant | |
| 1.5 Pro | $1.25 (≤128k), $2.50 (>128k) | $5.00 (≤128k), $10.00 (>128k) | $0.3125 / $0.625; $4.50/hr storage | Not available | Highest IQ; 2M token context | |
| Imagen 3 | N/A (Not Free) | $0.03 per image | N/A (Not applicable) | N/A | Image generation only | |
| Gemma 3 | N/A (Free) | N/A (Free) | Free | N/A | Open lightweight model | |
| Text Embedding 004 | N/A (Free) | N/A (Free) | N/A | N/A | Embedding model only | |
| OpenAI | o1 (Frontier) | $15.00 / $7.50 (cached) | $60.00 | Cached input: $7.50 | - | 200k context, tools + vision |
| o3-mini | $1.10 / $0.55 (cached) | $4.40 | Cached input: $0.55 | - | Cost-effective reasoning | |
| GPT-4.5 | $75.00 / $37.50 (cached) | $150.00 | Cached input: $37.50 | - | Research preview | |
| GPT-4o | $2.50 / $1.25 (cached) | $10.00 | Cached input: $1.25 | Input: $3.75, Output: $15, Train: $25 | General-purpose AI | |
| GPT-4o mini | $0.15 / $0.075 (cached) | $0.60 | Cached input: $0.075 | Input: $0.30, Output: $1.20, Train: $3.00 | Fast, affordable | |
| Claude | 3.7 Sonnet | $3.75 | $15.00 | $0.30 write / $15 read | - | Most intelligent Claude model |
| 3.5 Haiku | $1.00 | $4.00 | $0.08 write / $4 read | - | Fast, cost-effective | |
| 3 Opus | $18.75 | $75.00 | $1.50 write / $75 read | - | Most powerful | |
| 3.5 Sonnet (Legacy) | $3.75 | $15.00 | $0.30 write / $15 read | - | - | |
| 3 Haiku (Legacy) | $0.30 | $1.25 | $0.03 write / $1.25 read | - | - | |
| DeepSeek | chat (V3) | $0.27 miss / $0.07 hit | $1.10 | - | - | 64k context, off-peak = cheaper |
| reasoner (R1) | $0.55 miss / $0.14 hit | $2.19 | - | - | 32k CoT support | |
| chat (off-peak) | $0.135 miss / $0.035 hit | $0.55 | - | - | 50% off (UTC 16:30–00:30) | |
| reasoner (off-peak) | $0.135 miss / $0.035 hit | $0.55 | - | - | 75% off (UTC 16:30–00:30) |
💡 Batch processing mode is supported on most platforms and can dramatically reduce cost for async use cases.
📊 Let Us See a More Intuitive Chart to Compare Price
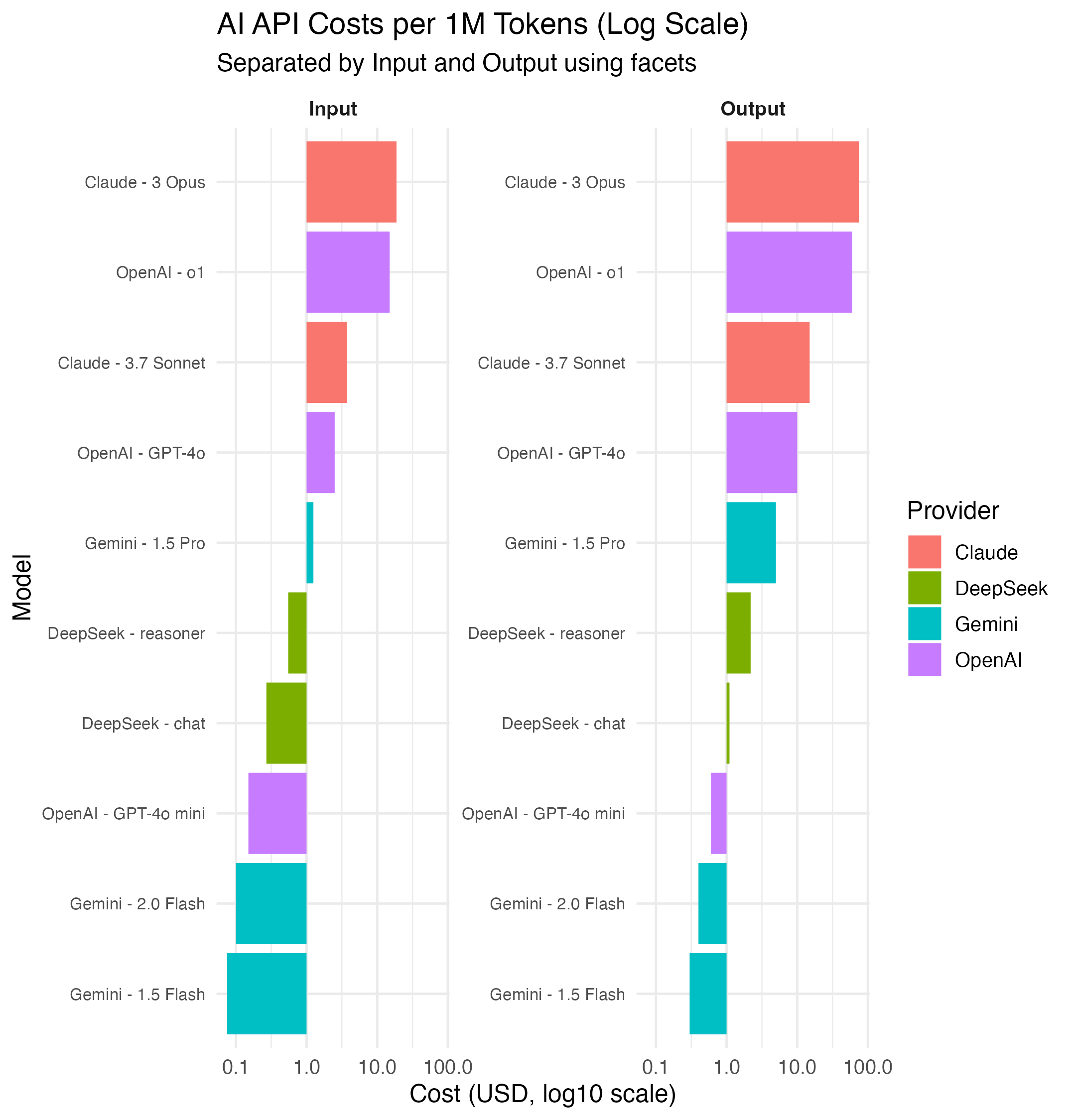
This chart breaks down input vs output costs across popular models using a logarithmic scale to emphasize price gaps.
- 🟢 Input = sending prompts
- 🔵 Output = model responses
- 🟠 Massive disparity: GPT-4.5 can be over 100x more expensive than something like GPT-4o mini or Gemini Flash
🤔 So yes — “Guess how much?” should be a developer reflex too.
🧠 But Wait… Cheap Models = Low Quality?
That’s a valid concern. And to some extent, yes — lower-cost models tend to perform worse on complex tasks.
Let’s look at the latest rankings from two independent sources:
🏆 LLM Arena Leaderboard (User Votes)
| Rank (UB) | Rank (StyleCtrl) | Model | Arena Score | 95% CI | Votes | Organization | License |
|---|---|---|---|---|---|---|---|
| 1 | 1 | Gemini-2.5-Pro-Exp-03-25 | 1443 | +11/-8 | 3474 | Proprietary | |
| 2 | 2 | ChatGPT-4o-latest (2025-03-26) | 1408 | +11/-12 | 2676 | OpenAI | Proprietary |
| 2 | 4 | Grok-3-Preview-02-24 | 1404 | +6/-6 | 10397 | xAI | Proprietary |
| 2 | 2 | GPT-4.5-Preview | 1398 | +6/-7 | 10907 | OpenAI | Proprietary |
| 5 | 7 | Gemini-2.0-Flash-Thinking-Exp-01-21 | 1381 | +4/-5 | 22987 | Proprietary | |
| 5 | 4 | Gemini-2.0-Pro-Exp-02-05 | 1380 | +5/-4 | 20289 | Proprietary | |
| 7 | 5 | DeepSeek-R1 | 1360 | +5/-4 | 13074 | DeepSeek | MIT |
| 7 | 12 | Gemini-2.0-Flash-001 | 1355 | +6/-4 | 18650 | Proprietary | |
| 7 | 4 | o1-2024-12-17 | 1351 | +5/-4 | 25363 | OpenAI | Proprietary |
| 10 | 12 | Qwen2.5-Max | 1340 | +5/-5 | 17452 | Alibaba | Proprietary |
| 10 | 12 | Gemma-3-27B-it | 1339 | +7/-5 | 7238 | Gemma | |
| 10 | 9 | o1-preview | 1335 | +4/-3 | 33188 | OpenAI | Proprietary |
| 12 | 12 | o3-mini-high | 1326 | +6/-5 | 14587 | OpenAI | Proprietary |
| 13 | 15 | DeepSeek-V3 | 1318 | +5/-4 | 22842 | DeepSeek | DeepSeek |
| 13 | 19 | QwQ-32B | 1315 | +9/-8 | 4366 | Alibaba | Apache 2.0 |
🏆 Gemini-2.5-Pro, GPT-4o, and DeepSeek R1 dominate — but lower-cost models are rising fast in user preference.
🧪 SEAL Exam: Multi-Step Reasoning Accuracy
The SEAL Humanity Exam shows how well models handle multi-step human-level reasoning:
| Model | Accuracy (%) | 95% CI |
|---|---|---|
| Gemini 2.5 Pro Experimental (Mar 2025) | 18.57 | +1.57 / -1.57 |
| o3-mini (high)** | 13.97 | +1.40 / -1.40 |
| o3-mini (medium)** | 11.10 | +1.26 / -1.26 |
| Claude 3.7 Sonnet Thinking (Feb 2025)** | 8.61 | +1.13 / -1.13 |
| DeepSeek-R1 | 8.57 | +1.13 / -1.13 |
| o1 (Dec 2024)* | 8.35 | +1.11 / -1.11 |
| Gemini 2.0 Flash Thinking (Jan 2025) | 7.05 | +1.03 / -1.03 |
| Gemini 2.0 Pro Experimental (Feb 2025) | 6.67 | +1.00 / -1.00 |
| GPT-4.5 Preview (Feb 2025)** | 6.58 | +1.00 / -1.00 |
| Llama 3.2 90B Vision Instruct | 5.53 | +0.92 / -0.92 |
| DeepSeek V3 (Mar 2025) | 5.23 | +0.90 / -0.90 |
| Gemini-1.5-Pro-002* | 5.15 | +0.89 / -0.89 |
| Gemini 2.0 Flash Experimental (Dec 2024) | 4.89 | +0.87 / -0.87 |
| Gemini 2.0 Flash** | 4.89 | +0.87 / -0.87 |
| Claude 3.5 Sonnet (Oct 2024)* | 4.85 | +0.86 / -0.86 |
| Claude 3.7 Sonnet (Feb 2025)** | 4.81 | +0.86 / -0.86 |
| Qwen2-VL-72B-Instruct | 4.73 | +0.85 / -0.85 |
| Gemini 2.0 Flash-Lite (Feb 2025)** | 4.43 | +0.83 / -0.83 |
| o1-mini* | 4.05 | +0.79 / -0.79 |
| Claude 3 Opus | 3.97 | +0.79 / -0.79 |
| Gemini-1.5-Flash-002 | 3.84 | +0.77 / -0.77 |
| GPT-4o (Nov 2024)* | 2.62 | +0.64 / -0.64 |
🤖 Even modest performers like o3-mini or DeepSeek V3 punch above their price class when prompted well.
⚙️ Cheap Is Low Quality — To Some Extent — But We Have Remedies
Yes, raw intelligence and accuracy might be lower on cheap models.
But unlike watches or cars, AI outputs are highly engineerable.
With clever engineering and well-designed prompts, you can close the gap — sometimes significantly — and even beat expectations.
Here’s how:
🧠 Prompting + Retry: The Budget Developer’s Secret Weapon
Prompt engineering isn’t a buzzword. It’s a core strategy for getting quality output from mid-range or even low-end models.
Here are the top tactics, with real examples:
1. 📐 Structured Prompts: Give the Model a Script
Bad Prompt:
Explain inflation.
Better Prompt:
In 3 short paragraphs, explain inflation to a high school student. Start with a definition, then give a historical example, and finish with how it affects daily life. Use friendly, simple language.
The more structure you provide, the less creative burden you leave to the model — which is crucial if it’s not a GPT-4-level genius.
2. ♻️ Multi-Pass Inference: Try 3, Keep the Best
Run the same prompt 2–3 times and choose the best result.
Example:
results = [llm.generate(prompt) for _ in range(3)]
best = choose_best(results)
This approach smooths over randomness and catches hallucinated or illogical responses. Combine with fast models like GPT-4o mini or DeepSeek chat (off-peak) and you’ll still save massively.
- 🧠 Chain of Thought: Teach the Model to Think Step-by-Step
Example Prompt:
You are a math teacher. Explain the problem step-by-step before giving the final answer: If John has 4 apples and gives away 1 to each of his 3 friends, how many does he have left?"
Even cheaper models often perform far better with step-by-step prompting than when directly asked for answers.
- 🧩 Prompt Templates for Consistency Create reusable templates for use cases like summaries, reviews, or extractions:
Example Template:
Summarize the following customer review into 3 bullet points:
“{insert_review_text}”
Keep your prompt stable, just update the content block. This works great for batch tasks.
- ⚙️ Use Simple Post-Processing to Patch Imperfect Output Even if the model’s grammar isn’t perfect or a fact is slightly off, you can:
-
Run spelling or grammar checks on output
-
Filter based on keywords or length
-
Validate facts with secondary lightweight models
While simple prompt tweaks may work for hobbyists, Cognaptus applies these principles professionally through a structured, repeatable architecture tailored for small firm needs.
Not Just Hacks — a Systemized Strategy by Cognaptus
🧰 1. Prompt Blueprints by Use Case
We maintain a tested library of domain-specific prompt templates for:
- CRM & client support
- E-commerce product content
- Form automation & data cleanup
- Internal documentation & summarization
✅ Example: A real estate CRM prompt designed for summarizing buyer preferences from call logs was optimized over 15 iterations — cutting hallucinations by 72% on Gemini 1.5 Flash.
🔁 2. Smart Retry Engine (SRE)
Unlike basic retry loops, our Smart Retry Engine includes:
- Conditional retries only on output failure
- Quality-based output ranking (length, structure, content)
- Async orchestration for batch jobs at minimal delay
💡 In a batch of 10,000 summaries, retry costs added just 12% — while reducing human QA hours by 40%.
🧩 3. Modular Prompt Wrappers
We wrap prompts in structured control modules:
- Context Guards to trim noisy inputs
- Regex Validators to enforce structure
- Secondary cleanup via low-cost models (e.g., DeepSeek or Claude Haiku)
🧠 This lets us chain models for output shaping — not just answering — while minimizing total API spend.
📊 4. Monitoring + Cost Dashboard
Every client deployment includes access to a live dashboard showing:
- Per-task cost tracking by model
- Quality score trends (human-in-the-loop + automatic evals)
- Retry rates and failure diagnostics
🔍 Clients don’t just get access to AI. They get accountable AI.
🧱 5. Custom Middleware for Smart Routing
For larger clients, Cognaptus can provide:
- Model routing (try cheap first, fallback to better)
- Semantic caching to avoid recharges
- Local fallback logic or serverless queue runners
⚙️ This gives small teams access to enterprise-grade orchestration at startup-friendly costs.
💡 The Real Flex Is in the Engineering You don’t always need a $5,000 LLM. A $200 model, prompted right, might do 95% of the job.
So next time you brag about your AI stack, channel Jimmy’s mom:
“Guess how much?” “No, it was $0.15 per million tokens!”
Want to build smart, cost-efficient AI systems? 👉 Visit Cognaptus.com — where engineering meets strategy.